4. 编译和调试
4.1. 离线编译和静态运行
4.1.1. Makefile编译和示例
以图 4.1 所示的项目文件目录为例:

图 4.1 一个简单的MXMACA源代码项目文件目录
//a.cpp:
#include <mc_runtime.h>
#include <string.h>
extern "C" __global__ void vector_add(int *A_d, size_t num)
{
size_t offset = (blockIdx.x * blockDim.x + threadIdx.x);
size _t stride = blockDim.x * gridDim.x;
for (size_t i = offset; i < num; i += stride) {
A_d[i]++;
}
}
void func_a()
{
size_t arrSize = 100;
mcDeviceptr_t a_d;
int *a_h = (int *)malloc(sizeof(int) * arrSize);
memset(a_h, 0, sizeof(int) * arrSize);
mcMalloc(&a_d, sizeof(int) * arrSize);
mcMemcpyHtoD(a_d, a_h, sizeof(int) * arrSize);
vector_add<<<1, arrSize>>>(reinterpret_cast<int *>(a_d), arrSize);
mcMemcpyDtoH(a_h, a_d, sizeof(int) * arrSize);
bool resCheck = true;
for (int i; i < arrSize; i++) {
if (a_h[i] != 1){
resCheck = false;
}
}
printf("vector add result: %s\n", resCheck ? "success": "fail");
free(a_h);
mcFree(a_d);
}
//a.h:
extern void func_a();
//b.cpp:
#include<mc_runtime.h>
__global__ void kernel_b()
{
/* kernel code*/
}
void func_b()
{
/* launch kernel */
kernel_b<<<1, 1>>>();
}
//b.h:
extern void func_b();
//main.cpp:
#include <stdio.h>
#include "a.h"
#include "b.h"
int main()
{
func_a();
func_b();
printf("my program!\n");
return 1;
}
上述工程中包含 main.cpp,a.cpp,b.cpp三个源文件,其中 a.cpp 中包含 vector_add 核函数,b.cpp 中包含 kernel_b 核函数。
若要将该工程编译成可执行文件,可按照如下方法编写Makefile文件:
# Makefile文件:
# MXMACA Compiler
MXCC = $(MACA_PATH)/mxgpu_llvm/bin/mxcc
# Compiler flags
MXCCFLAGS = -x maca
# Source files
SRCS= main.cpp src/a.cpp src/b.cpp
# Object files
OBJS = $(SRCS:.cpp=.o)
# Executable
EXEC = my_program
# Default target
all: $(EXEC)
# Link object files to create executable
$(EXEC): $(OBJS)
$(MXCC) $(OBJS) -o $(EXEC)
%.o: %.cpp
$(MXCC) $(MXCCFLAGS) -c $< -o $@ -I include
# clean up object files and executable
clean:
rm -f $(OBJS) $(EXEC)
值得注意的是,执行 make 命令之前,需要正确设置环境变量,以缺省安装位置(/opt/maca)为例:
export MACA_PATH=/opt/maca
export LD_LIBRARY_PATH=${MACA_PATH}/lib:${LD_LIBRARY_PATH}
然后在Makefile同级目录下执行 make 命令,如图 4.2 所示,就能得到可执行程序my_program。该工程中,源文件a.cpp例举了一种利用核函数实现向量加法的典型用法。
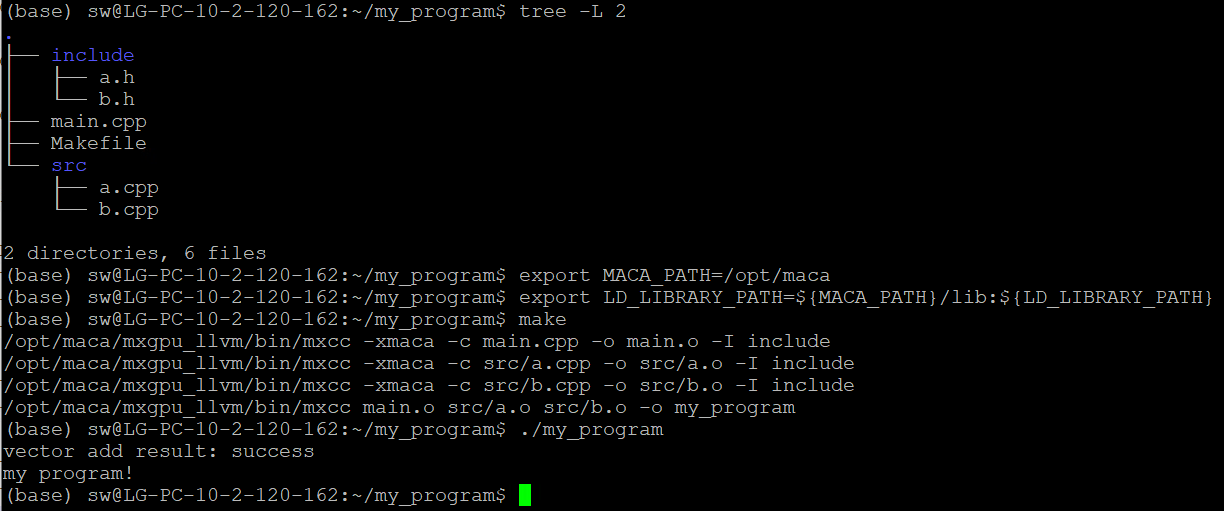
图 4.2 Makefile编译和示例
4.1.1.1. CMake编译和示例
继续以图 4.1 所示的项目结构为例,如果用cmake工具来构建项目,则需在 main.cpp 同级目录下创建 CMakeLists.txt 文件,可以按照如下方式编写 CMakeLists.txt 文件:
# Specify the minimum CMake version required
cmake_minimum_required(VERSION 3.0)
# Set the project name
project(my_program)
# Set the path to the compiler
set(MXCC_PATH $ENV{MACA_PATH})
set(CMAKE_CXX_COMPILER ${MXCC_PATH}/mxgpu_llvm/bin/mxcc)
# Set the compiler flags
set(MXCC_COMPILE_FLAGS -x maca)
add_compile_options(${MXCC_COMPILE_FLAGS})
# Add source files
File(GLOB SRCS src/*.cpp main.cpp)
add_executable(my_program ${SRCS})
# Set the include paths
target_include_directories(my_program PRIVATE include)
同理,cmake之前也需要正确设置环境变量,以缺省安装位置(/opt/maca)为例:
export MACA_PATH=/opt/maca
export LD_LIBRARY_PATH=${MACA_PATH}/lib:${LD_LIBRARY_PATH}
如图 4.3 所示,在 CMakeLists.txt 同级目录下创建 build 文件夹,进入 build 目录执行 cmake 命令,再执行 make 命令,即可得到可执行程序 my_program。
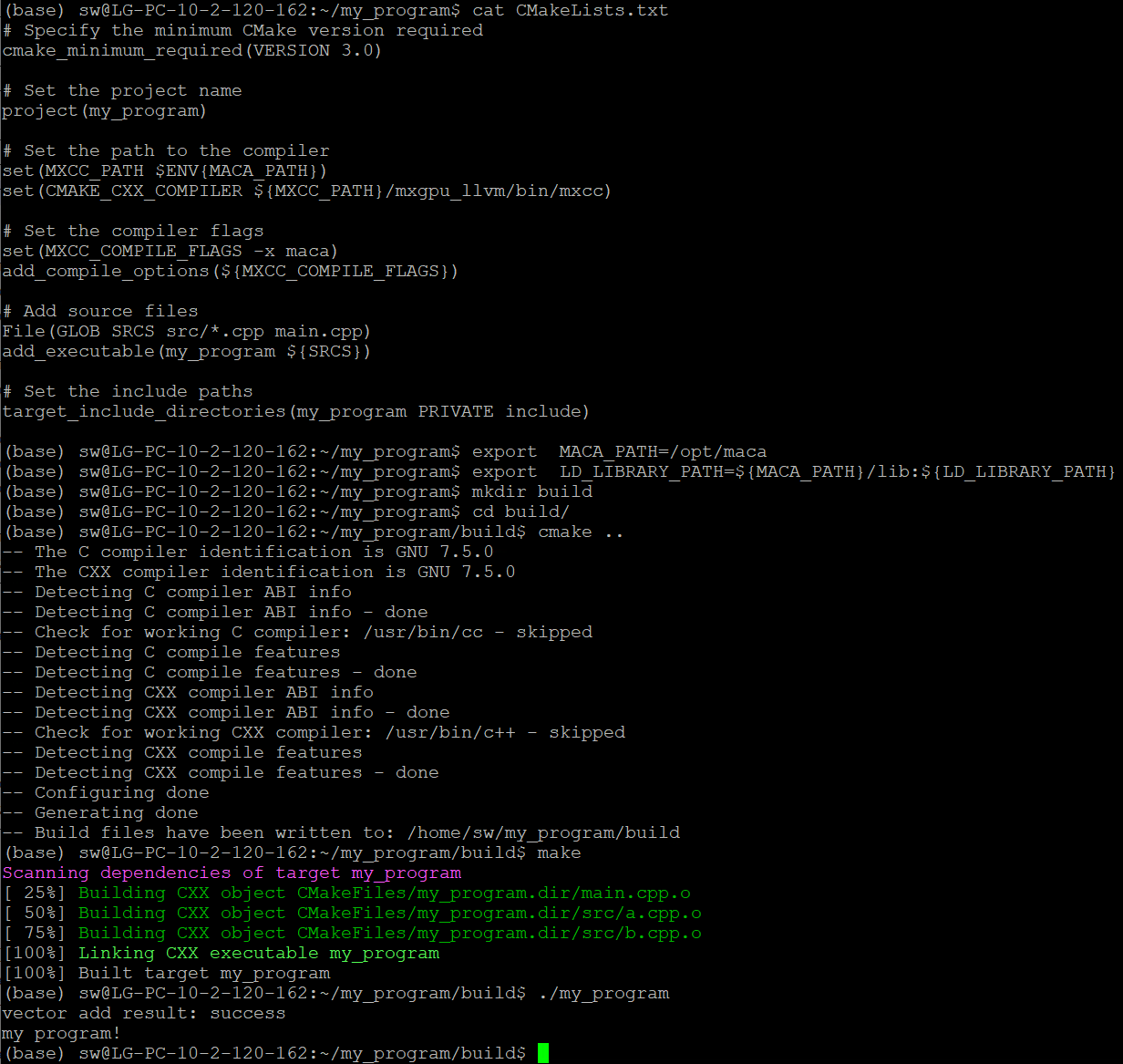
图 4.3 CMake编译和示例
4.2. 运行时编译和动态加载
曦云系列GPU支持运行时编译和动态加载功能,整个流程如图 4.4 所示。 其中运行时进行实时编译(Just-In-Time, JIT)采用了 LLVM bitcode 格式文件,有关该格式的详细内容,参见官方文档介绍。
用户在使用时通过引入头文件 mcrtc.h,即可使用MCRTC提供的所有功能:
MCRTC将原始的C++语法的MXMACA代码,通过
mcrtcGetBitCode接口编译生成 bitcode 格式的二进制代码。将生成的 bitcode 代码,通过
mcModuleLoad进行加载,曦云系列GPU的驱动(运行时库API)会继续进行后续编译并生成设备侧的可执行代码,用户在调用mcModuleLaunchKernelAPI接口的时候会将这些设备侧可执行代码送入GPU执行。
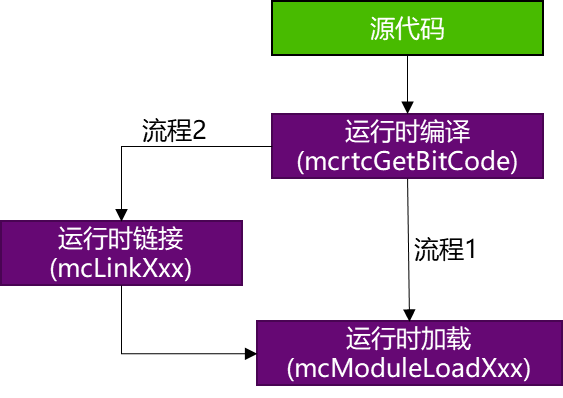
图 4.4 即时编译流程
代码示例
用户可以将device代码和host代码分别写在不同的文件中,生成可执行程序时,只编译host代码,device代码在程序运行时编译。以下介绍了这种编程范式的简单实现。
device代码写在单独的文件中:
//my_kernel.cu: extern "C" __global__ void test_kernel() { /* kernel code */ printf("my kernel\n"); }
host代码写在另外的文件中:
//host文件rtc_test.cpp: #include <fstream> #include <vector> #include<mc_runtime.h> #include<mcrtc.h> static inline std::vector<char> load_file_data(const char *filename) { std::ifstream file(filename, std::ios::binary | std::ios::ate); std::streamsize fsize = file.tellg(); file.seekg(0, std::ios::beg); std::vector<char> buffer(fsize + 1); file.read(buffer.data(), fsize); buffer[fsize] = '\x0'; file.close(); return buffer; } void rtcTest() { /* load kernel file to buffer*/ std::vector<char> buffer = load_file_data("my_kernel.cu"); /* Create an instance of mcrtcProgram */ mcrtcProgram prog; mcrtcCreateProgram( &prog, // prog (char *)&buffer[0], // buffer "", //name 0, // numHeaders NULL, //headers NULL); //includeNames const char *opts[] = {"-x maca"}; /* Compile the program */ mcrtcCompileProgram(prog, // prog 1, // numOptions opts); // options size_t codeSize; mcrtcGetCodeSize(prog, &codeSize); char *code = new char[codeSize]; /* get binary file */ mcrtcGetCode(prog, code); mcrtcDestroyProgram(&prog); mcModule_t module; mcFunction_t kernel_addr; /* load binary file to buffer */ mcModuleLoadData(&module, code); /* get kernel function point */ mcModuleGetFunction(&kernel_addr, module, "test_kernel"); /* launch kernel function */ mcModuleLaunchKernel(kernel_addr, 1, 1, 1, 1, 1, 1, 0, NULL,NULL,NULL); mcModuleUnload(module); delete[] code; } int main() { rtcTest(); return 1; }
正确设置环境变量(以缺省安装位置 /opt/maca 为例):
export MACA_PATH=/opt/maca export LD_LIBRARY_PATH=${MACA_PATH}/lib:${LD_LIBRARY_PATH} export PATH=${MACA_PATH}/mxgpu_llvm/bin:${PATH}
在源文件 rtc_test.cpp 同级目录下执行以下命令,即可得到可执行文件 a.out,如图 4.5 所示。
mxcc -x maca rtc_test.cpp
此时device代码 my_kernel.cu 并没有编译到 a.out 中,而是在运行 a.out 过程中编译该device文件。

图 4.5 可执行文件a.out获取
4.3. 代码托管(Binary Cache)
使用默认设置binary cache(cache文件保存路径以及所支持文件大小均采用默认值,无需设置环境变量)。
代码示例:
#include<mc_runtime.h>
__global__ void vectorADD(const float* A_d, const float* B_d, float* C_d, size_t NELEM) {
size_t offset = (blockIdx.x * blockDim.x + threadIdx.x);
size_t stride = blockDim.x * gridDim.x;
for (size_t i = offset; i < NELEM; i += stride) {
C_d[i] = A_d[i] + B_d[i];
}
}
int main()
{
int blocks=20;
int threadsPerBlock=1024;
int numSize=1024*1024;
float *A_d=nullptr;
float *B_d=nullptr;
float *C_d=nullptr;
float *A_h=nullptr;
float *B_h=nullptr;
float *C_h=nullptr;
mcMalloc((void**)&A_d,numSize*sizeof(float));
mcMalloc((void**)&B_d,numSize*sizeof(float));
mcMalloc((void**)&C_d,numSize*sizeof(float));
A_h=(float*)malloc(numSize*sizeof(float));
B_h=(float*)malloc(numSize*sizeof(float));
C_h=(float*)malloc(numSize*sizeof(float));
for(int i=0;i<numSize;i++)
{
A_h[i]=3;
B_h[i]=4;
C_h[i]=0;
}
mcMemcpy(A_d,A_h,numSize*sizeof(float),mcMemcpyHostToDevice);
mcMemcpy(B_d,B_h,numSize*sizeof(float),mcMemcpyHostToDevice);
vectorADD<<<dim3(blocks),dim3(threadsPerBlock)>>>(A_d,B_d,C_d,numSize);
mcMemcpy(C_h,C_d,numSize*sizeof(float),mcMemcpyDeviceToHost);
mcFree(A_d);
mcFree(B_d);
mcFree(C_d);
free(A_h);
free(B_h);
free(C_h);
return 0;
}
此示例每个block的线程数量大于512,会触发重编译动作,因此也会触发binary cache功能,编译运行。然后执行以下命令:
cd ~/.metax/shadercache/
ls -l
结果如图 4.6 所示,可以看到编译运行生成的cache文件,命名规则和 4.2 运行时编译和动态加载描述一致。
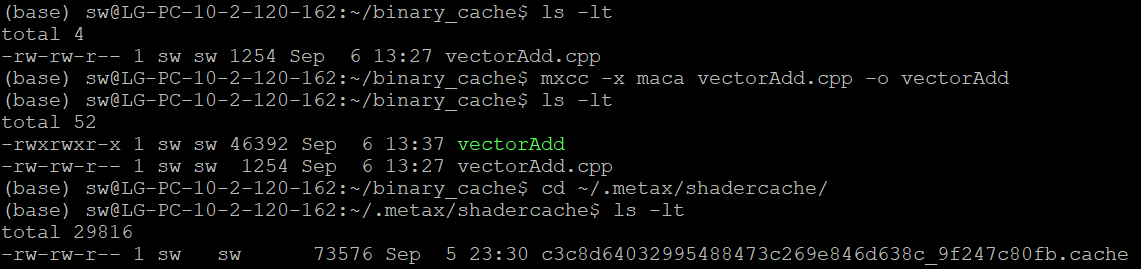
图 4.6 Binary Cache生成
4.3.1. 更改Binary Cache 文件支持Size
需要设置环境变量:MACA_CACHE_MAXSIZE
编辑 ~/.bashrc 文件:
vim ~/.bashrc
在文件末尾加入以下内容:
export MACA_CACHE_MAXSIZE = xxx // 所设置的文件大小,单位字节
保存后执行以下命令:
source ~/.bashrc
4.3.2. 自定义Cache文件路径
需要设置环境变量:MACA_CACHE_PATH
编辑 ~/.bashrc 文件
$ vim ~/.bashrc
在文件末尾加入以下内容:
export MACA_CACHE_PATH=your/specific/path //用户自定义路径
4.3.3. 关闭Binary Cache功能
编辑~/.bashrc文件
vim ~/.bashrc
在文件末尾加入以下内容:
export MACA_CACHE_DISABLE=1
备注
将
MACA_CACHE_DISABLE的值改为0或者不设置即可重新启用binary cache功能。
4.4. 环境变量
曦云系列GPU支持在程序启动前通过环境变量对运行行为进行精细化管控,覆盖设备枚举与属性控制、编译控制、常用执行控制、模块加载及基础调试等典型场景。支持的环境变量参见表 4.1。
变量名称 |
可设置值 |
缺省值 |
描述 |
|---|---|---|---|
设备枚举和属性控制 |
|||
MACA_VISIBLE_DEVICES |
GPU UUID、Device Node ID |
无 |
控制 MXMACA 应用程序能够识别哪些 GPU 设备,以及这些设备以何种顺序被枚举。 可以指定GPU UUID,例如: 也可以指定设备节点ID,例如: |
MACA_DEVICE_ORDER |
FASTEST_FIRST或PCI_BUS_ID |
FASTEST_FIRST |
控制 MXMACA 对可用设备进行枚举的顺序。 FASTEST_FIRST:根据设备计算能力从快到慢排序。 PCI_BUS_ID:根据PCI总线ID升序排列设备。 |
编译控制 |
|||
MACA_CACHE_DISABLE |
0-1 |
0 |
控制磁盘上的即时编译(JIT)缓存的行为。 如果设置为1,则禁用binary cache。 设置为0或不设置时,启用binary cache。 |
MACA_CACHE_PATH |
filepath |
指定磁盘上的即时编译(JIT)文件存储位置。 当未设置时,cache文件存储在默认目录下: |
|
MACA_CACHE_MAXSIZE |
0-4294967296 |
268435456 |
指定即时编译(JIT)能缓存的单个cache文件的最大size。 当生成的cache文件超过这个值时,则不进行缓存。 当不设置时,默认为268435456(256 MB)。如果设置超过4294967296(4 GB),则只按4 GB生效。 |
常用执行控制 |
|||
MACA_LAUNCH_BLOCKING |
0-1 |
0 |
指定是否启用异步内核启动功能,值可以设置为: 0:Stream上启动内核表现为异步。 1:Stream上启动内核表现为同步。 |
模块加载(Module Loading) |
|||
MACA_MODULE_LOADING |
LAZY或EAGER |
LAZY |
控制核函数的预加载(kernel preloading)方式。 设置为EAGER时,在调用模块加载API时,预先加载核函数的设备代码到设备显存。 当设置为LAZY时,在核函数首次在设备启动执行时,加载核函数的设备代码到设备显存。 |
常用调试控制 |
|||
MXLOG_LEVEL |
off critical error warn info debug verbose |
error |
MXMACA日志级别管理。 功能1:全量调整日志级别。层级从高到低逐层递减,设置到相应层级,会打开该层级及更高层级日志,默认设置为error层级,可按需调整: 设置为off时,关闭所有日志。 设置为critical时,仅打开严重错误相关日志。 设置为error时,打开error层级及更高层级相关日志。 设置为warn时,打开warn层级及更高层级相关日志。 设置为info时,打开info层级及更高层级相关日志。 设置为debug时,打开debug层级及更高层级相关日志。 设置为verbose时,打开最高层级相关日志。 功能2:支持模块化日志级别设置: 模块名:从 级别:与全局调整的级别可设置值一致。 例如: 功能3:控制日志刷新级别,强制实时刷新日志: 用途说明:仅调试使用,性能开销大,解决异常退出时日志缓存未落盘问题(如Ctrl+C终止)。 |
此外,针对复杂应用需求,曦云系列GPU还提供面向策略控制、高阶执行控制、多进程服务、内核态加载参数调整及高阶调试等功能的环境变量支持。支持的环境变量参见表 4.2。
变量名称 |
可设置值 |
缺省值 |
描述 |
|---|---|---|---|
策略控制 |
|||
MACA_CPU_THREAD_POLICY |
-1-3 |
0 |
设置API CPU占用策略。 -1:运行时API使用最小化CPU占用策略。 0:运行时API使用默认CPU线程策略,平衡CPU的占用和API的latency。 1:运行时API使用温和抢占CPU线程资源策略,降低event/signal/sync相关API latency。 2:运行时API使用积极抢占CPU线程资源策略,降低event/signal/sync相关API latency。 3:运行时API使用激进抢占CPU线程资源策略,降低event/signal/sync相关API latency。 |
MACA_HOST_MEMORY_POLICY |
-1-0 |
0 |
主机内存策略。 -1:运行时API使用最小化host系统内存占用策略。 0:运行时API使用默认host系统内存占用策略,平衡系统内存的占用和API的latency。 |
MACA_SYNC_POLICY |
0-3 |
0 |
API使用的CPU同步策略。 设置为0时,运行时API使用默认CPU同步策略。 设置为1时,运行时API使用GPU进行signal同步,offload CPU并降低同步latency。 设置为2时,运行时API使用GPU进行event同步,offload CPU并降低同步latency。 设置为3时,运行时API使用GPU进行signal & event同步,offload CPU并降低同步latency。 |
MACA_PRIORITY_QUEUE_POLICY |
0-0xHNL |
0 |
设置高/中/低优先级硬件队列个数策略。 0xHNL:H/N/L表示高/中/低优先级队列的数量,每个数字范围在[0,16]内,高/中/低优先级硬件队列个数总和最多16个。 注意:每个字母占用4位,低优先级队列数量必须大于等于1,例如0x5A1。 0:使用默认配置,H/N/L各优先级最多分别占用8/4/4个硬件队列。 |
MACA_MALLOC_POLICY |
0-0x1FF |
0 |
设备全局内存分配内存清零策略。 设置为0时,设备全局内存分配策略使用默认设置(不自动清零)。 非默认设置的设备全局内存分配策略基于比特位设置来控制,比特位设置详情见下表。 第0比特[ 0, 2M) 自动清零 第1比特[ 2M, 8M) 自动清零 第2比特[ 8M, 32M) 自动清零 第3比特[ 32M, 128M) 自动清零 第4比特[128M, 512M) 自动清零 第5比特[512M, 2G) 自动清零 第6比特[ 2G, 8G) 自动清零 第7比特[ 8G, 32G) 自动清零 第8比特[ 32G, 128G) 自动清零 例如,当设置为0x11时,如果参数大小在[0, 2M)或[128M, 512M)范围内,mcMalloc将返回清零的内存。 注意:如果未设置,则将不进行内存清零。 |
高阶执行控制 |
|||
MACA_TRAP_HANDLER |
0-3 |
1 |
功能异常Trap处理开关。 0:关闭trap上报功能,trap指令会替换成snop指令继续执行至kernel完成。 1:开启trap上报功能,仅对Fatal类异常进行上报。 2:开启trap上报功能,对Fatal类异常和Numeric类异常(不包含精度损失异常)都进行上报。 3:开启trap上报功能,对Fatal类异常和Numeric类异常都进行上报。 |
MACA_GRAPH_LAUNCH_MODE |
0-2 |
1 |
控制Graph启动方式。 0:图编程的任务提交使用标准核函数提交模式,即使用Ring Buffer逐一启动Graph节点。 1:图编程的任务提交使用任务图提交模式,即使用indirect buffer缓存所有Graph节点并从indirect buffer启动Graph。 2:使用任务图提交模式并在Graph中启用程序依赖启动(PDL)。 |
MACA_DIRECT_DISPATCH |
0-1 |
0 |
Direct Dispatch功能开关。 设置为0时,每个Stream会额外创建一个线程管理该Stream上的任务并提交到硬件去执行。 设置为1时,Stream上直接在Application线程管理任务直至提交到硬件去执行。 注意:设置为1时,MACA_SYNC_POLICY 自动设置成3。 |
MACA_RING_BUFFER_SIZE |
2 的 N 次方 (N >= 10) |
1024 |
控制GPU异构系统的环形缓冲区(Ring Buffer)大小,平衡数据处理性能和内存占用。 正确配置示例: export MACA_RING_BUFFER_SIZE=4096 # 设置为 4096(2^12)。 错位配置示例: export MACA_RING_BUFFER_SIZE=3000 # 错误:不是 2 的幂次方。 注意:MACA_DIRECT_DISPATCH设置为1时,该环境变量缺省值是2048。 |
多进程服务(Multi-Process Service) |
|||
MACA_MPS_MODE |
0-1 |
0 |
MPS(多进程服务)模式。 设置为1时,多个进程可以同时使用共享的GPU硬件queue,通过一个或多个共享的GPU硬件queue向GPU提交工作。 设置为0时,一个进程对申请到的GPU硬件queue进行独占使用。其它进程可以通过其它可用的GPU硬件queue同时向GPU提交工作。 |
内核态环境变量 |
|||
pri_mem_sz |
0-36 |
4 |
设置的private memory size,内核态环境变量,对服务器上的所有用户进程生效。在
( XX 为需要设置的private memory size,单位为KB) |
高阶调试控制 |
|||
MXLOG_CONSOLE |
on,off |
on |
控制日志是否输出到控制台。 设置成on,日志输出到控制台,同时日志会写入日志文件,缺省日志文件路径在 设置成off,日志不输出到控制台。但关闭后日志仍会写入日志文件。 关闭用途说明:避免大量日志打印影响终端操作性能,提升命令行交互体验。 |
MACA_HOTSPOT_MEMSTACK |
0-2 |
0 |
控制MXMACA SDK的Memory Tracing功能。 设置为0时,关闭Memory Tracing功能。 设置为1时,打开APP的Memory Tracing功能。 设置为2时,打开SDK的Memory Tracing功能。 |
MACA_KERNEL_TIMEOUT |
0-60000 |
0 |
GPU硬件监控核函数执行时间,超时后自动触发 GPU Trap 并输出 Ring-Buffer 的 Mini-Dump,辅助定位故障点。 设置为0时,关闭核函数超时检测机制。 设置为1-60000时,开启核函数超时检测,若执行时间超过设定值(单位:毫秒),则触发 GPU Trap 并输出 Ring-Buffer 的 Mini-Dump。 |
MACA_MONITOR_HANG_TIMEOUT |
0-3600 |
0 |
MXMACA SDK监控核函数执行时间和DMA拷贝执行时间,超时后自动打印 EID 和输出相关日志信息,辅助分析原因、影响和修复建议。 0:关闭SDK超时监控机制。 ﹥0:开启SDK超时监控,若执行时间超过设定值(单位:秒),则打印 EID 和输出相关日志信息。 |
MACA_STREAM_CREATE_TIMEOUT |
0-3600 |
0 |
MXMACA SDK创建stream的超时设置 0:关闭SDK创建stream的超时设置(一直尝试直到获得stream所需硬件资源)。 ﹥0:若创建stream的时间超过设定值(单位:秒),则打印日志输出相关信息。 |
MACA_BACK_TRACE |
0-1 |
0 |
当遇到段错误时通过捕获segsegv信号打印回溯调用栈。 0:不打印调用栈回溯。 1:打印调用栈回溯。 |
MACA_TRACING_MODE |
0-2 |
0 |
配置mcTracer trace行为模式。 0:不配置,使用默认模式,即模式1。 1:使用尽最大努力保证时间线准确性模式。 2:使用对应用程序行为的影响最小模式。 |
MACA_GRAPH_TRACE_MODE |
0-1 |
1 |
设置mcTracer Graph的跟踪粒度。 0:(Graph级别)Graph将作为一个整体被跟踪,不会收集节点活动。这可以将开销减少到最小。 1:(节点级别)将收集节点活动,但Graph不会被作为一个整体跟踪。这可能会引起显著的运行时开销。 |
4.5. 主机代码调试信息
曦云系列GPU支持通过环境变量 MXLOG_LEVEL 设置MXMACA驱动软件的日志输出等级,可选等级如下:
off:关闭日志输出error:仅打印error级别日志warning:输出warning及error级别日志info:输出information、warning及error级别日志debug:输出全部日志
曦云系列GPU上编程,既支持直接使用原生的 printf 自行设计和管理,也可以借助MXMACA驱动软件的日志管理方案,mcanalyzer动态库,提供 mcLog API,如图 4.7 所示:
使用
mcLogAPI之前,需要include它的头文件,mxlog.h 位于MXMACA软件包成功安装后 include 目录的子目录 mxlog;根据应用程序对于日志等级的定义,选用相应的
mcLogAPI:LOGE/LOGW/LOGI/LOGD/LOGV;使用mxcc编译时,需要指定
-lmcanalyzer编译选项;使用环境变量
MXLOG_LEVEL,可以设置日志输出最低等级。如果该环境变量未设置,MXMACA会使用一个缺省的日志输出最低等级,一般是error或者info。
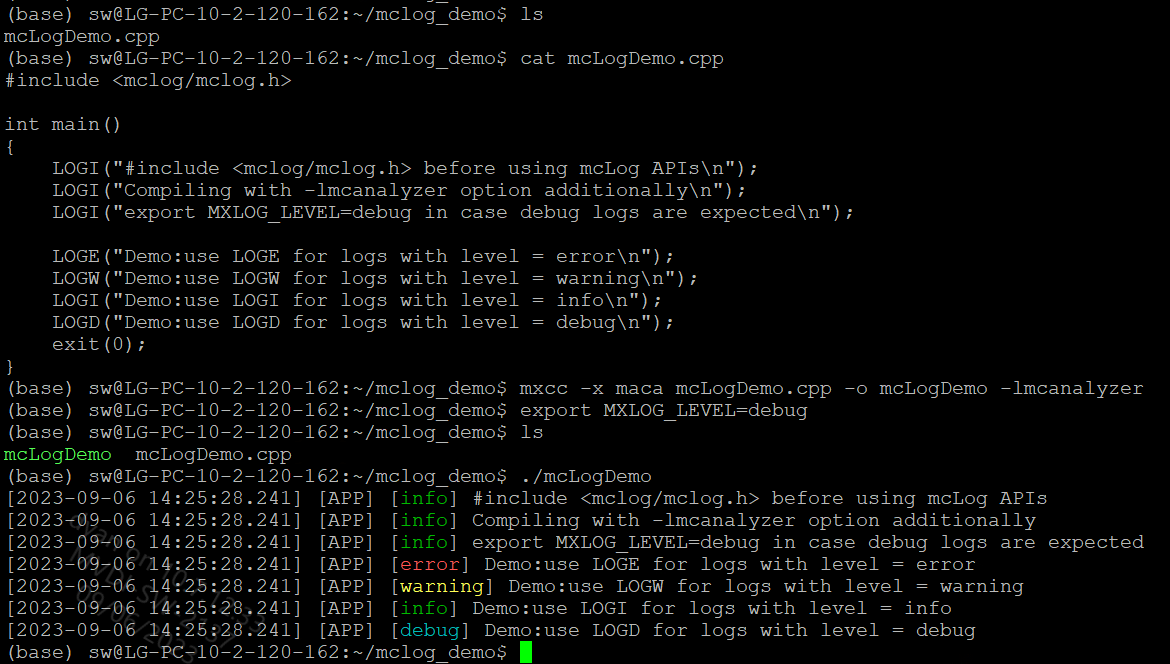
图 4.7 mcanalyzer动态库提供的mcLog API示例
4.6. 设备代码调试信息
4.6.1. 使用GPU printf
当需要在设备侧代码输出调试信息时,曦云系列GPU支持在设备核函数里面使用 printf 函数打印相关信息。
代码示例
使用GPU printf,示例代码如下:
__global__ void vectorAdd(const float* a, const float* b, float* c, int width, int height)
{
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
int i = x;
if (i < (width * height))
{
c[i] = a[i] + b[i];
printf("c[%d]:%f \n", i, c[i]);
}
在kernel里面添加了 printf 后,执行程序,得到输出结果部分如图 4.8 所示。
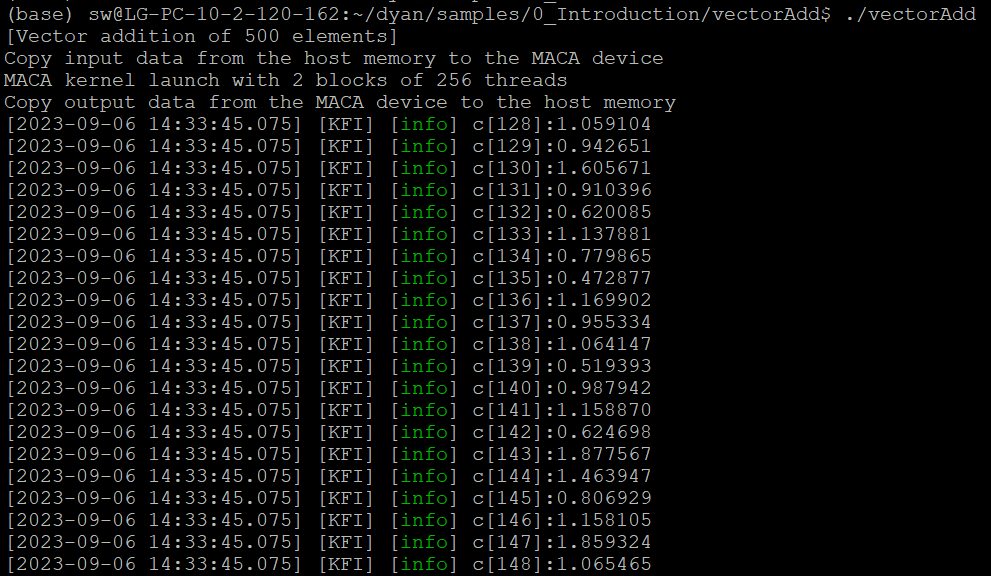
图 4.8 printf输出结果
从图 4.8 中我们可以看出,当在核函数里面使用 printf 输出结果时,一个线程束里面64个线程将按照顺序依次打印结果,但是无法保证线程束与线程束之间的打印顺序。
因此,我们不能用打印信息的顺序来体现程序的执行顺序。
4.6.2. 使用GPU Trap Handler
曦云架构GPU的硬件支持将Shader执行期间产生的异常写进 TRAP_STATUS 寄存器中,并且能选择性地在异常发生时插入一条trap指令。 Trap指令会使Shader以更高的特权级别执行trap kernel,在trap kernel中可以定义和决定如何处理该异常,处理流程如图 4.9 所示。
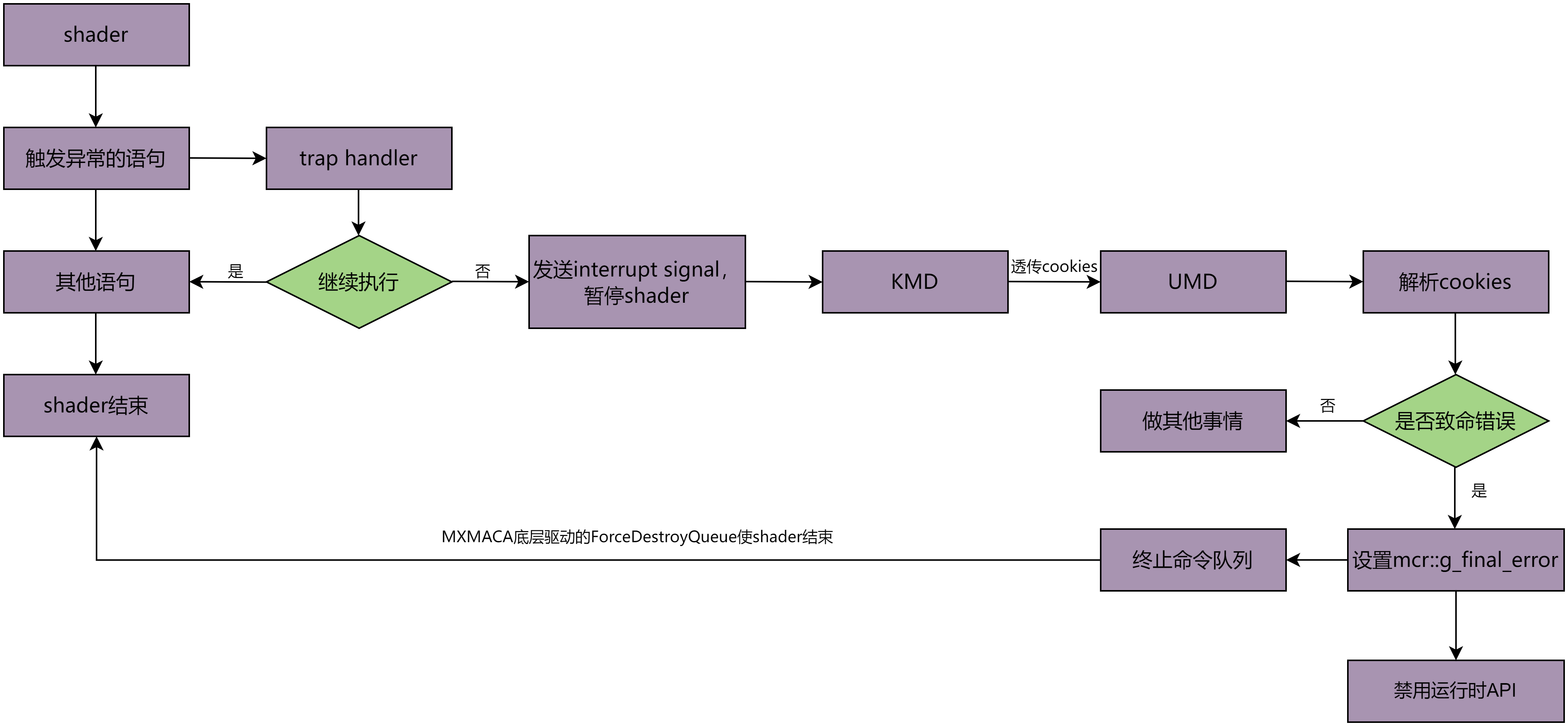
图 4.9 GPU Trap Handler处理流程
基于trap kernel功能,当用户层程序触发相应异常信号时,MXMACA将进行相应处理并给出相关提示信息以供用户进行程序代码调试。
代码示例
使用GPU trap handler,示例代码如下所示:
#include<mc_runtime.h>
typedef struct
{
alignas(4)float f;
double d;
}__attribute__((packed)) test_type_mem_violation;
__global__ void trigger_memory_violation(test_type_mem_violation *dst)
{
atomicAdd(&dst->f,1.23);
atomicAdd(&dst->d,20);
dst->f=9.8765;
}
int main()
{
test_type_mem_violation hd={0};
test_type_mem_violation *ddd;
mcMalloc((void**)&ddd,sizeof(test_type_mem_violation));
mcMemcpy(ddd,&hd,sizeof(test_type_mem_violation),mcMemcpyHostToDevice);
trigger_memory_violation<<<dim3(1),dim3(1)>>>(ddd);
mcMemcpy(&hd,ddd,sizeof(test_type_mem_violation),mcMemcpyDeviceToHost);
mcFree(ddd);
return 0;
}
如果运行以上代码将会得到如图 4.10 所示的错误信息:

图 4.10 trap错误信息
重点关注红框内给出信息,MCR层给出提示信息 [MCR][E]mx_device.cpp:1729:Memory violation exception happened in the shader, mcruntime api will be disabled 并设置了 g_final_error,对应异常类型来看:核函数触发了异常类型 3—Memory violation,对照触发异常条件可以知道,我们的核函数代码可能存在访问内存的偏移量小于0,越界或数据未按要求对齐。
检查代码可发现:由于在结构体 test_type_mem_violation 中 alignas(4) 对float进行强制对齐以及对结构体进行了 attribute((packed)),所以结构体 test_type_mem_violation 的size为 double:8 加上 float:4 等于12,由于64-bit的atomic操作要求数据按照8字节对齐,故这里的结构体没有按照要求对齐,所以引发了trap。
将程序做如下修改即可解决该问题:
#include<mc_runtime.h>
typedef struct
{
float f;
double d;
}test_type_mem_violation;
__global__ void trigger_memory_violation(test_type_mem_violation *dst)
{
atomicAdd(&dst->f,1.23);
atomicAdd(&dst->d,20);
dst->f=9.8765;
}
int main()
{
test_type_mem_violation hd={0};
test_type_mem_violation *ddd;
mcMalloc((void**)&ddd,sizeof(test_type_mem_violation));
mcMemcpy(ddd,&hd,sizeof(test_type_mem_violation),mcMemcpyHostToDevice);
trigger_memory_violation<<<dim3(1),dim3(1)>>>(ddd);
mcMemcpy(&hd,ddd,sizeof(test_type_mem_violation),mcMemcpyDeviceToHost);
mcFree(ddd);
return 0;
}