1. 概述
mx-exporter是用于在集群环境中收集曦云® GPU设备指标数据的工具。集群监控系统Prometheus可以通过HTTP从运行于每个节点的mx-exporter拉取设备指标数据。 可视化工具Grafana将收集的GPU设备指标转化成易于理解的图表。
本文将介绍如何在Kubernetes集群中部署Prometheus,Grafana,mx-exporter来监控GPU设备。
mx-exporter指标及标签具体说明请参见《曦云系列® 通用计算GPU mx-exporter使用手册》
2. 环境信息及新建Namespace
2.1. 环境信息
本文中各工具应用的版本参见下表,用户可根据实际情况选取版本。
名称 |
版本 |
|---|---|
Kubernetes |
v1.24.0 |
docker |
20.10.21 |
containerd |
1.6.10 |
Prometheus |
v2.46.0 |
Grafana |
11.2.2 |
Helm |
v3.9.3 |
2.2. 导入mx-exporter镜像
操作步骤
解压mx-exporter镜像包。
tar -zxvf mx-exporter.xxx.tgz
根据主机的架构加载对应的镜像。对于x86架构主机,使用amd64后缀的镜像;对于Arm架构主机,使用arm64后缀的镜像。
cd mx-exporter; docker load -i mx-exporter-xx-amd64.xz
将mx-exporter镜像推送到Harbor中,用户需要更改部署脚本中的镜像下载地址为设置的推送地址,例如Harbor为
mxcr.io。docker login -u $user mxcr.io docker tag mxcr.io/cloud/mx-exporter:xxx mxcr.io/$project/mx-exporter:xxx docker push mxcr.io/$project/mx-exporter:xxx
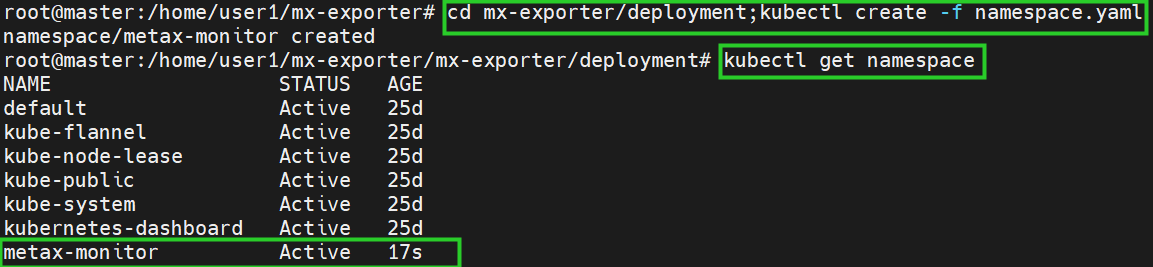
2.3. 在Kubernetes中新建Namespace
操作步骤
3. mx-exporter部署
本节介绍两种在Kubernetes上部署mx-exporter的方式,用户可根据需要选择一种。
3.1. Helm方式部署
Helm在 mx-exporter/deployment/mx-exporter/helm 内,可按需设置下表参数,在安装时用 --set 传入以生效。
参数 |
类型 |
描述 |
|---|---|---|
image.repository |
string |
镜像地址,默认为cr.metax-tech.com/cloud/mx-exporter |
image.tag |
string |
镜像版本号 |
service.port |
integer |
设置mx-exporter pod中container的端口,默认为8000 |
gatherInterval |
integer |
指标收集间隔,默认为10000ms |
logMonitor |
integer |
监控kernel log功能,默认启用。该参数项已弃用,即设置成0不生效 |
用户根据mx-exporter镜像信息设置 image.repository 和 image.tag 。
操作步骤(部署mx-exporter)
部署mx-exporter,回显信息如图 3.1 所示。
cd mx-exporter/deployment/mx-exporter/helm; helm install metax-mx-exporter mx-exporter -n metax-monitor --set image.repository=xxx --set image.tag=xxxx

图 3.1 Helm方式部署mx-exporter
查看新建资源信息,回显信息如图 3.2 所示。
helm list -n metax-monitor kubectl get all -n metax-monitor -o wide

图 3.2 查看新建资源信息(Helm)
默认每个节点都已部署mx-exporter。需记录mx-exporter pod IP,在Grafana后续展示中用于筛选需要展示指标的目标服务器。
查看抓取信息
mx-exporter部署成功后,等待40秒,可在k8s中用 curl 命令查看mx-exporter抓取的GPU信息,回显信息如图 3.3 所示。
curl <mx-exporter_pod_ip>:<mx-exporter_service_port>/metrics
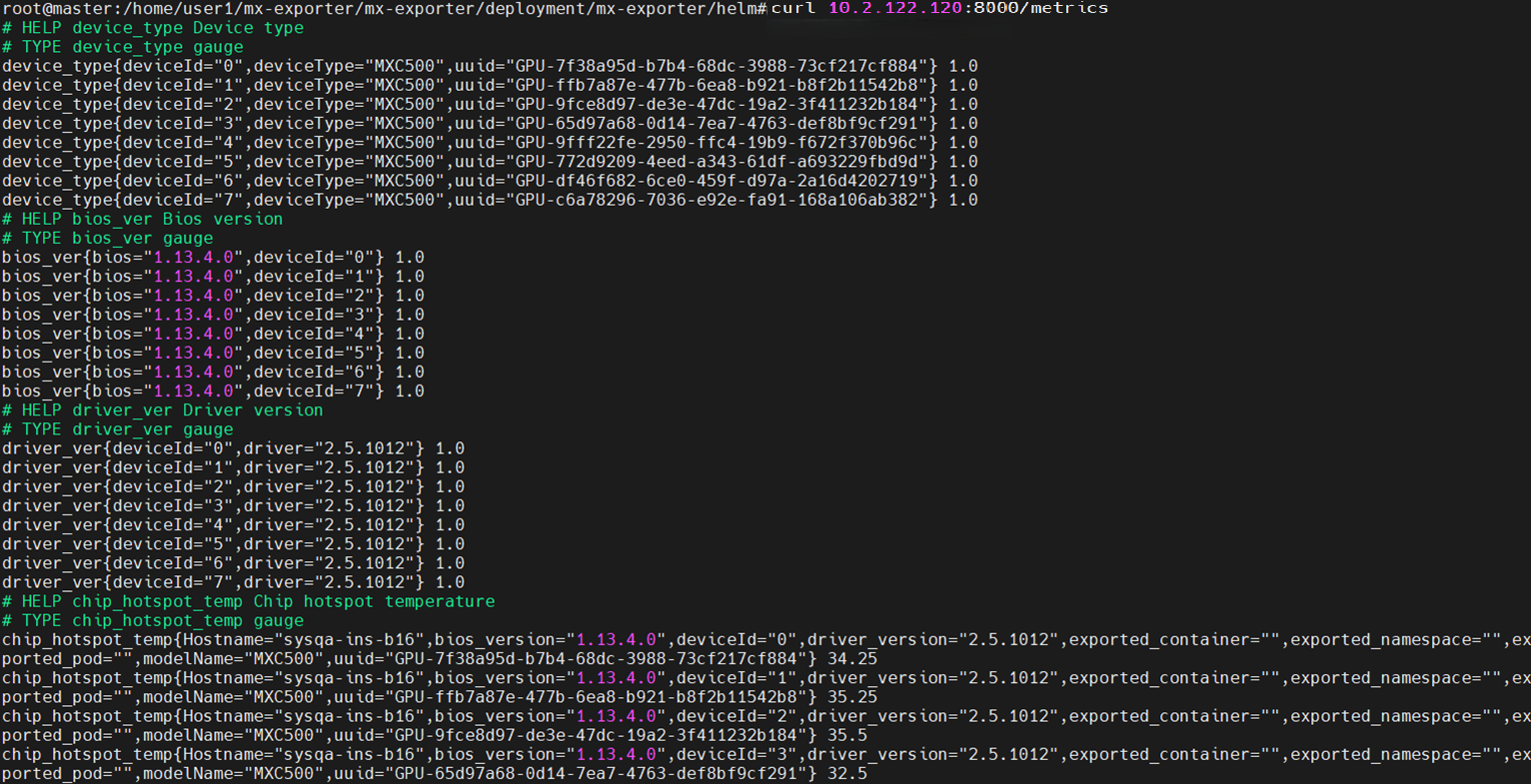
图 3.3 查看mx-exporter抓取信息(Helm)
删除资源
如需删除资源,可使用以下命令:
helm uninstall metax-mx-exporter -n metax-monitor
3.2. YAML方式部署
如需修改下表参数,可编辑mx-exporter/deployment/mx-exporter/mx-exporter-daemonset.yaml。
参数 |
类型 |
描述 |
|---|---|---|
image |
string |
镜像地址:Tag号,用户根据导入的mx-exporter镜像信息设置 |
-c |
string |
用户自定义的指标配置文件,默认在 /etc/config/metrics |
-p |
integer |
port,设置端口,默认为8000 |
-i |
integer |
interval,指标收集间隔,在containers.args中,默认为10000ms |
-lm |
integer |
监控kernel log功能,默认启用。该参数项已弃用,即设置成0不生效 |
操作步骤(部署mx-exporter)
部署mx-exporter。
cd mx-exporter/deployment/mx-exporter; kubectl create -f mx-exporter-daemonset.yaml
回显信息如下:
serviceaccount/metax-mx-exporter created configmap/exporter-metrics-config-map created service/metax-mx-exporter created daemonset.apps/metax-mx-exporter created
查看新建资源信息,回显信息如图 3.4 所示。
kubectl get all -n metax-monitor -o wide

图 3.4 查看新建资源信息(YAML)
默认每个节点都已部署mx-exporter。记录mx-exporter pod IP,在Grafana后续展示中用于筛选需要展示指标的目标服务器。
查看抓取信息
mx-exporter部署成功后,等待40秒,可在k8s中用 curl 命令查看mx-exporter抓取的GPU信息,回显信息如图 3.5 所示。
curl <mx-exporter_pod_ip>:<mx-exporter_service_port>/metrics
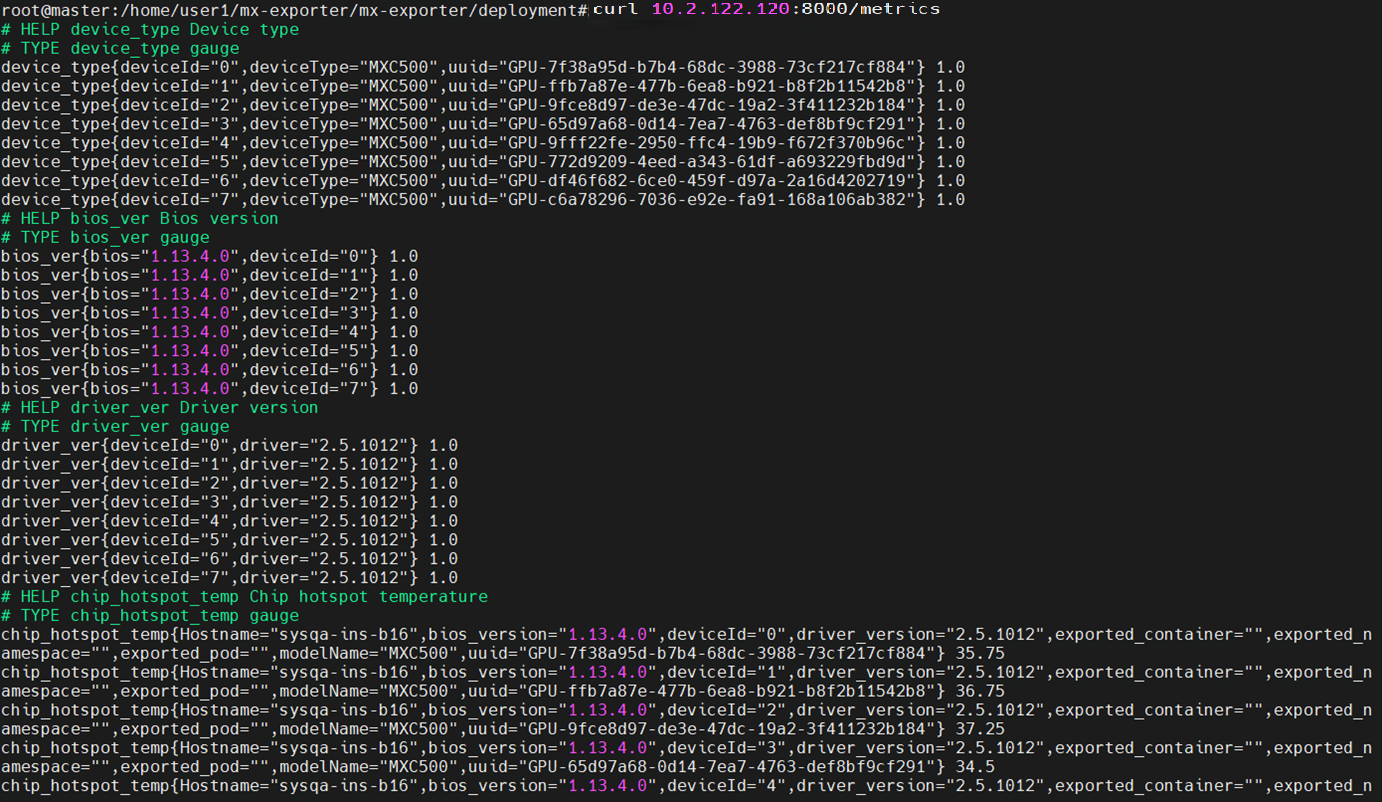
图 3.5 查看mx-exporter抓取信息(YAML)
删除资源
如需删除资源,可使用以下命令:
cd mx-exporter/deployment/mx-exporter; kubectl delete -f .
4. Prometheus部署
如需修改下表参数,可编辑mx-exporter/deployment/prometheus/prometheus-deployment.yaml。
参数 |
描述 |
|---|---|
image |
镜像地址:Tag号,可从Docker Hub下载prom/prometheus:v2.46.0 |
操作步骤(部署Prometheus)
部署Prometheus,回显信息如图 4.1 所示。
cd mx-exporter/deployment/prometheus; kubectl create -f .

图 4.1 部署Prometheus
查看新建资源信息,回显信息如图 4.2 所示。
kubectl get all -n metax-monitor -o wide | grep prom

图 4.2 查看新建Prom信息
可以看到pod,service,deployment,replicaset资源已成功创建。
查看抓取信息
浏览器中输入 http://<k8s_master_ip>:<prometheus_service_port> 访问Prometheus GUI,其中 prometheus_service_port 默认为 30000。 输入已知的GPU指标,查看抓取的信息,如图 4.3 所示。

图 4.3 在Prometheus中查看指标
删除资源
如需删除资源,可使用以下命令:
cd mx-exporter/deployment/prometheus; kubectl delete -f .
5. Grafana部署
如需修改下表参数,可编辑 mx-exporter/deployment/grafana/deployment.yaml 。
参数 |
描述 |
|---|---|
image |
镜像地址:Tag号,可从Docker Hub下载grafana/grafana-oss:11.2.2 |
操作步骤(部署Grafana)
部署Grafana,回显信息如图 5.1 所示。
cd mx-exporter/deployment/grafana; kubectl create -f .

图 5.1 部署Grafana
查看新建资源信息,回显信息如图 5.2 所示。
kubectl get all -n metax-monitor -o wide | grep grafana

图 5.2 查看新建Grafana信息
可以看到pod,service,deployment,replicaset资源已成功创建。
删除资源
如需删除资源,可使用以下命令:
cd mx-exporter/deployment/grafana; kubectl delete -f .
登录Grafana UI界面
不同版本的Grafana UI显示可能有差别,图 5.3 以11.2.2为示例。
在浏览器中输入 http://<k8s_master_ip>:<grafana_service_port> ,其中 grafana_service_port 默认为32000。
首次登录用户名为 admin , 密码为 admin 。登录后可立即更新密码,也可点 skip 暂时跳过。
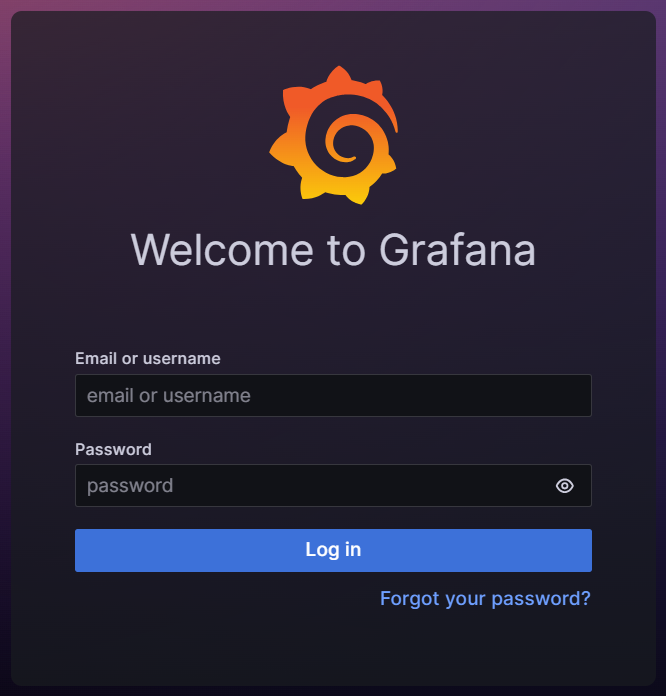
图 5.3 Grafana登录界面
6. GPU性能指标展示
6.1. 接入Prometheus数据
操作步骤
在Grafana中点击 Home 选择 Connections > Data sources,如图 6.1 所示。

图 6.1 Grafana选择数据源
默认已添加Prometheus,若未添加可点击右上角Add new data source,选择添加Prometheus。之后点击 prometheus 进行配置,如图 6.2 所示。
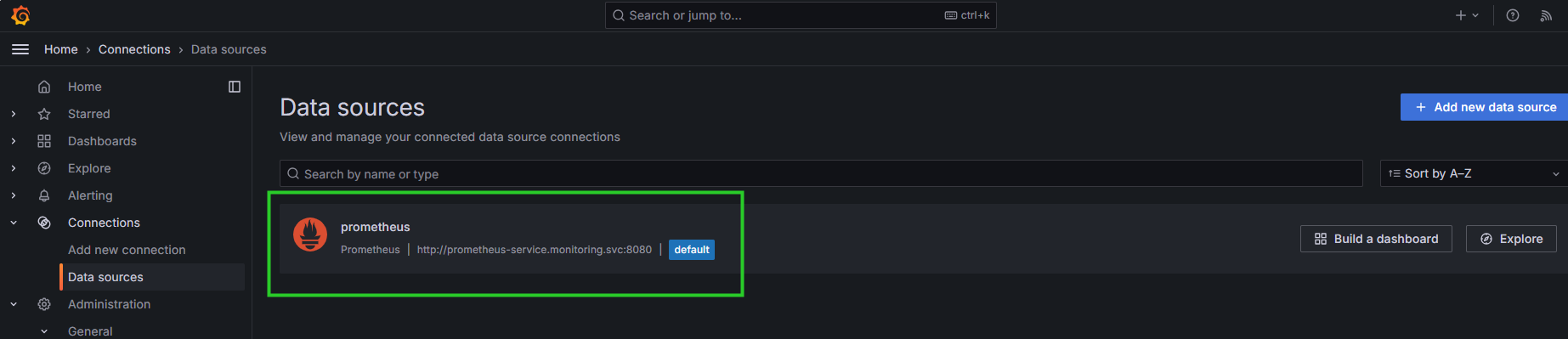
图 6.2 Grafana添加数据源
配置URL为http://<k8s_master_ip>:<prometheus_service_port>,其中prometheus_service_port默认为30000。 点击底部Save & test测试Prometheus连通性,提示添加数据库成功,如图 6.3 所示。
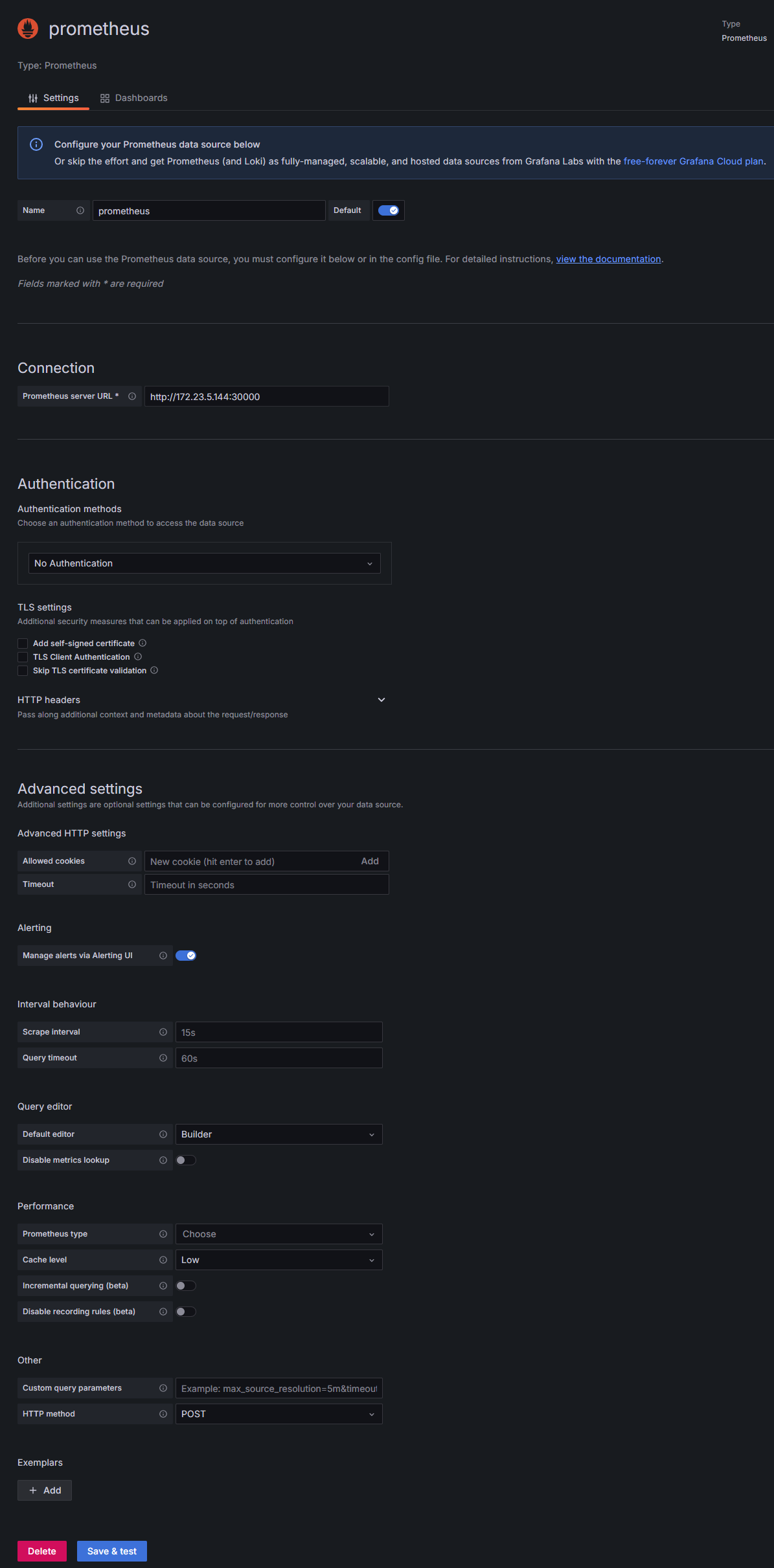
图 6.3 Grafana配置数据源URL
6.2. 添加监控模板
操作步骤
点击Dashboards图标,点击New,选择Import,如图 6.4 所示。

图 6.4 Grafana选择导入Json
点击Upload dashboard JSON file,上传mx-exporter/deployment/grafana-dashboard/MetaX-GPU-C500.json文件,如图 6.5 所示。
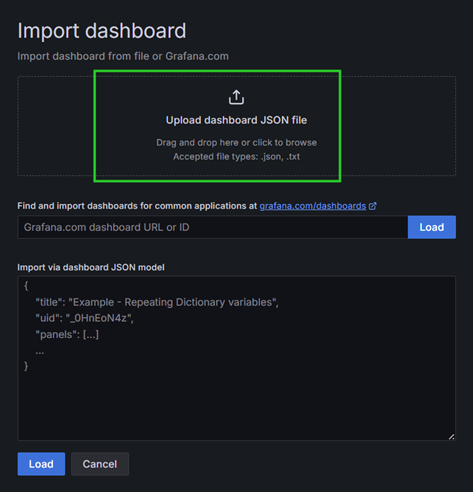
图 6.5 Grafana选择监控模板
数据源选prometheus,点击Import,如图 6.6 所示。

图 6.6 Grafana导入模板选择数据源
Dashboard中 server 选择 <hostname> 。 device 选择一个有效值,如
GPU0,可查看服务器GPU0基本指标信息。点击右上角时间下拉框,可选择展示特定时间段的信息,如图 6.7 所示。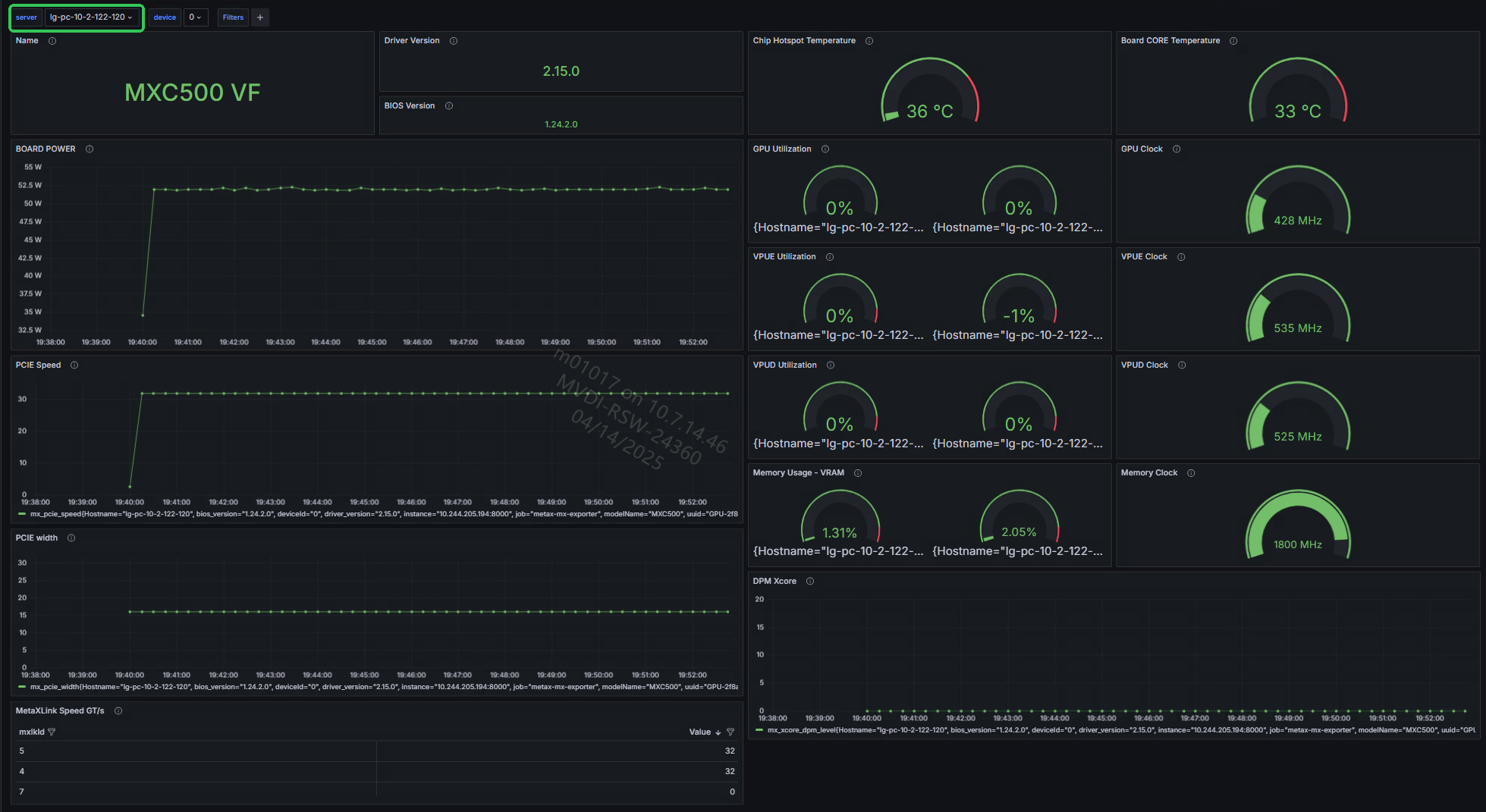
图 6.7 Grafana数据指标展示
6.3. 添加新的指标到监控面板
操作步骤
查看 mx-exporter/config/default-counters.csv 中的指标信息,根据实际情况在Grafana中添加想要监控的指标,如 pcie_peed。
有些指标仅为某些特定板卡型号中有,请注意筛选。 如图 6.8 所示,第一列加“#”的内容为注释行,如果不想收集某些指标,可用“#”将其注释掉。 指标标签为可用于过滤指标信息的标签,指标描述及指标标签均可编辑(标签不可更改顺序及增删),编辑后在Grafana中也需做相应更改。

图 6.8 default-counters中的指标说明
点击 Add 图标,下拉框中选择 Visualization ,如图 6.9 所示。
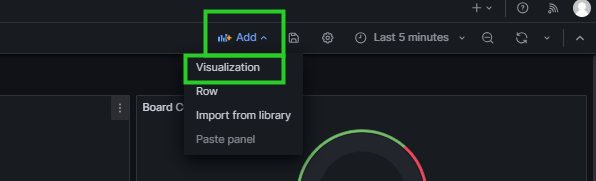
图 6.9 Grafana添加一个新指标图
点击数据源选择 prometheus ,在 Query 中搜索指标名称及筛选的Label,点击Run queries查看是否有数据显示,如展示符合预期,编辑右边的指标名称(Title)及描述(Description),点击Apply,如图 6.10 所示。
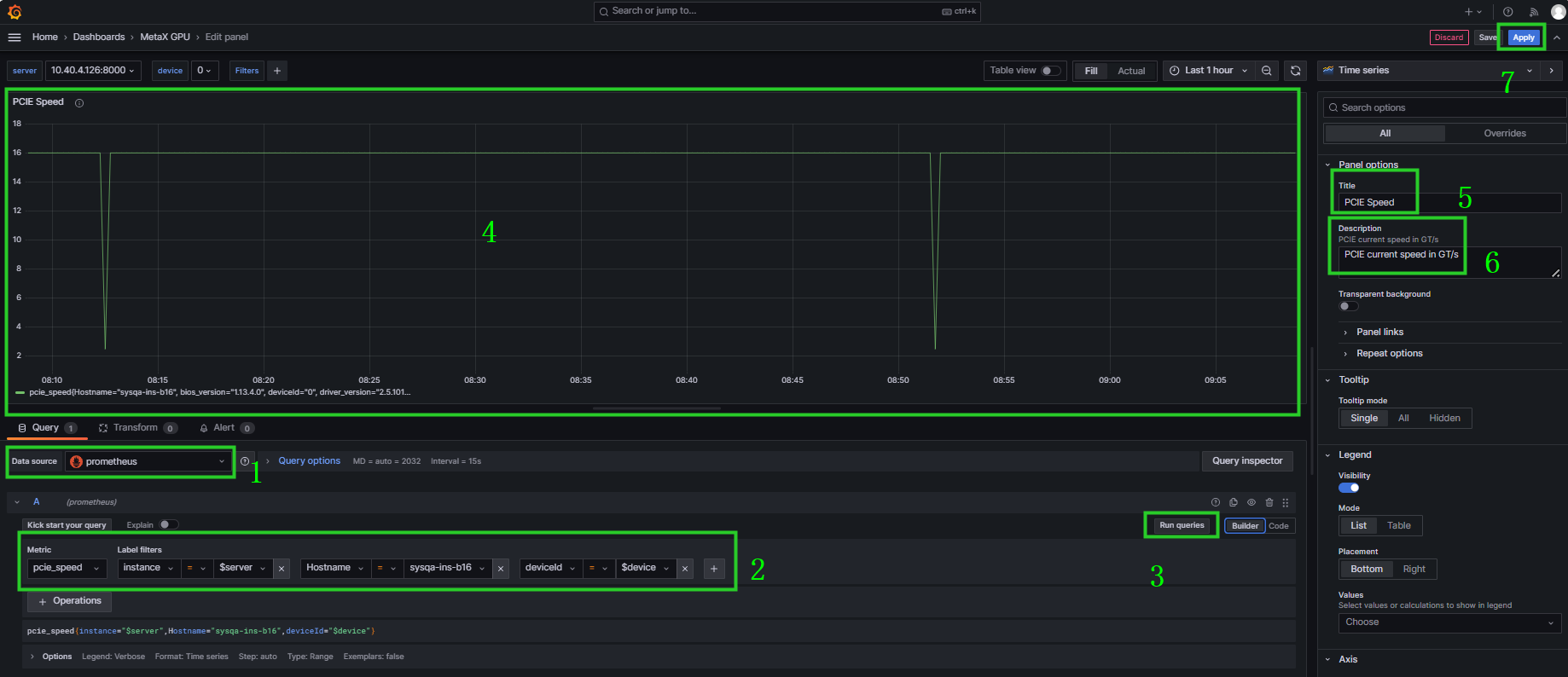
图 6.10 Grafana编辑新建的指标信息
(可选)点击面板右侧
 图标,选择 Edit ,可再次编辑面板信息,如图 6.11 所示。
图标,选择 Edit ,可再次编辑面板信息,如图 6.11 所示。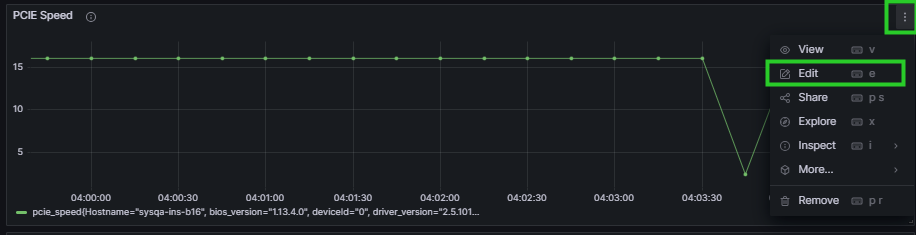
图 6.11 Grafana再次编辑指标信息
添加完所需指标后,可点击
 保存该面板,如图 6.12 所示。
保存该面板,如图 6.12 所示。新添加的指标面板在最上面,可根据需要将光标移动到指标名,当出现可移动图标时拖拽该指标移动位置。

图 6.12 保存新面板
在 Details 中描述新增或者修改的内容,点击 Save ,如图 6.13 所示。
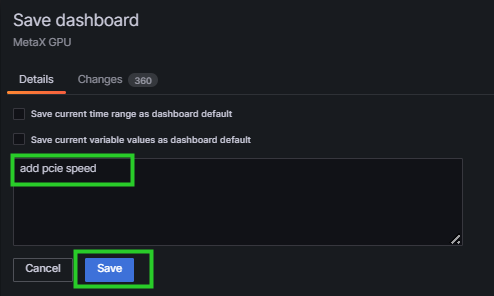
图 6.13 描述变更内容
点击面板中的
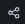 图标,选择 Export > Save to file 将当前视图保存为新的JSON文件,如图 6.14 所示。
图标,选择 Export > Save to file 将当前视图保存为新的JSON文件,如图 6.14 所示。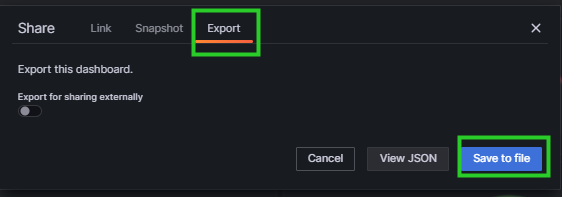
图 6.14 导出视图为JSON文件
6.4. 修改指标收集范围
若当前默认指标收集范围需要变更,可通过以下方法修改指标后再部署。
Helm 部署增加指标
修改mx-exporter/deployment/mx-exporter/helm/mx-exporter/templates/metrics-configmap.yaml, 去掉指标前的 “#” 以启用指标收集;在指标前加 “#” 将不会收集该指标数据。
YAML 部署增加指标
修改mx-exporter/deployment/mx-exporter/mx-exporter-daemonset.yaml下
mx-exporter-metrics-config-map中的指标内容,去掉指标前的 “#” 以启用指标收集;在指标前加 “#” 将不会收集该指标数据。
6.5. sGPU监控
为了监控集群中sGPU(sliced GPU)的使用,需要在部署前完成以下操作。
7. 告警规则
在Prometheus的配置文件mx-exporter/deployment/Prometheus/config-map.yaml中可定义告警规则,当环境中相关指标达到了触发告警的条件,则会展示告警信息。仅当环境相应指标恢复正常时,告警才可消除。
告警名称(alert) |
触发表达式(expr) |
严重程度定义(severity) |
|---|---|---|
GPU not available |
mx_gpu_state == 0 |
error |
Driver kernel error |
mx_kernel_error > 0 |
error |
MetaXLink speed anomaly |
mx_mxlk_bw > 0 AND mx_mxlk_speed < 32 |
error |
MetaXLink width anomaly |
mx_mxlk_width > 0 AND mx_mxlk_width < 16 |
error |
PCIe speed anomaly |
mx_gpu_usage > 0 AND mx_pcie_speed < 32 |
error |
PCIe width anomaly |
mx_gpu_usage > 0 AND mx_pcie_speed < 16 |
error |
Over temperature |
mx_chip_hotspot_temp > 110 OR mx_board_core_temp > 115 |
error |
High temperature |
mx_chip_hotspot_temp > 100 OR mx_board_core_temp > 100 (for 30s) |
warning |
XCore DPM downgrade |
mx_gpu_usage > 0 AND mx_xcore_dpm_level < 5 |
error |
7.1. Prometheus UI告警展示
当mx-exporter和Prometheus部署完毕后,在浏览器输入<k8s_master_ip>:<prometheus_service_port>,prometheus_service_port默认为30000。 打开Prometheus UI界面,点击Alerts栏,可查看所有定义的告警信息。
如图 7.1 所示,可以看到规则 metax gpu alerting rules 中定义的告警列表。
当无告警发生时,会显示为绿色且有0条活跃的告警信息;当有告警发生时,告警条目为红色,并显示告警数量。
点击下拉框可看到告警详细信息描述,包括告警名称,触发表达式,严重程度,标签信息,状态,告警产生时间点等。
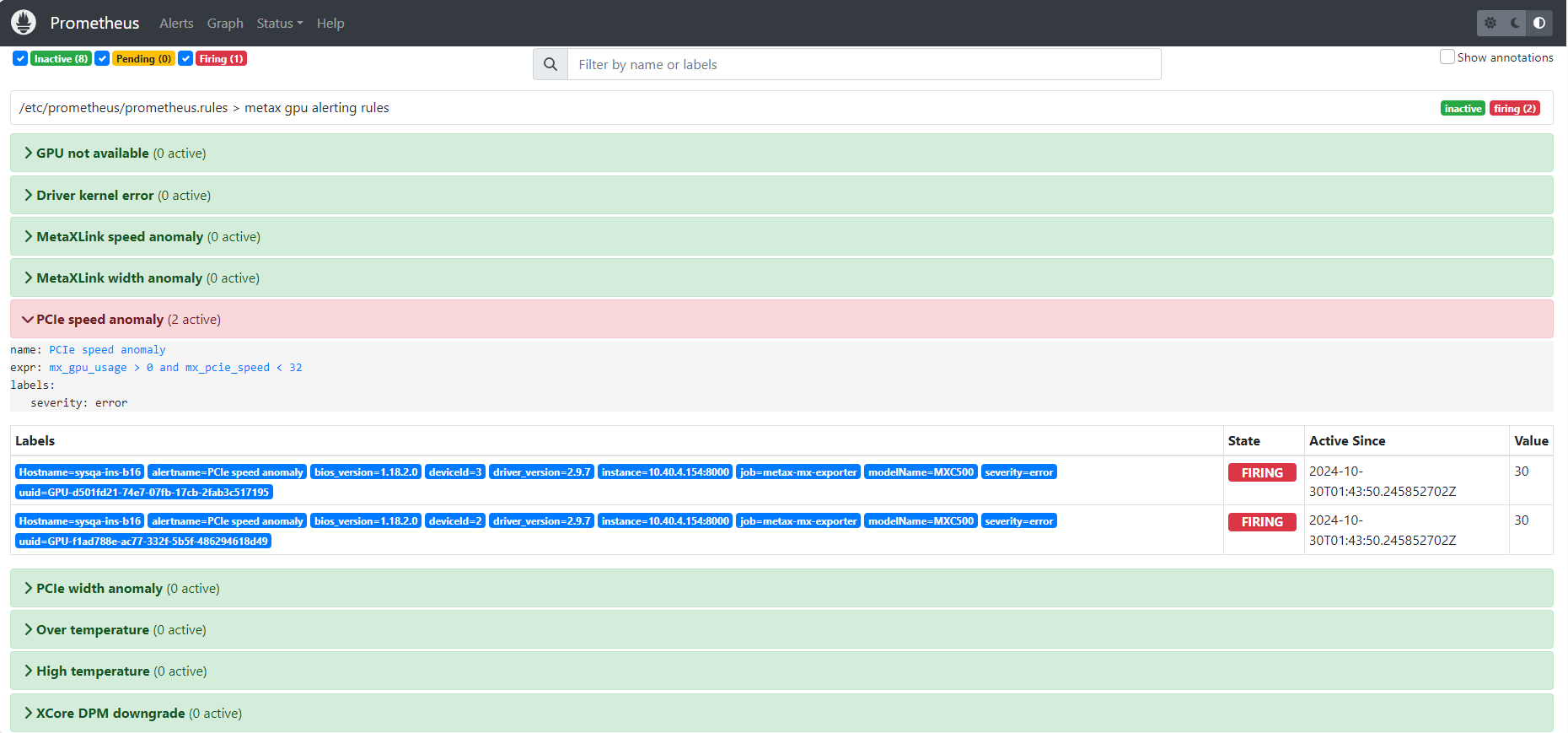
图 7.1 Prometheus告警展示
7.2. Grafana告警展示
上传告警展示文件 mx-exporter/deployment/grafana-dashboard/MetaX-Alert.json,操作步骤参见 6.2 添加监控模板。
当有告警发生时,展示页面如图 7.2 所示。左边区域展示了告警列表信息,右边区域展示各条目告警持续时间。
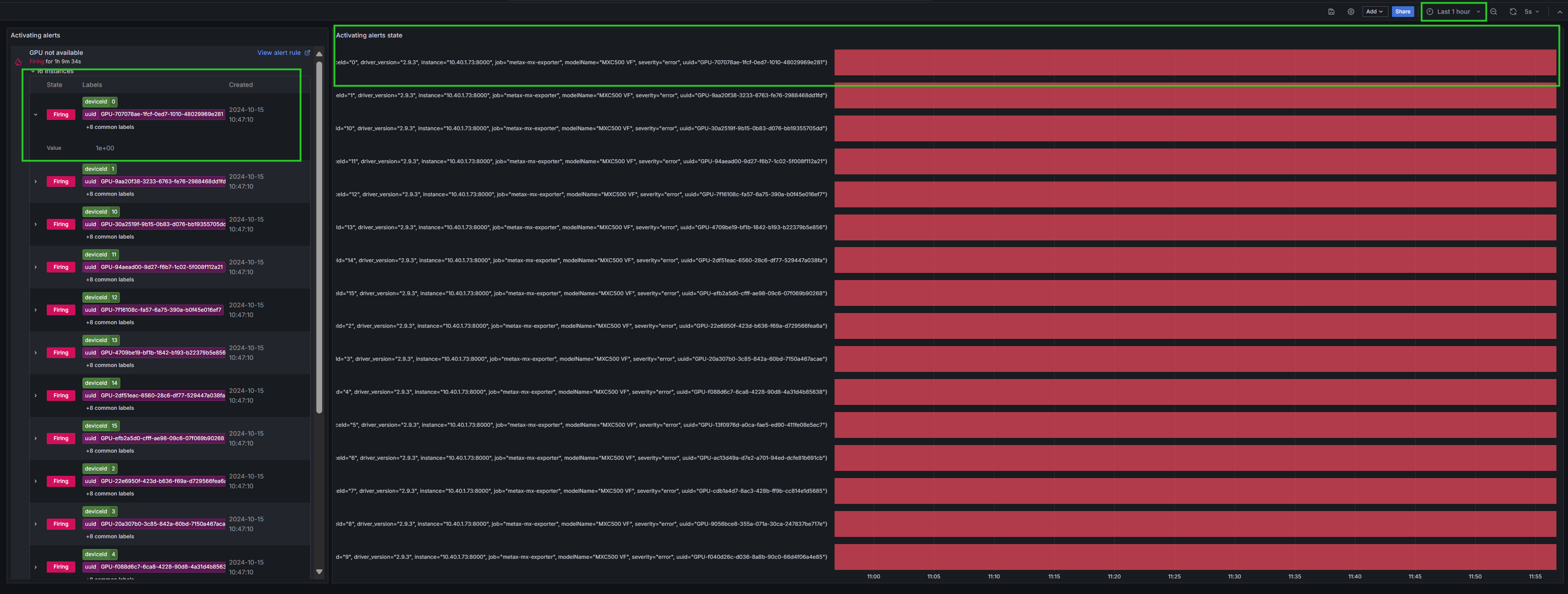
图 7.2 Grafana告警展示
点击图 7.2 中左边区域的右上角 View alert rule,可查看告警详细信息,如图 7.3 所示。

图 7.3 告警详细信息
8. 兼容性
8.1. MXMACA-C500-K8s-0.8.2
mx-exporter工具中指标名称新增mx_前缀。如需解决兼容性问题,请采取以下任一方法:
若为Helm方式部署mx-exporter,需修改mx-exporter/deployment/mx-exporter/helm/mx-exporter/templates/metrics-configmap.yaml,去掉指标名的mx_前缀,再部署mx-exporter,操作步骤参见 3.1 Helm方式部署。
若为YAML方式部署mx-exporter,需修改mx-exporter/deployment/mx-exporter/mx-exporter-daemonset.yaml,去掉指标名的mx_前缀,再部署mx-exporter,操作步骤参见 3.2 YAML方式部署。
若正常部署新版本mx-exporter,需要给正在使用的Grafana监控模板文件中的指标名加上mx_前缀。
若正常部署新版本mx-exporter,可使用Prometheus relabeling功能,在Prometheus配置文件mx-exporter/deployment/prometheus/config-map.yaml中的
job_name: "metax-mx-exporter"下,增加如下metric_relabel_configs配置来批量更改标签名称。metric_relabel_configs: - source_labels: [__name__] regex: mx_(.*) target_label: __name__
备注
使用Prometheus relabeling功能删除mx_前缀时,需相应删除mx-exporter/deployment/Prometheus/config-map.yaml中告警表达式的mx_前缀,告警才可正常触发。
9. 常见问题
9.1. pod不是Running状态
可用
kubctl describe pod <pod_name> -n metax-monitor查看pod详细信息。可用
kubectl logs <pod_name> -n metax-monitor查看container log信息。
9.2. 导入配置文件后Grafana无数据显示
首先需要确认mx-exporter有没有收集到数据,可用
kubectl logs <mx-exporter-pod_name> -n metax-monitor查看log中有无异常。确认mx-exporter/mx-exporter/deployment/prometheus/config-map.yaml中mx-exporter的
job_name: "metax-mx-exporter"。浏览器输入<k8s_master_ip>:<prometheus_service_port>,prometheus_service_port默认为30000。 登录Prometheus UI,在搜索框中输入已知指标,如gpu_usage,点击Execute按钮查看exporter中数据是否已经导入Prometheus中,或者点击Execute按钮左边的open metrics explorer查询已知指标是否存在。
再次确认Grafana指标展示界面中选择的 server 为
<hostname>, device 选择有效值,如0。