1. 概述
本文档描述了如何通过Warm Reset复位GPU卡来恢复业务。
1.1. 应用场景
当服务器上的一张或者多张GPU卡出现不可通过软件恢复的问题,且服务器主机及操作系统没有明显异常的情况下,可以尝试使用Warm Reset复位出现问题的GPU卡来恢复业务,以此避免重启服务器主机,节省运维时间和人力成本。
一般情况下,Warm Reset适用以下场景:
非显存坏页的不可自动纠正的RAS错误
VBIOS更新后立即生效
GPU卡之间MetaXLink出现异常,比如连接断开或降速等
其它未知问题引起的GPU卡异常,hang机或不响应等
备注
由于Warm Reset依赖GPU的部分软硬件功能,并且和服务器、操作系统以及出现问题时的上下文都紧密相关,无法保证在所有实际场景下都能操作成功并解决问题,建议Warm Reset后对所有GPU卡都进行基本的测试后再运行业务。如果Warm Reset后有异常,请立即冷重启服务器。
2. 软件栈版本依赖
使用Warm Reset需要软件栈版本满足以下条件:
VBIOS ≥ 1.12.0.0
KMD ≥ 2.4.1
mx-smi ≥ 2.1.5
libvirt ≥ 0.8.0(虚拟机部署下的host端环境)
3. 适配服务器
由于Warm Reset在PCIe接口上和服务器紧密相关,并不能保证在所有服务器上都能正常工作。有些服务器存在Warm Reset后GPU卡无法识别或者无法正常工作等问题,所以对于不同的服务器,有可能需要特殊的适配才能使用。以下是经过测试,推荐使用的服务器列表:
服务器型号 |
Warm Reset功能 |
已知问题 |
|---|---|---|
H3C UniServer R5300 G6 |
支持 |
无 |
4. 物理机场景
4.1. 基本原理
MetaX GPU卡的Warm Reset是指在不重启主机电源或操作系统的情况下进行GPU卡的复位。在确认GPU卡空闲无任务运行的情况下,通过mx-smi工具下发Warm Reset命令来触发GPU卡的复位,目前支持以下使用部署场景:
单主机GPU卡无互联环境,如图 4.1,即GPU卡之间没有通过MetaXLink互联。
直接使用mx-smi对出现问题的GPU卡进行Warm Reset复位。
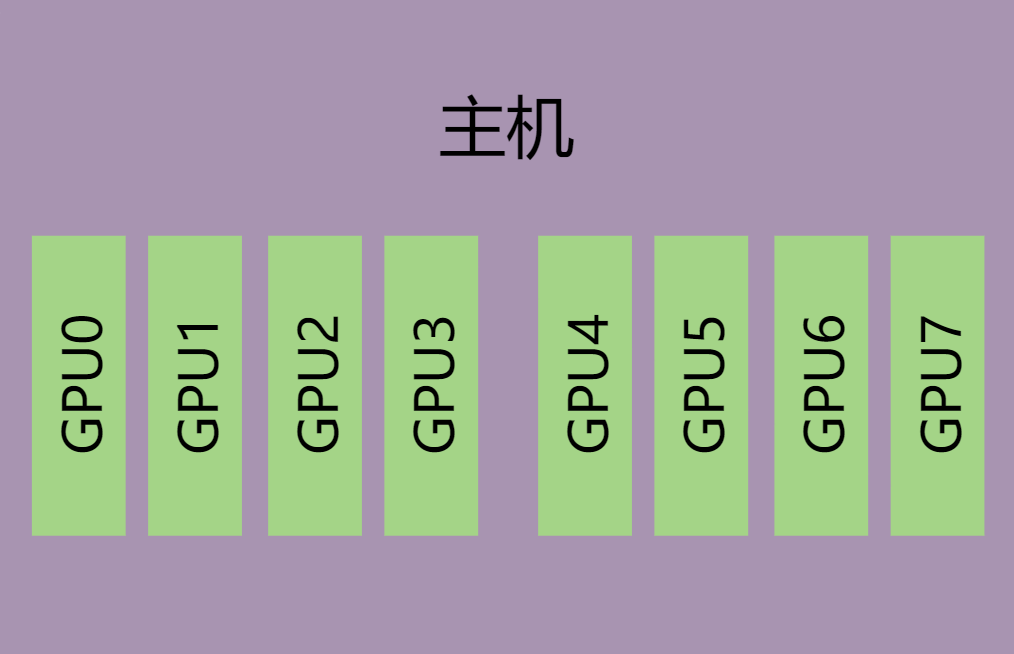
图 4.1 单主机无互联
单主机多GPU卡互联环境,如图 4.2,即GPU卡之间通过MetaXLink互联。
Warm Reset在执行过程中会将MetaXLink硬件复位,GPU卡之间的MetaXLink会和对端GPU卡断开连接。在有MetaXLink互联的单机多卡环境中,如果有GPU卡需要Warm Reset,互联群组内所有GPU卡都需要同时进行Warm Reset。
使用mx-smi下发Warm Reset命令时,KMD驱动会判断GPU卡是否存在MetaXLink互联并自动完成互联群组内所有GPU卡的Warm Reset,且在Warm Reset完成后,KMD会自动恢复群组内所有GPU卡的MetaXLink互联。
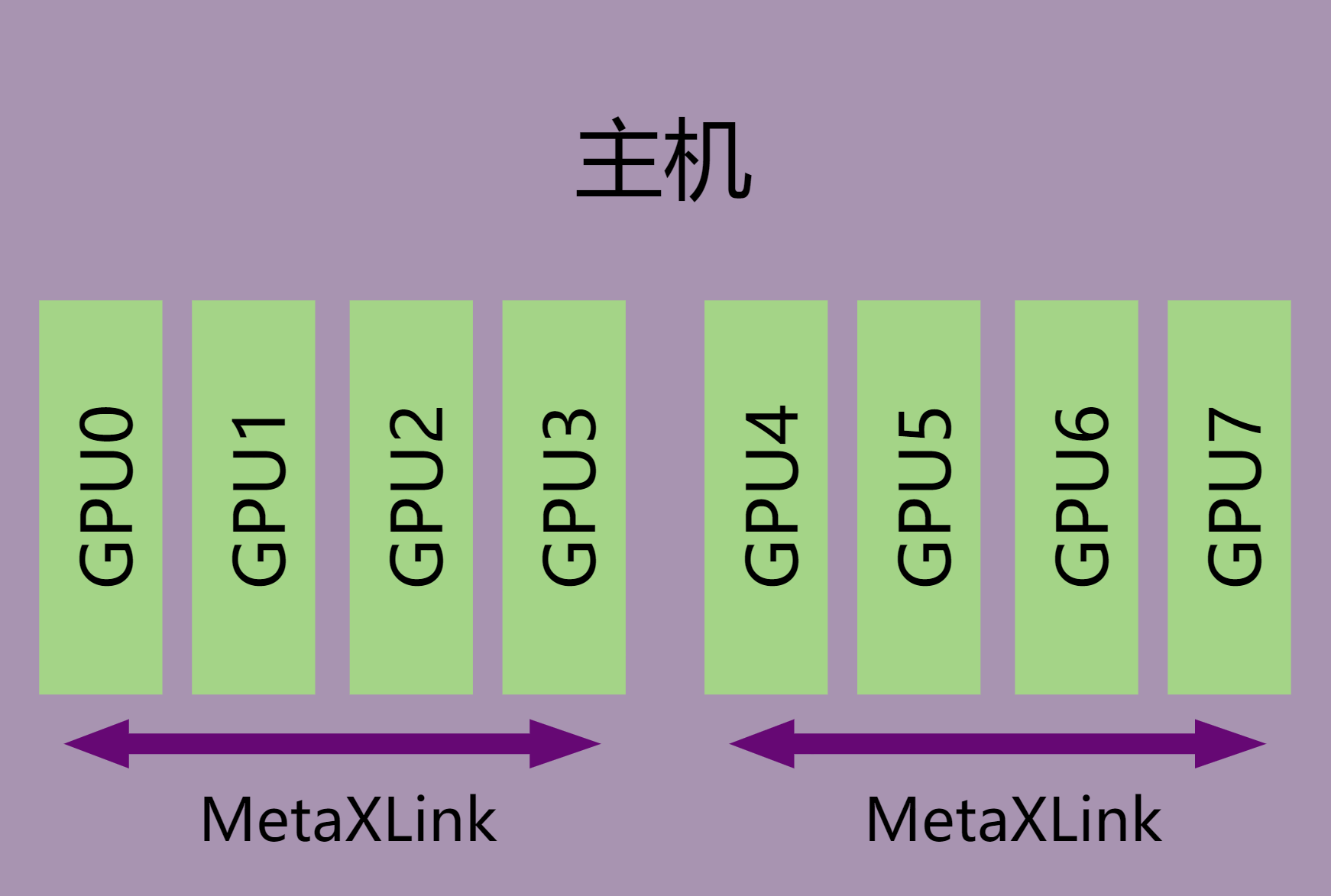
图 4.2 单主机多卡互联
多主机多GPU卡互联环境,如图 4.3,即整个GPU卡的互联群组分布在多台主机上。单主机内的GPU卡之间有MetaXLink互联,不同主机上的GPU卡之间也存在MetaXLink互联。
Warm Reset在执行过程中会将MetaXLink硬件复位,GPU卡之间的MetaXLink会和对端GPU卡断开连接。 在有MetaXLink互联的多机多卡环境中,如果有GPU卡需要Warm Reset,可以对互联群组内多台主机上的所有GPU卡都进行Warm Reset,也可以仅对出现GPU异常的主机上的所有GPU进行Warm Reset,再对跨机互联的MetaXLink端口进行单独处理。 其中,对互联群组内多台主机上的所有GPU卡都进行Warm Reset的运维影响比较大。
若选择对互联群组内多台主机上的所有GPU卡都进行Warm Reset
在每台主机上,选一张卡下发Warm Reset命令,同一主机上有MetaXLink互联的其它GPU卡会自动进行Warm Reset。 等所有主机都完成Warm Reset之后,各主机内的MetaXLink会自动恢复连接,跨主机之间的MetaXLink则按需下发连接命令来实现跨主机之间的MetaXLink互联。
若选择仅对出现GPU异常的主机上的所有GPU进行Warm Reset
在出现GPU异常的主机上,选一张卡下发Warm Reset命令,这台主机上有MetaXLink互联的其它GPU卡会自动进行Warm Reset。 等完成Warm Reset之后,出现GPU异常的主机内的MetaXLink会自动恢复连接。跨主机之间的MetaXLink则需要在其他无GPU卡异常的主机上先发送连接断开命令,然后再按需下发连接命令来实现跨主机之间的MetaXLink互联。
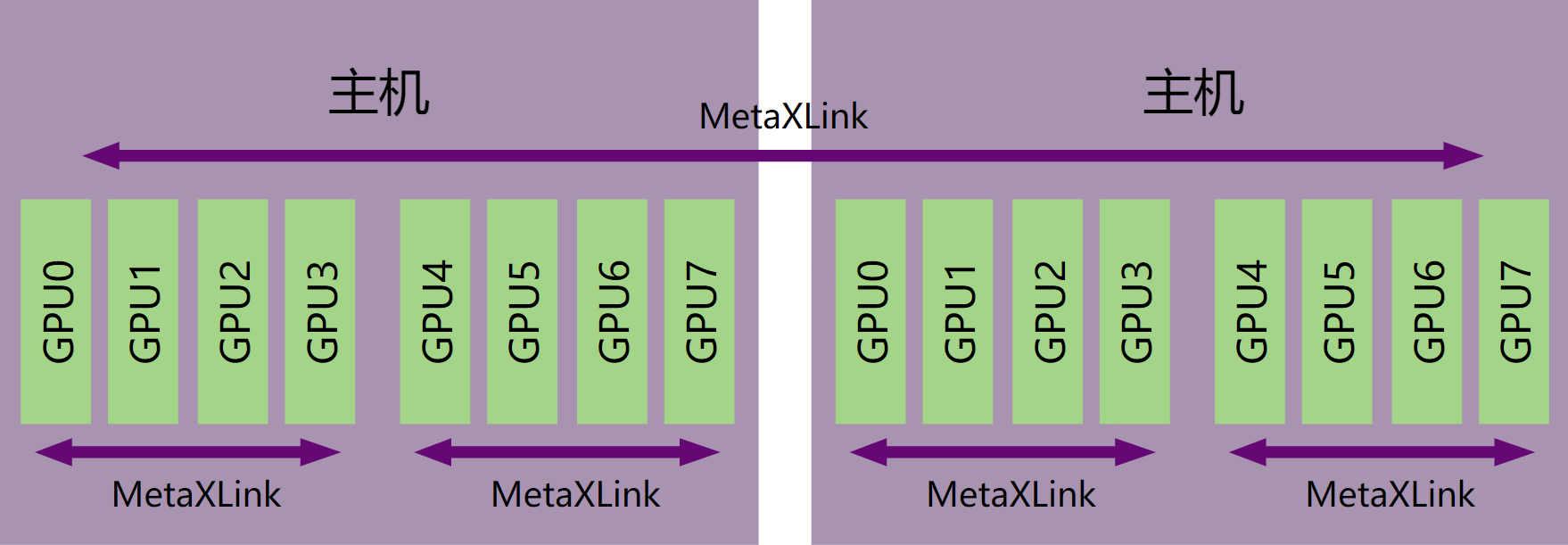
图 4.3 多主机多卡互联
4.2. 操作步骤
单主机上,带MetaXLink互联与不带MetaXLink互联的GPU卡在执行Warm Reset时的操作步骤相同。多主机上,若不同主机上的GPU卡间存在MetaXLink互联,可以按照单主机的方式仅在出现GPU异常的主机上执行Warm Reset,也可以在所有主机上同时执行Warm Reset。
确保当前环境下没有业务在使用metax驱动。通过
mx-smi查看是否有进程在运行。mx-smi
或者查询GPU驱动引用计数。执行以下命令,确认metax引用行的最后一列是否显示为0。若不为0,则表示还有业务在引用metax驱动,需要将业务强制退出。
lsmod | grep metax
通过错误日志或者mx-smi定位出错GPU卡的node ID。
mx-smi -L通过mx-smi工具,执行Warm Reset。
mx-smi -r -i <node ID>
备注
执行Warm Reset命令需要root权限。
有MetaXLink互联的GPU卡群组可以指定群组内的任意node ID。
如果不知道node ID,可直接使用
mx-smi -r -i all命令对所有GPU卡进行Warm Reset。如果执行Warm Reset命令后console显示了错误信息,或者该命令无法结束,请重启主机。
等待最长90秒钟后Warm Reset命令会执行结束。查看GPU卡是否复位成功,执行以下命令查看所有GPU卡是否都可用。
mx-smi -L备注
执行Warm Reset命令后的90秒等待时间内,不要对GPU再下发任何其他操作,等检查到GPU复位完成后再进行操作。
如果Warm Reset完成后,通过mx-smi命令查看的拓扑连接不正常,或者dmesg有错误日志,请冷重启主机。
(可选)多主机MetaXLink互联环境下,如果仅在出现GPU异常的主机上执行了Warm Reset,需要在其他无GPU异常的互联主机上发送MetaXLink连接断开命令。连接断开命令可通过管理软件自动下发,也可手动下发。以下为手动下发的命令:
metalink_train 7
备注
如果条件允许,多主机MetaXLink互联环境中,请尽量选择对所有主机同时执行Warm Reset的方式,可靠性相对更高。
多主机MetaXLink互联环境下完成Warm Reset后,按需进行MetaXLink的跨机互联,操作步骤和冷重启主机后一样。
5. PF透传虚拟机场景
5.1. 基本原理
将GPU卡PF直接透传给虚拟机应用场景下,需要管理员在host端部署一个Warm Reset监控工具,该工具会在管理平台对虚拟机开机和关机操作时进行Warm Reset相关操作。
当用户在虚拟机里面运行任务遇到GPU卡严重故障问题,并提示需要Warm Reset操作恢复后,用户可以在虚拟机里面发起Warm Reset操作(实际为Warm Reset请求),然后将虚拟机关机并重新开机。
在host端启动虚拟机前,Warm Reset监控工具检测到GPU卡有Warm Reset请求标记,会对GPU卡进行Warm Reset复位。
在所有带有Warm Reset请求标记的GPU卡完成Warm Reset操作之后,host端会正式启动虚拟机,用户继续在虚拟机里面运行任务。
备注
host端的Warm Reset监控工具无法获取到完整MetaXLink互联信息,在host启动虚拟机前,Warm Reset监控工具会对属于该虚拟机下的所有GPU卡进行必要的状态检查,只有当前状态满足Warm Reset条件了,监控工具才会对GPU卡进行Warm Reset操作。
5.2. 操作步骤
第一次部署时,管理员在host安装mxhv工具。
rpm系列:
rpm -i mxhv-xxx.rpm
deb系列:
dpkg -i mxhv-xxx.deb
备注
必须在host安装mxhv工具,因为在虚拟机里触发Warm Reset命令后,都是由host端的mxhv工具执行Warm Reset复位。
不要在host安装GPU KMD驱动或其他MXMACA工具,防止host端GPU KMD驱动对透传GPU卡有影响。
管理员将用户需要的GPU卡透传配置到虚拟机。比如,在虚拟机里面需要使用MetaXLink互联功能,则需要将有MetaXLink互联的GPU卡全部透传到虚拟机,以保证GPU在虚拟机里面的MetaXLink互联拓扑完整性。
用户通过虚拟机管理平台启动虚拟机。
用户需要Warm Reset时,通过mx-smi工具,找出需要Warm Reset的GPU卡的node ID(有MetaXLink互联的GPU卡群组可以指定群组内的任意node ID),然后在虚拟机下执行如下命令:
mx-smi -r -i <node ID>
备注
如果执行Warm Reset命令后console显示了错误信息,或者该命令无法结束,请重启主机。
如果不知道node ID,可直接使用
mx-smi -r -i all命令对所有GPU卡进行Warm Reset。
用户在虚拟机里面执行poweroff命令,关闭虚拟机。
poweroff
备注
必须使用poweroff命令,不能用reboot等其它重启命令。
用户通过虚拟机管理平台再次启动虚拟机。
备注
在host端启动虚拟机前,Warm Reset监控工具会对GPU卡进行Warm Reset复位,完成后才会正式启动虚拟机,如果5分钟后虚拟机启动没有成功,请重启主机。
虚拟机启动成功后,执行以下命令查看所有GPU卡和拓扑连接是否恢复,同时确认dmesg没有错误日志。
mx-smi topo -m
备注
如果Warm Reset完成后,通过mx-smi命令查看的拓扑连接不正常,或者dmesg有错误日志,请冷重启主机。
用户继续执行业务。
6. 虚拟化SRIOV硬切分场景
6.1. 基本原理
在GPU卡开启SRIOV硬件切分虚拟化之后,一张GPU卡会虚拟出多个vGPU卡。当需要对GPU卡进行Warm Reset复位时,需要在host上通过mx-smi命令对GPU卡进行Warm Reset复位。
但在对GPU卡进行Warm Reset卡复位操作前,必须停止该GPU卡虚拟的所有vGPU卡上的业务。
6.2. 操作步骤
在host上执行mx-smi命令查看GPU卡node ID,并确认该GPU卡虚拟出来的vGPU卡信息。
mx-smi -L停止该GPU卡虚拟的所有vGPU卡上的业务。在使用vGPU卡的环境中执行mx-smi命令,查看Process列表是否有业务进程还在vGPU卡上运行,若还有业务进程在运行,请退出相关业务进程。
mx-smi
备注
如果是vGPU透传虚拟机的使用场景,需要在虚拟机中vGPU业务停止之后,对虚拟机进行关机操作。
执行以下命令,在host上通过mx-smi工具对GPU卡执行Warm Reset操作:
mx-smi -r -i <node ID>
备注
执行Warm Reset操作的node ID为GPU物理卡编号,不是vGPU虚拟卡编号。
如果执行Warm Reset命令后console显示了错误信息,或者该命令无法结束,请重启主机。
等待大约90秒钟后查看GPU卡是否复位成功,在host上执行以下命令查看GPU卡及其vGPU卡是否恢复,同时确认dmesg没有错误日志。
mx-smi -L备注
执行Warm Reset命令后的90秒等待时间内,不要对GPU再下发任何其他操作,等检查到GPU复位完成后再进行操作。
如果Warm Reset完成后,通过mx-smi命令查看的GPU及其vGPU卡不正常,或者dmesg有错误日志,请冷重启主机。
用户继续在vGPU卡上执行业务。
7. 已知问题和限制
Warm Reset不能解决服务器硬件故障问题。
Warm Reset不能解决操作系统故障问题。
Warm Reset依赖GPU的一些软硬件功能,在GPU异常的情况下,有可能Warm Reset不能正常执行,需要重启服务器。
未经测试的服务器可能存在Warm Reset之后丢卡、GPU卡PCIe链路异常、服务器异常重启等现象(参见表 3.1 推荐使用的服务器列表)。
在同一个互联的GPU卡群组上存在老版本VBIOS(<1.12.0.0)和新版本VBIOS(≧1.12.0.0)的GPU卡混插,会导致老版本GPU卡启动失败,且也无法升级VBIOS,需将MetaXLink断开后才能正常工作。这种情况需要联系沐曦技术支持工程师。
在同一个互联的GPU卡群组上老版本VBIOS(<1.12.0.0)升级到新版本VBIOS(≧1.12.0.0)时,必须将所有老版本VBIOS的GPU卡的VBIOS全部升级后,才能进行Warm Reset或重启主机的操作,避免出现上述混插场景。
如果要升级的VBIOS所需的GPU PCIe地址空间比升级前的VBIOS要大(比如bar空间变大,或者从不支持VF的VBIOS升级到支持VF的VBIOS),不能通过Warm Reset使新的VBIOS生效,需要重启服务器。
如果通过Warm Reset复位GPU卡方式让新VBIOS版本生效,必须保证新版本VBIOS的BAR size配置和旧版本VBIOS的BAR size配置一致。
支持PF卡Warm Reset,不支持VF卡的Warm Reset。