5.1. Volcano
Volcano是 CNCF 下首个也是唯一的基于Kubernetes的容器批量计算平台,主要用于通用计算场景。 它提供了Kubernetes目前缺少的一套机制,这些机制通常是机器学习大数据应用、科学计算、特效渲染等多种通用计算工作负载所需的。 作为一个通用批处理平台,Volcano与几乎所有的主流计算框架无缝对接,如 Spark 、 TensorFlow 、 PyTorch 、 Flink 、 Argo 、 MindSpore 、 PaddlePaddle 等。 它还提供了包括基于各种主流架构的CPU、GPU在内的异构设备混合调度能力。
Volcano提供了丰富的调度策略,增强型的Job管理能力及良好的生态支持,支持扩展自定义插件。 更多相关信息,参见 Volcano官方文档 。
5.1.1. 部署Volcano
备注
部署Volcano之前,请确保已安装可用的Kubernetes集群,且Kubernetes版本≥1.23。
5.1.1.1. 安装Helm
操作步骤参见 1.4.2 推送Helm Chart。
5.1.1.2. 解压离线安装包
Volcano容器镜像及Helm Chart软件包以离线形式发布。
以0.8.1版本为例,用户可在随本文档发布的软件包中找到名为 volcano-package-0.8.1.tar.gz 的压缩包,并进行解压缩。
mkdir k8s
tar -C k8s -xvzf volcano-package.0.8.1.tar.gz
volcano-images.0.8.1.run
volcano-0.8.1.tgz
5.1.1.3. 推送容器镜像
用户可执行以下命令将Volcano镜像推送到镜像仓库,操作步骤参见 1.4.1 推送容器镜像。
./k8s/volcano-images.0.8.1.run push DOMAIN/PROJECT
5.1.1.4. 安装Volcano
在Kubernetes管理节点执行以下命令安装Volcano。
helm install volcano volcano-0.8.1.tgz --create-namespace -n volcano \
--set basic.controller_image_name=DOMAIN/PROJECT/vc-controller-manager \
--set basic.scheduler_image_name=DOMAIN/PROJECT/vc-scheduler \
--set basic.admission_image_name=DOMAIN/PROJECT/vc-webhook-manager \
--wait
用户可通过在命令中增加 --set option=value 的方式设置可选参数,参数含义参见下表。
选项 |
类型 |
描述 |
basic.controller_image_name |
string |
Volcano controller镜像名称 |
basic.scheduler_image_name |
string |
Volcano scheduler镜像名称 |
basic.admission_image_name |
string |
Volcano admission镜像名称 |
basic.image_pull_policy |
string |
镜像拉取策略。默认为 |
5.1.1.5. 验证部署
在Kubernetes管理节点执行以下命令查看Volcano部署状态。
kubectl get pod -n volcano
NAME READY STATUS RESTARTS AGE
volcano-admission-67c4564c6-twzdj 1/1 Running 0 31s
volcano-admission-init-mbtnr 0/1 Completed 0 31s
volcano-controllers-568447f669-g844c 1/1 Running 0 31s
volcano-scheduler-76d6458568-sjbbl 1/1 Running 0 31s
5.1.1.6. 卸载Volcano
在Kubernetes管理节点执行以下命令卸载Volcano。
helm uninstall -n volcano volcano
5.1.2. 扩展插件
基于Volcano调度器的扩展框架,沐曦提供了如下扩展调度插件,旨在解决特定场景下的调度需求,提升系统的整体性能和用户体验。
插件 |
描述 |
gpu-aware |
分析集群中所有可调度节点的GPU拓扑信息,结合配置中的权重对节点评分。为申请GPU资源的任务,选择最优的调度节点 |
gpu-podaffinity |
支持GPU亲和性任务的调度:基于节点/机架/地理区域等拓扑域,将任务中具有亲和性的Pod调度至同一个拓扑域 |
用户可根据实际场景的调度需求,选择相应的扩展插件。
备注
使用扩展插件之前,请确保Volcano已经部署且运行状态正常。
5.1.2.1. gpu-aware
gpu-aware 是为GPU调度场景研发的插件。它通过分析GPU拓扑信息,结合配置中的权重,计算可调度节点的分数。为申请GPU的任务推荐适合的调度节点,提升集群GPU资源的利用率。
GPU拓扑信息
拓扑信息由Kubernetes节点标签 metax-tech.com/gpu.topology.losses 和 metax-tech.com/gpu.topology.scores 标识。例如下表中的集群节点信息:
节点 |
标签 |
node1 |
|
node1 |
|
node2 |
|
node2 |
|
例如node1的两个标签:
metax-tech.com/topology.scores中"2":110,代表在当前节点上申请2张显卡时,它们的通信拓扑分数是 110。通信拓扑分数越大,通信效率越高。metax-tech.com/topology.losses中"1":220,代表在当前节点上申请2张显卡时,通信拓扑损失分数是 220。拓扑损失分数越大,剩余卡的通信效率越低。
因为拓扑损失分数的存在,调度时会尽可能调度到有资源恰好满足或接近申请GPU数量的节点上,减少资源碎片化的情况。
配置插件
在Kubernetes管理节点执行以下命令更新Volcano调度插件配置。
kubectl edit configmaps -n volcano volcano-scheduler-configmap
apiVersion: v1
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- plugins:
- name: overcommit
- name: drf
enablePreemptable: false
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
- name: gpu-aware # add it to enable gpu-ware plugin
arguments: # add it to enable gpu-ware plugin
weight: 1 # add it to enable gpu-ware plugin
loss.weight: 0.5 # add it to enable gpu-ware plugin
在配置时,需要填写下表中的所有参数:
参数 |
描述 |
weight |
在所有插件中,当前插件的权重。数值越高,当前插件对调度结果的影响越大 |
loss.weight |
损失分数权重。数值越高,集群中的GPU资源碎片越少 |
准备作业yaml文件
通过Volcano Job提交任务,用户可参考如下示例编写作业yaml文件:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: test-job-plugin
spec:
minAvailable: 1
schedulerName: volcano
policies:
- event: PodEvicted
action: RestartJob
plugins:
env: []
ssh: []
svc: []
maxRetry: 2
queue: default
tasks:
- replicas: 2
name: "gpu-vectoradd"
template:
spec:
containers:
- name: ubuntu
image: ubuntu:22.04
imagePullPolicy: IfNotPresent
command: ['bash', '-c']
args: ["sleep 10s"]
resources:
limits:
metax-tech.com/gpu: 2
restartPolicy: Never
提交任务
在Kubernetes管理节点执行以下命令提交任务。
kubectl create -f sample.yaml
5.1.2.2. gpu-podaffinity
在实际场景中,基于特定物理拓扑/机架/地理区域等因素,将集群内GPU间通信效率高的一些节点组成一个拓扑域。 任务在某些Pod间由于通信非常频繁,称之为具有Pod间亲和性。 调度器需要将具有亲和性的Pod调度至同一个拓扑域,提高任务的通信效率。
gpu-podaffinity插件的作用正是如此,示意图如下。
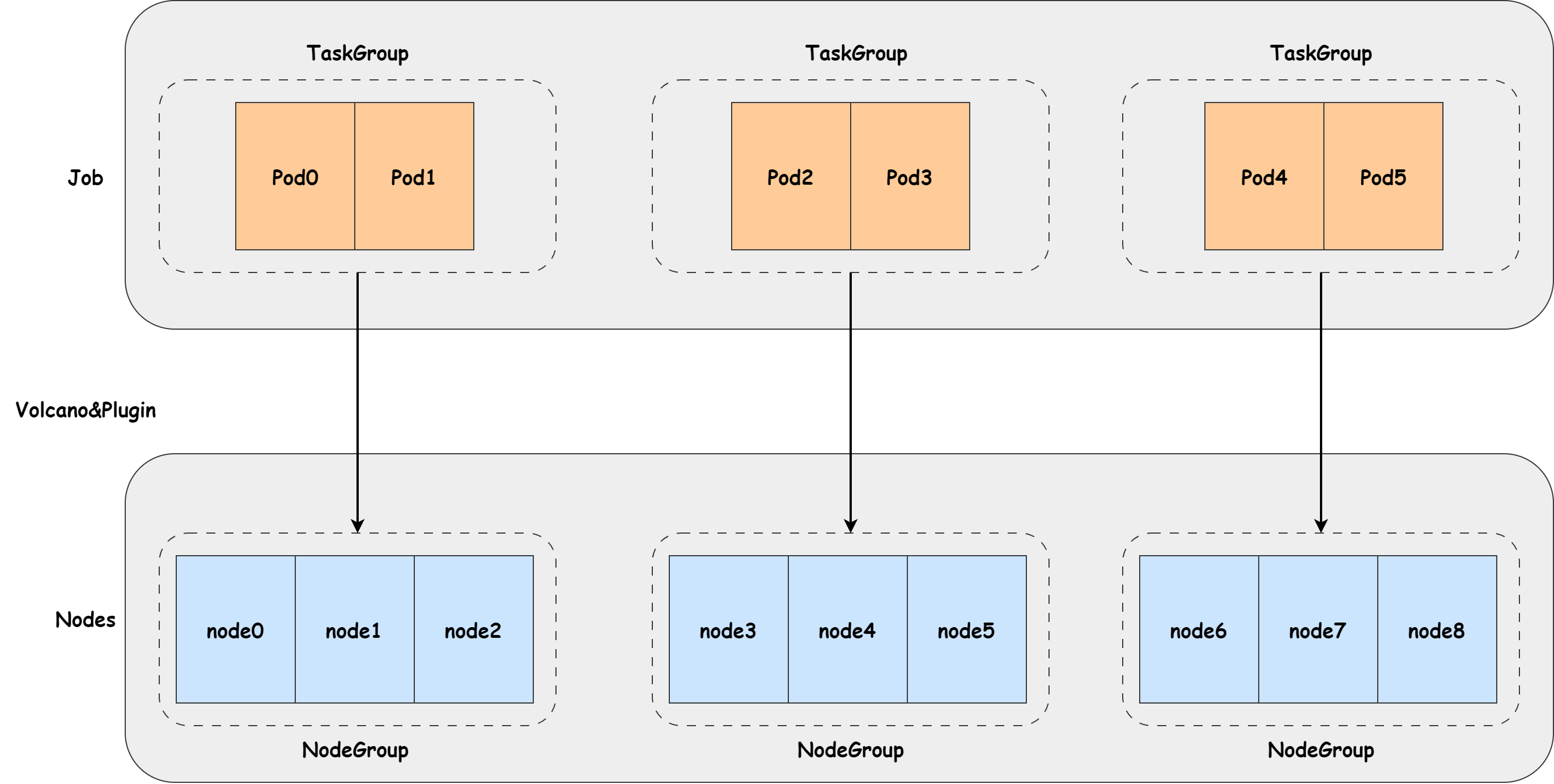
图 5.1 gpu-podaffinity插件
拓扑域
gpu-podaffinity插件自身没有管理识别集群拓扑域的能力,用户可通过部署拓扑组件生成拓扑域。详情参见 2.1.6 启用topoDiscovery(可选)。
Pod间亲和性
在任务中存在多组具有亲和性的Pod,用户难以在静态JobSpec/PodSpec体现它们。
结合Pod申请沐曦GPU资源数量与Pod ID,沐曦设计了Kubernetes Pod注解 metax-tech.com/gpu-group-size,它的值表示具有亲和性的Pod申请沐曦GPU资源的总量。
例如 metax-tech.com/gpu-group-size 的值为 m,Pod申请沐曦GPU资源数量为 n,可以得到 k=m/n 数量的Pod具有亲和性。
那么 k 个Pod ID为 [k * z, k * (z + 1)) , z ∈ Z 的Pod间具有亲和性。
用户仅需为任务中的Pod指定该注解,gpu-podaffinity插件会自动计算Pod间的亲和性。
备注
Pod ID用于标识分布式训练环境中各个Pod的身份。例如PyTorch任务中会为Pod设置从0开始依次累加的ID RANK。
配置插件
在Kubernetes管理节点执行以下命令更新Volcano调度插件配置。
kubectl edit configmaps -n volcano volcano-scheduler-configmap
apiVersion: v1
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- name: gpu-podaffinity # add it to enable gpu-podaffinity plugin
- plugins:
- name: overcommit
- name: drf
enablePreemptable: false
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
准备作业yaml文件
目前gpu-podaffinity插件仅支持PyTorch任务。用户可以参考以下示例在多个平台上编写PyTorch作业yaml文件。
重要
请确保yaml文件中指定了 volcano 调度器及 metax-tech.com/gpu-group-size 注解,否则gpu-podaffinity插件不会工作。
kubeflow/PyTorchJob
apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-demo namespace: kubeflow spec: pytorchReplicaSpecs: Master: replicas: 1 restartPolicy: Never template: metadata: annotations: metax-tech.com/gpu-group-size: "32" spec: schedulerName: volcano containers: - name: pytorch image: alpine:3.19 command: ['sh', '-c'] args: ["sleep infinity"] imagePullPolicy: Always resources: limits: metax-tech.com/gpu: 8 Worker: replicas: 7 restartPolicy: Never template: spec: schedulerName: volcano containers: - name: pytorch image: alpine:3.19 command: ['sh', '-c'] args: ["sleep infinity"] imagePullPolicy: Always resources: limits: metax-tech.com/gpu: 8
Volcano Job
apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: pytorch-demo spec: schedulerName: volcano plugins: pytorch: ["--master=master","--worker=worker","--port=23456"] # Pytorch plugin register tasks: - replicas: 1 name: master policies: - event: TaskCompleted action: CompleteJob template: metadata: annotations: metax-tech.com/gpu-group-size: "32" spec: containers: - image: alpine:3.19 imagePullPolicy: IfNotPresent name: master command: ['sh', '-c'] args: ["sleep infinity"] resources: limits: metax-tech.com/gpu: 8 restartPolicy: Never - replicas: 7 name: worker template: spec: containers: - image: alpine:3.19 imagePullPolicy: IfNotPresent name: worker command: ['sh', '-c'] args: ["sleep infinity"] resources: limits: metax-tech.com/gpu: 8
dlrover/ElasticJob
apiVersion: elastic.iml.github.io/v1alpha1 kind: ElasticJob metadata: name: pytorch-demo namespace: dlrover spec: distributionStrategy: AllreduceStrategy optimizeMode: single-job replicaSpecs: worker: replicas: 8 template: metadata: annotations: metax-tech.com/gpu-group-size: "32" spec: schedulerName: volcano restartPolicy: Never containers: - name: main image: alpine:3.19 imagePullPolicy: Always command: ['sh', '-c'] args: ["sleep infinity"] resources: limits: metax-tech.com/gpu: 8
提交任务
备注
在提交任务之前,请确保相应的平台组件已经部署且运行状态正常。
在Kubernetes管理节点执行以下命令提交任务。
kubectl create -f sample.yaml