1. 概述
mcPyTorch在PyTorch的基础上增加了MXMACA® 后端,支持使用MXMACA硬件加速PyTorch中各类计算任务。
当前发布包含以下版本安装包:
PyTorch 2.1.2 + Python 3.8
PyTorch 2.1.2 + Python 3.10
PyTorch 2.4.0 + Python 3.8
PyTorch 2.4.0 + Python 3.10
PyTorch 2.6.0 + Python 3.10
2.4.0之前版本的mcPyTorch支持x86_64/Arm架构下Ubuntu 18/20/22以及CentOS 8/9系统上运行。 2.4.0及之后版本的mcPyTorch支持x86_64/Arm架构下Ubuntu 20/22以及CentOS 8/9系统上运行。 mcPyTorch的具体支持功能,参见 3 功能支持。
2. 快速安装
2.1. 基于pip安装
2.1.1. 环境准备
Python
匹配目标安装包的Python版本(例如,Python 3.8或者Python 3.10)
MXMACA环境
安装Driver软件包以及MXMACA SDK软件包
cu-bridge环境
在安装MXMACA环境到 /opt/maca/ 目录后,参考 cu-bridge 的使用指南安装并配置cu-bridge环境,将cu-bridge安装到 /opt/maca/tools/ 目录下。可以检查以下文件是否存在,并确认cu-bridge环境是否准备完毕:
/opt/maca/tools/cu-bridge/bin/cucc /opt/maca/tools/cu-bridge/tools/cmake_maca
支持PyTorch Extension的cu-bridge环境不需要安装CUDA Toolkit。
如果不使用PyTorch Extension功能可以不配置cu-bridge环境。 PyTorch Extension功能,参见官网描述。
2.1.2. 开始安装
PyTorch安装包以maca-pytorch${pytorch_version}-py${python_version}-${MXMACA_version}-${arch_info}.tar.xz格式命名。 例如,PyTorch 2.1 + Python 3.10版本的安装包名称为:maca-pytorch2.1-py310-2.24.0.1-x86_64.tar.xz。
获取PyTorch安装包后,解压可以得到包括mcPyTorch、mcTorchvison、mcTorchaudio、mcApex、mcFlashattn在内的whl格式安装包。 PyTorch 2.1版本的安装包中提供了mcTriton的安装包。
操作步骤
安装方式同标准whl包。
安装mcPyTorch:
python -m pip install torch-*.whl
安装mcFlashattn:
python -m pip install flash_attn-*.whl
(可选)安装mcTorchvision:
python -m pip install torchvision-*.whl
(可选)安装mcTorchaudio:
python -m pip install torchaudio-*.whl
(可选)安装mcApex:
python -m pip install apex-*.whl
(可选)安装mcTriton:
python -m pip install triton-*.whl
2.1.3. 验证安装
操作步骤
运行前设置环境变量:
export MACA_PATH=/opt/maca/ export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${MACA_PATH}/ompi/lib:${LD_LIBRARY_PATH} export MACA_CLANG_PATH=${MACA_PATH}/mxgpu_llvm/bin
如果使用PyTorch Extension功能,需要安装cu-bridge环境,并额外设置以下环境变量:
export CUDA_PATH=/opt/maca/tools/cu-bridge/ export CUCC_PATH=/opt/maca/tools/cu-bridge/ export PATH=${CUCC_PATH}/tools:${CUCC_PATH}/bin:${PATH}
执行以下命令:
python -c "import torch; print(torch.ones(2).cuda())"
会得到如下打印输出,即表明安装成功:
tensor([1., 1.], device='cuda:0')
2.1.4. 如何卸载
卸载方式同标准whl包。
操作步骤
卸载mcPyTorch:
python -m pip uninstall torch
2.2. 使用Docker运行
MXMACA容器镜像是以离线形式发布。用户可在随本文档发布的软件包中找到相关压缩包。 本文档中以mxc500-torch2.6-py310-mc2.33.0.3-ubuntu24.04-amd64.container.xz为例,用户应根据实际收到的软件包版本对版本字段进行相应替换。
操作步骤
获取MXMACA容器镜像,执行以下命令,完成容器镜像的加载:
docker load < ./mxc500-torch2.6-py310-mc2.33.0.3-ubuntu24.04-amd64.container.xz
在Docker容器中使用板卡,使用全部曦云系列GPU(以C500为例):
docker run -it --device=/dev/mxcd --device=/dev/dri --group-add video mxc500-torch2.6-py310:mc2.33.0.3-ubuntu24.04-amd64 /bin/bash
3. 功能支持
mcPyTorch以兼容PyTorch的原生使用方式为设计目标。大部分情况下,用户可以参考官方文档获得mcPyTorch的使用方式。
本章参照PyTorch官方文档内容,介绍mcPyTorch各模块使用的兼容性和注意事项。其中:
支持:支持并兼容原生用法
部分支持:部分支持原生用法,或API行为和原生用法有区别
3.1. torch
支持
3.2. torch.nn
支持
3.2.1. Convolution Layers
支持:
nn.Conv1d
nn.Conv2d
nn.Conv3d
nn.ConvTranspose1d
nn.ConvTranspose2d
nn.ConvTranspose3d
nn.LazyConv1d
nn.LazyConv2d
nn.LazyConv3d
nn.LazyConvTranspose1d
nn.LazyConvTranspose2d
nn.LazyConvTranspose3d
nn.Unfold
nn.Fold
备注
默认情况下,conv的FP32数据类型没有使用TF32而使用FP32进行计算加速,可以使用 torch.backends.cudnn.allow_tf32=True 打开。
3.2.2. Recurrent Layers
支持:
nn.RNNBase
nn.RNN
nn.LSTM
nn.GRU
nn.RNNCell
nn.LSTMCell
nn.GRUCell
3.2.3. Dropout Layers
支持:
nn.Dropout
nn.Dropout1d
nn.Dropout2d
nn.Dropout3d
nn.AlphaDropout
nn.FeatureAlphaDropout
备注
PyTorch中Dropout类运算随机行为和硬件参数相关,因此MXMACA设备和CUDA设备上默认运行结果随机行为不一致。
3.3. torch.nn.functional
支持
3.4. torch.Tensor
支持
3.5. Tensor Attributes
支持
3.6. Tensor Views
支持:
basic slicing and indexing
adjoint
as_strided
detach
diagonal
expand
expand_as
movedim
narrow
permute
select
squeeze
transpose
t
T
H
mT
mH
real
imag
view_as_real
unflatten
unfold
unsqueeze
view
view_as
unbind
split
hsplit
vsplit
tensor_split
split_with_sizes
swapaxes
swapdims
chunk
indices (sparse tensor only)
values (sparse tensor only)
3.7. torch.amp
支持
3.8. torch.autograd
支持
3.9. torch.library
支持
3.10. torch.cuda
3.10.1. cuda
支持:
StreamContext
can_device_access_peer
current_blas_handle
current_device
current_stream
default_stream
device
device_count
device_of
get_sync_debug_mode
init
ipc_collect
is_available
is_initialized
set_device
set_stream
set_sync_debug_mode
stream
synchronize
OutOfMemoryError
部分支持:
get_arch_list
返回
['sm_80']。模拟CUDA capability==8.0时的行为。get_device_capability
返回
(8. 0)。模拟CUDA capability==8.0时的行为。get_device_name
返回MXMACA硬件相应设备名,而非NVIDIA设备名例如:NVIDIA A100-PCIE-40GB。
get_device_properties
返回对应CUDA架构描述的MXMACA架构信息。
get_gencode_flags
返回
"-gencode compute=compute_80,code=sm_80"。模拟CUDA capability==8.0时的行为。
3.10.2. Random Number Generator
支持:
get_rng_state
get_rng_state_all
set_rng_state
set_rng_state_all
manual_seed
manual_seed_all
seed
seed_all
initial_seed
3.10.3. Communication collectives
支持:
comm.broadcast
comm.broadcast_coalesced
comm.reduce_add
comm.scatter
comm.gather
3.10.4. Streams and events
支持:
Stream
Event
3.10.5. Memory management
支持:
empty_cache
list_gpu_processes
mem_get_info
memory_stats
memory_summary
memory_snapshot
memory_allocated
max_memory_allocated
reset_max_memory_allocated
memory_reserved
max_memory_reserved
set_per_process_memory_fraction
memory_cached
max_memory_cached
reset_max_memory_cached
reset_peak_memory_stats
caching_allocator_alloc
caching_allocator_delete
get_allocator_backend
change_current_allocator
3.10.6. Tools Extension
支持:
nvtx.mark
nvtx.range_push
nvtx.range_pop
3.10.7. Jiterator (beta)
不支持:
jiterator._create_jit_fn
jiterator._create_multi_output_jit_fn
3.11. torch.backends
3.11.1. torch.backends.cuda
支持:
torch.backends.cuda.is_built
返回
True,表示mcPyTorch包含MXMACA backends。torch.backends.cuda.matmul.allow_tf32
torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction
torch.backends.cuda.matmul.allow_bf16_reduced_precision_reduction
torch.backends.cuda.cufft_plan_cache
torch.backends.cuda.math_sdp_enabled
torch.backends.cuda.enable_math_sdp
torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=True, enable_mem_efficient=True)
目前仅支持
enable_math=True
3.11.2. torch.backends.cudnn
支持:
torch.backends.cudnn.is_available
torch.backends.cudnn.enabled
torch.backends.cudnn.allow_tf32
torch.backends.cudnn.deterministic
torch.backends.cudnn.benchmark
torch.backends.cudnn.benchmark_limit
torch.backends.cudnn.version
备注
默认情况下,torch.backends.cudnn.allow_tf32为False,torch.backends.cuda.matmul.allow_tf32为False。
3.11.3. torch.backends.mps
支持:
torch.backends.mps.is_available
torch.backends.mps.is_built
备注
mcPyTorch不包含MPS backends,上述两个接口总是返回False。
3.11.4. torch.backends.mkl
支持:
torch.backends.mkl.is_available
torch.backends.mkl.verbose
3.11.5. torch.backends.mkldnn
支持:
torch.backends.mkldnn.is_available
torch.backends.mkldnn.verbose
3.11.6. torch.backends.openmp
支持:
torch.backends.openmp.is_available
3.11.7. torch.backends.opt_einsum
3.12. torch.distributed
支持
3.13. torch.distributions
支持
3.14. torch._dynamo
支持
3.15. torch.fft
支持
3.16. torch.fx
支持
3.17. torch.jit
支持
3.18. torch.linalg
支持
3.19. torch.package
支持
3.20. torch.profiler
支持
3.21. torch.nn.init
支持
3.22. torch.onnx
支持
3.23. torch.optim
支持
3.24. Complex Numbers
支持
3.25. DDP Communication Hooks
支持
3.26. torch.random
支持
3.27. torch.masked
支持
3.28. torch.nested
支持
3.29. torch.sparse
支持
3.30. torch.Storage
支持
3.31. torch.testing
支持
3.32. torch.utils.benchmark
支持
3.33. torch.utils.bottleneck
支持
3.34. torch.utils.checkpoint
支持
3.35. torch.utils.cpp_extension
支持
备注
Extension的编译需要cu-bridge的支持,请参考相关文档配置cu-bridge环境。
使用mcPyTorch 2.4.0及之后版本的cpp_extension功能时,x86下与PyTorch官方行为相同,编译环境需满足GCC/G++ 9.0或更高版本;Arm下编译环境需满足GCC/G++ 7.x。
3.36. torch.utils.data
支持
3.37. torch.utils.jit
支持
3.38. torch.utils.model_zoo
支持
3.39. torch.utils.tensorboard
支持
3.40. Type Info
支持
3.41. torch.__config__
支持
4. 常用环境变量
4.1. PYTORCH_DEFAULT_NCHW
对于四维Tensor,为获得更好的性能,mcPyTorch在其从CPU向device侧搬运时会更改layout为torch.channels_last (NHWC)。该环境变量用于恢复官方默认行为,即搬运时不做额外的layout改变逻辑。
备注
偶然情况下,上述默认更改layout的转换可能因为viewop的使用引起以下报错:
Runtime Error: view size is not compatible with input tensor's size and stride(...). Use .reshape(...) instead.
这时可以参考提示信息使用reshape替换viewop;也可设置 export PYTORCH_DEFAULT_NCHW=1 恢复官方默认行为,避免这种报错。
设置:
export PYTORCH_DEFAULT_NCHW=1取消设置:
unset PYTORCH_DEFAULT_NCHW
示例:
设置
unset PYTORCH_DEFAULT_NCHW,运行程序结果如下:>>> import torch >>> a = torch.rand(2,3,4,5).cuda() >>> a.shape torch.Size([2, 3, 4, 5]) >>> a.stride() (60, 1, 15, 3)
设置
export PYTORCH_DEFAULT_NCHW=1,运行程序结果如下:>>> import torch >>> a = torch.rand(2,3,4,5).cuda() >>> a.shape torch.Size([2, 3, 4, 5]) >>> a.stride() (60, 20, 5, 1)
4.2. TORCH_ALLOW_TF32_CUBLAS_OVERRIDE
torch.backends.cuda.matmul.allow_tf32 默认为 False。设置该环境变量时控制 torch.backends.cuda.matmul.allow_tf32 默认为 True。
设置:
export TORCH_ALLOW_TF32_CUBLAS_OVERRIDE=1取消设置:
unset TORCH_ALLOW_TF32_CUBLAS_OVERRIDE
4.3. PYTORCH_ALLOW_CUDA_CUDNN_TF32
torch.backends.cudnn.allow_tf32 默认为 False。设置该环境变量时控制 torch.backends.cudnn.allow_tf32 默认为 True。
设置:
export PYTORCH_ALLOW_CUDA_CUDNN_TF32=1取消设置:
unset PYTORCH_ALLOW_CUDA_CUDNN_TF32
5. PyTorch精度对比工具
PyTorch精度对比工具支持在PyTorch脚本中插入接口,用来记录和保存PyTorch的Python op API的输入输出tensor信息,并提供接口比较不同device输出的tensor的精度异同,从而方便在复杂网络中定位到MXMACA算子相对CUDA算子哪个算子产生了较大的误差及误差是多少。
5.1. 接口介绍
5.1.1. start_record
start_record(enabled: bool, output_dir: str = "./record_dir", record_level: int = 2, record_stack = True, record_input: bool = True, record_output: bool = True, op_range: List[str] = [], op_list: List[str] = [], skip = 0, process_group = None, ranks = []) -> None
功能描述:初始化精度工具,从start_record开启之后的Python算子会被record。
参数说明:
enabledbool类型,控制是否启用精度工具,初始化工具配置,默认值为
True。output_dirstring类型,record数据存储路径,默认为存储在当前路径的record_dir目录。
record_levelint类型,控制dump算子的输入和输出信息的详细程度,取值包括
2、1和0,默认为2。Level 2:表示dump该算子输入输出的所有信息,包含Tensor的完整信息。
Level 1:表示不会dump Tensor的完整信息,只包含Tensor的概述信息(我们定义的TensorSummary类型包含了Tensor的数据类型、形状、步长、元素最大值和最小值)。
Level 0:表示不会dump算子的输入输出信息。
record_stackbool类型,是否record算子的Python端调用栈信息,默认为
True。反向算子是hook函数的调用栈,随算子的输入或者输出信息一起保存到一个文件。record_inputbool类型,是否record算子的输入信息,默认为
True。record_outputbool类型,是否record算子的输出信息,默认为
True。op_rangeList[str]类型,控制record信息范围。只能传空列表、包含Python端API信息的字符串或者None,长度为2的列表,例如:
["torch.nn.Conv1d.6.fwd", "torch.nn.AdaptiveAvgPool2d.256.bwd"]、[None, "torch.nn.AdaptiveAvgPool2d.256.bwd"]、["torch.nn.Conv1d.6.fwd", None]。None表示不限制record的开始或者结束边界。
字符串由3部分组成:算子的API官方名称、按照执行时间顺序对应的是第几个前向算子、前向(fwd)还是反向(bwd)。该控制范围前闭后开,默认为空列表,表示不限制record范围。
p_listList[str]类型,控制record的具体前反向算子。字符串命名规则同
op_range,并且支持指定某一类API。 例如:api_list=["relu"]会record包含torch.relu、torch.relu\_、torch.Tensor.relu、torch.nn.ReLU和torch.nn.functional.relu\_等前反向算子。 默认为空列表,表示不限制算子。skipint类型,表示每间隔
skip次op后record一次。默认为0。process_grouptorch.distributed.ProcessGroup类型,表示需要record的进程组。默认为None,表示只会record默认进程组,如果不是分布式场景,不需要设置该参数。 有关进程组的详细内容,参见PyTorch官方分布式模块相关文档。ranksList[int]类型,表示需要record进程组里面的哪些进程。默认为空列表,表示不限制。
5.1.2. record
record(enabled: bool, output_dir: str = "./record_dir", record_level: int = 2, record_stack = True, record_input: bool = True, record_output: bool = True, op_range: List[str] = [], op_list: List[str] = [], skip = 0, process_group = None, ranks = []) -> None
功能描述:上下文管理器,方便控制record范围,功能同 5.1.1 start_record。
参数说明:同 5.1.1 start_record。
5.1.3. record_switch
功能描述:开关record功能。
参数说明:
enabledbool类型,是否开启record数据,无默认值。
5.1.4. gen_report
gen_report(dir0: str, dir1: str, output_dir: str = "./") -> None
功能描述:输入record生成的算子tensor目录,生成逐tensor的误差、tensor的概述信息和相关调用栈信息的excel表格报告。
参数说明:
dir0string类型,device0的record数据路径,无默认值。
dir1string类型,device1的record数据路径,无默认值。
output_dirstring类型,比较结果的输出目录。默认为输出到当前目录。
5.2. 生成文件介绍
PyTorch精度工具,当开启 start_record 后会在指定的 output_dir 下生成pt文件,使用 gen_report 分析不同device的 output_dir 可以生成对比的excel表格。
pt文件:pt文件有自己的命名方式,例如:
torch.nn.Conv1d.6.fwd指的是前向第6个算子,这个算子是torch.nn.Conv1d
torch.nn.AdaptiveAvgPool2d.256.bwd,指的是反向第256个算子,算子是torch.nn.AdaptiveAvgPool2d
excel表格:如下图,生成的excel表格中包括device0和device1对应算子输入输出tensor的数据类型,shape,最大最小值以及diff1(相对误差)diff2(标准差),和op的Python调用栈。

图 5.1 生成文件
5.3. 使用流程
分别在device0(如CUDA-GPU或CPU)和device1(如MXMACA-GPU)上运行精度比较工具,保存网络训练中间数据。
再次运行精度比较工具比对device0和device1保存下来的数据,计算误差并输出比对结果。
gen_report分析比对结果,分析的过程类似二分法,设置一个比较大的skip数(加快速度),找出导致误差大的算子。 如果没有找到误差大的算子,则需要重新调整record范围减小skip数,再次record。 如果找到误差大的算子,说明这个op_range存在误差大的算子,但由于skip存在这个误差大的算子只是skip的区间末尾,所以应该将skip设置为0找到具体某个op导致的精度误差。
下面是一个简单的测试用例, start_record 和 record_switch(False) 之间的op将被record:
import torch
import torch.nn as nn
import copy
from maca_tools import accuracy
dtype = torch.float16
shape, out_c, k, s, p, d, g = (256, 1, 3600), 4, 5, 1, 2, 1, 1
input = torch.randn(shape, dtype = dtype, device="cpu")
input_d = input.clone().cuda()
m = nn.Conv1d(shape[1], out_c, k, stride = s, padding = p, dilation = d, groups = g, dtype = dtype)
m_d = copy.deepcopy(m)
m_d = m_d.to("cuda")
accuracy.start_record(record_level=2)
output = m_d(input_d)
accuracy.record_switch(False)
如果执行kernel过多,则需要重新调整record范围减小skip数再次record。
下述案例为skip=10,表示每间隔10次op后record一次,统计到torch.nn.Conv1d.6.fwd结束。
import torch
import torch.nn as nn
import copy
from maca_tools import accuracy
dtype = torch.float16
shape, out_c, k, s, p, d, g = (256, 1, 3600), 4, 5, 1, 2, 1, 1
input = torch.randn(shape, dtype = dtype, device="cpu")
input_d = input.clone().cuda()
m = nn.Conv1d(shape[1], out_c, k, stride = s, padding = p, dilation = d, groups = g, dtype = dtype)
m_d = copy.deepcopy(m)
m_d = m_d.to("cuda")
accuracy.start_record(record_level=2, skip=10, op_range=[None, "torch.nn.Conv1d.6.fwd"])
output = m_d(input_d)
accuracy.record_switch(False)
在CUDA运行时,安装maca_tools的方法如下:
通过以下命令解压MXMACA torch的wheel包,在当前目录下会得到maca_tools的文件夹。
unzip torch-*.whl在CUDA环境下,将上述解压获得的maca_tools拷贝到环境中wheel包存放的目录。
cp -r maca_tools/ $(pip show torch | grep Location | awk '{print $2}')
其余部分CUDA运行方式与MXMACA相同,同上所述。
5.4. 注意事项
保证两次record过程调用的算子数量和算子顺序一致。
为使比较结果更准确,需提前消除网络计算中的随机性和因算子算法差异导致的比对误差等干扰因素。
如果存在有算子API在工具初始化之前被导入,可能会导致错过Python接口劫持时机,进而导致这些Python接口不会被record。
算子可能record不完整,具体表现在:该工具只能record Python侧op,如果这个Python op对应的是多个C++拼接实现的算子,只是record最后那个C++算子的输出。
目前不能单独record反向算子的相关信息,必须带上相应的前向算子。
开启record功能的网络性能会有一定程度下降。保存信息庞大,用户需预留足够空间存放。
本工具跟PyTorch版本绑定,不保证其他版本的PyTorch也能使用。
分布式多卡训练时,start_record需要在init_process_group初始化之后执行。
网络脚本中如果直接调用torch._C._VariableFunctions.xxx或者torch._C._TensorBase.xxx这两种PyTorch内部使用的接口,目前无法record。
暂不支持record少数不在API返回值中的原位算子的输出,如: torch.Tensor.__setitem__、torch._amp_foreach_non_finite_check_and_unscale_。
暂不支持record少数不涉及计算的tensor构造类API,包括torch.tensor、torch.empty、torch.empty_like、torch.empty_strided、torch.empty_quantized。
暂不支持record torch.Tensor.__getitem__。
不支持record工具初始化所在进程的子进程和子线程的算子的输入输出信息。
不支持导出torch.Generator类型的算子参数的完整信息。
不支持record稀疏Tensor、量化Tensor、NestedTensor及相关算子的输入输出信息。
不支持record通信原语。
不支持record torch.jit.script后的ScriptModule和ScriptFunction的输入和输出信息。
由于torch.Tensor.uniform\_.fwd算子的input为随机值,因此可以忽略。
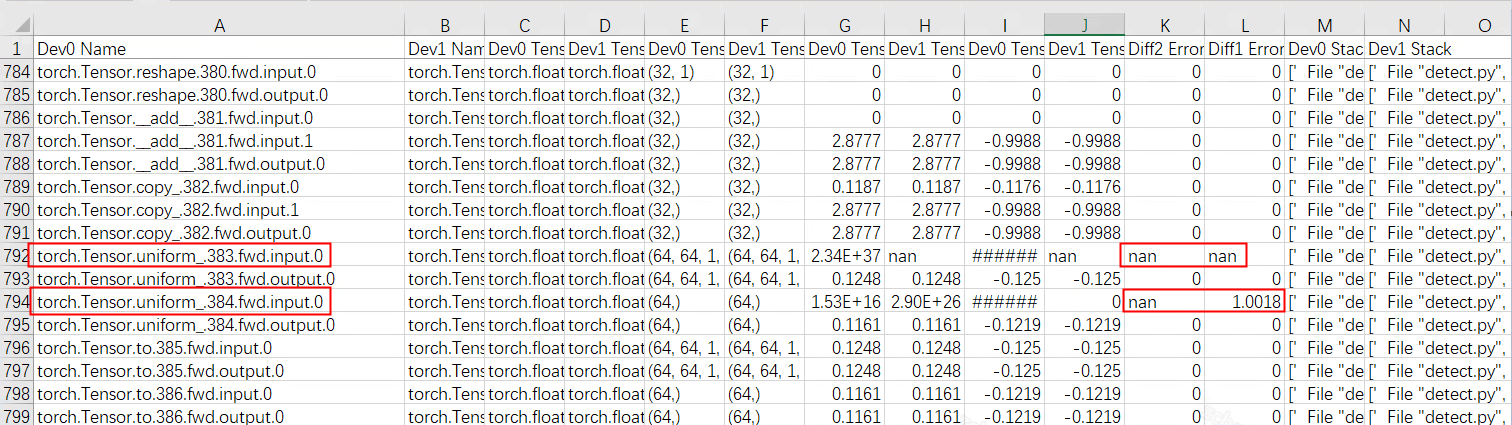
图 5.2 input示例