1. 概述
本文档详细描述了曦云® 系列GPU的驱动安装方法,主要包括GPU内核驱动安装,以及GPU固件升级等内容。
本文档主要适用于以下人员:
服务器管理员
曦云系列GPU用户
2. 安装与维护
若无特殊说明,本章以曦云C500为例。
2.1. 用户须知
2.1.1. 系统支持范围
目前已支持的CPU架构和内核版本,参见表 2.1。
CPU架构 |
操作系统 |
内核版本 |
状态 |
|---|---|---|---|
x86_64 |
Ubuntu 18.04 |
5.4.0-42-generic |
支持 |
5.4.0-131-generic |
|||
x86_64 |
Ubuntu 20.04 |
5.4.0-144-generic |
支持 |
5.15.0-58-generic |
|||
x86_64 |
Ubuntu 22.04 |
5.15.0-72-generic |
支持 |
5.15.0-112-generic |
|||
x86_64 |
CentOS 8 |
4.18.0-240.el8.x86_64 |
支持 |
x86_64 |
CentOS 7 |
4.19.0-1.el7.elrepo.x86_64 |
支持加载Docker Container形式 |
5.14.0 |
|||
x86_64 |
BCLinux R8 U2 |
4.19.0-240.23.11.el8_2.bclinux.x86_64 |
支持 |
x86_64 |
CC Linux |
5.15.131-2.cl9.x86_64 |
支持 |
x86_64 |
Kylin V10 SP2 |
4.19.90-24.4.v2101.ky10.x86_64 |
支持 |
x86_64 |
ALinux3 |
5.10.134-13.1.al8.x86_64 |
支持 |
x86_64 |
CTYun 23.01 |
5.10.0-136.12.0.86.ctl3.x86_64 |
支持 |
x86_64 |
KeyarchOS 5.8 |
4.18.0-477.27.1.3.kos5.x86_64 |
支持 |
x86_64 |
RockyOS 9.2 |
5.14.0-284.11.1.el9_2.x86_64 |
支持 |
x86_64 |
Debian 10 |
5.10.0-0.deb10.28-amd64 |
支持 |
x86_64 |
TencentOS 3.1 |
5.4.119-19.0009.54 |
支持 |
x86_64 |
TencentOS 3.1 |
5.4.119-19.0009.44 |
支持 |
2.1.2. 安装包说明
曦云系列GPU所提供的驱动安装包通过run安装文件发布。以Ubuntu系统为例,Driver软件包所包含的内容参见表 2.2。
文件名 |
说明 |
|---|---|
metax-linux_x.x.x-xxx_amd64.deb |
曦云系列GPU KMD驱动、工具及相关配置文件 |
mxgvm_x.x.x-xxx_amd64.deb |
曦云系列GPU Virtualization Manager、工具及相关配置文件 |
mxfw_x.x.x.x.all.deb |
曦云系列GPU固件包 |
mxsmt_x.x.x.x.amd64.deb |
mx-smi系统管理工具,MXSML系统管理库 |
2.2. 物理机上安装驱动和固件
在安装了Linux系统的物理机上,驱动和固件的安装流程如图 2.1 所示。
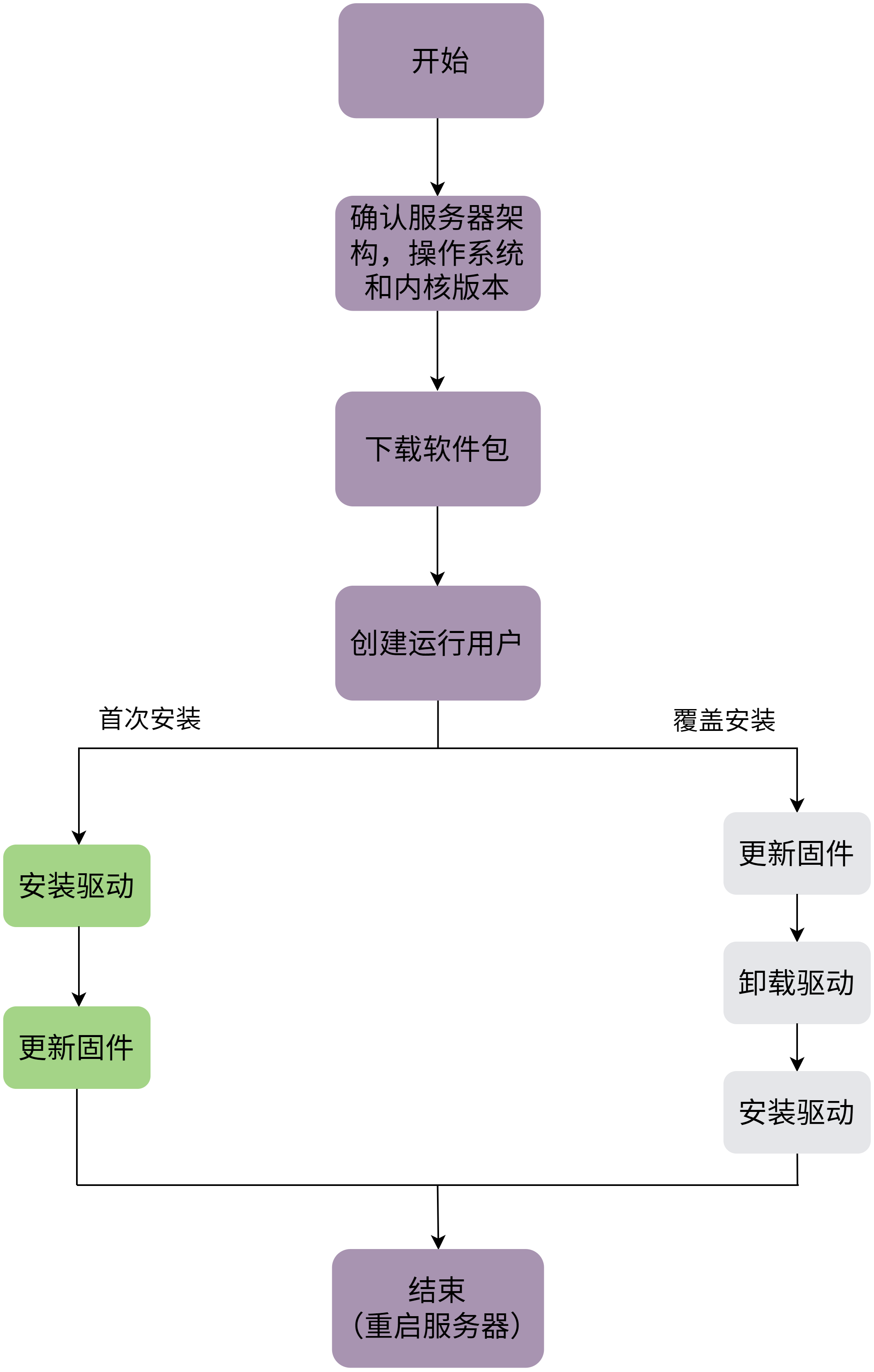
图 2.1 软件包安装流程
备注
首次安装场景:服务器上从未安装过驱动,板卡出厂时默认已安装好固件。
覆盖安装场景:服务器上安装过驱动且未卸载,当前要再次安装驱动。
2.2.1. 确认服务器架构,操作系统和内核版本
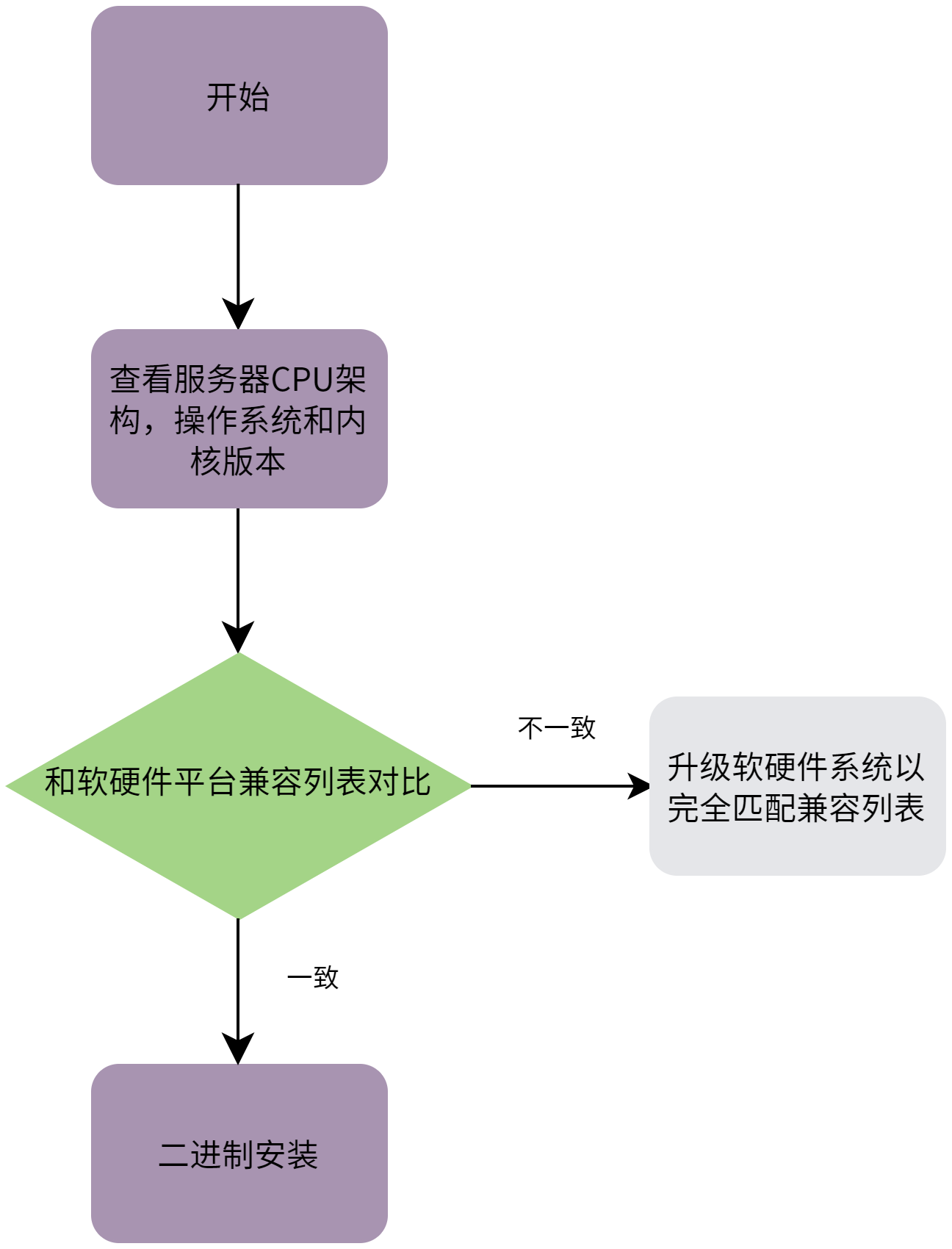
图 2.2 确认服务器架构,操作系统和内核版本
操作步骤
2.2.2. 创建运行用户
运行用户是软件包安装完成后,使用曦云系列GPU的终端用户。安装用户是配置环境,安装软件包的用户,必须有sudo权限,一般为服务器管理员。
运行用户可以为root用户或者非root用户。如果服务器管理员对运行用户有用户权限控制或多用户隔离的需求,可创建非root用户作为运行用户。 将运行用户加入video组即可将其创建为非root用户(udev规则配置文件默认将曦云系列GPU使用权限归属于video组内)。
操作步骤
例如,创建运行用户user并将其创建为非root用户。
创建运行用户。
sudo adduser [user]
将运行用户加入video组。
sudo usermod -a -G video [user]
备注
(可选)沐曦驱动安装包也支持自定义用户组和自定义权限。
比如指定用户组为 root,权限为0666,安装run文件时添加以下参数:
sudo ./metax-driver-xxx.run -- [other-options] -G root -P 0666
自定义用户组和权限后,需要将运行用户添加到对应的用户组,确保运行用户能正常访问GPU。
2.2.3. 安装驱动
2.2.3.1. 安装环境确认
系统兼容性要求
若曦云系列GPU无法识别为PCIe设备(可通过
lspci | grep 9999进行查看),需关闭BIOS里兼容性支持模块(CSM)选项。若PCIe BAR需要支持4GB以上地址空间,需打开BIOS里Large Bar选项。
每张曦云系列GPU板卡需要三个BAR,空间大小分别为1 MB,8 MB和64 GB。
环境检查
序号 |
检查项目 |
检查命令 |
说明 |
|---|---|---|---|
1 |
服务器CPU架构 |
|
对照表 2.1 软硬件平台兼容列表,确认CPU架构,操作系统和内核版本是否在列表中。若有任何一项不匹配,则需更新环境。详细信息参见 2.2.1 确认服务器架构,操作系统和内核版本。 |
2 |
操作系统 |
|
|
3 |
内核版本 |
|
|
4 |
系统是否安装过驱动 |
|
|
5 |
板卡是否正常在位 (以曦云C500为例) |
|
如果服务器上有N(N>0)张曦云C500板卡,回显中含 例如,若服务器上有2张板卡且都正常在位,则回显信息如下所示:
|
6 |
udev配置 |
|
|
7 |
虚拟化 |
|
支持SRIOV功能的曦云系列GPU板卡需要分配额外的PCI BAR空间给VF,VF所需BAR空间的大小是PF的8倍,如果系统无法分配地址空间,对应的设备将无法正常工作。 |
8 |
IOMMU配置 |
|
|
9 |
是否允许第三方驱动加载 (仅适用于SLES-15系统) |
|
对于SLES-15系统,如在加载metax驱动时提示 如需开机自动加载metax驱动,则需添加/etc/modprobe.d/10-unsupported-modules.conf文件,并在该文件中填写 |
2.2.3.2. 二进制文件直接安装
操作步骤
将驱动的run安装文件下载到目标机器上,进入文件所在目录,执行以下命令安装驱动:
sudo ./metax-driver-mxc500-x.x.x.x-deb-x86_64.run -- -f
备注
若VBIOS固件和驱动版本不兼容,安装metax-linux/mxgvm包时会出现如下回显信息:
Notice: Please upgrade vbios first, otherwise normal business functions will not be supported
针对C550X-DF16CubeDC-32这种拓扑类型,需要执行以下命令安装驱动:
sudo ./metax-driver-mxc500-x.x.x.x-deb-x86_64.run -- -f -p topo_df=1
(可选)对于RHEL/CentOS/Rocky Linux及其延伸版本(ALINUX3等),在安装完驱动后需要执行以下命令,将驱动集成到initramfs中,以确保驱动的加载顺序:
sudo dracut -f
重启服务器。
sudo reboot执行以下命令,查询驱动安装信息。
lsmod | grep metax
定义环境变量并执行以下命令,若回显信息列出所有曦云GPU的信息,则metax驱动工作正常。
export PATH=$PATH:/opt/mxdriver/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/mxdriver/lib mx-smi
2.2.4. 更新固件
曦云系列GPU采用沐曦带内管理工具mx-smi对固件进行升级。mx-smi工具自动安装在驱动安装包的/opt/mxdriver/bin目录下。关于mx-smi工具,参见《曦云® 系列通用计算GPU mx-smi使用手册》。
操作步骤
检查更新的VBIOS固件文件mxvbios-xxx.bin(例如mxvbios-1.1.1.0-17-C500.bin)已安装到Linux的/lib/firmware/metax/mxc500目录下。
备注
若需要使用SRIOV功能,应安装带-VF后缀的VBIOS固件文件,例如mxvbios-1.4.0.0-200-C500-VF.bin。
确保板卡所有任务已经停止。如果有任务在进行中,需要停止其进程。
使用mx-smi工具执行以下命令,升级VBIOS固件(需要Root权限)。
sudo mx-smi -u /lib/firmware/metax/mxc500/mxvbios-xxx.bin -t 600
默认对所有板卡进行升级。若屏幕显示以下信息,则表示固件下载成功。
vbios-upgrade Done若上述升级VBIOS固件中出现
Bar0Size mismatch字样,使用以下命令升级(需要Root权限)。sudo mx-smi -U /lib/firmware/metax/mxc500/mxvbios-xxx.bin -t 600 -i ID
ID是板卡序列号,可以通过mx-smi -L查询获取相应板卡的ID。重启服务器,以使更新的固件生效。
重启成功并加载驱动后,用mx-smi工具执行以下命令查询VBIOS固件版本。若与目标版本一致,说明升级安装成功。以曦云C500为例,VBIOS固件版本如下图所示。
mx-smi --show-version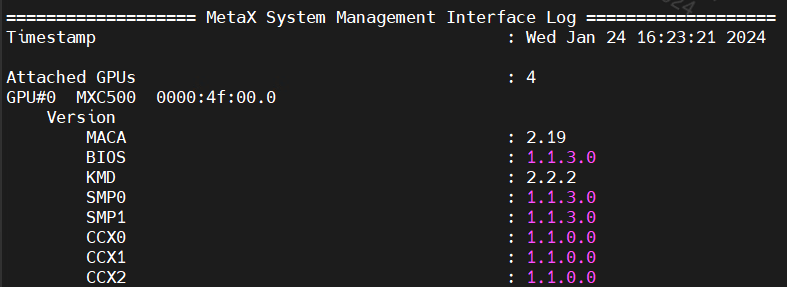
图 2.3 VBIOS固件版本
2.2.5. 卸载驱动
操作步骤
执行以下命令,卸载驱动。
sudo /opt/mxdriver/mxdriver-install.sh -U
根据系统提示信息决定是否重启服务器,若需要重启系统,请执行以下命令;否则,请跳过此步骤。
reboot
3. 虚拟化支持
曦云系列GPU支持以下虚拟化特性:
物理GPU透传模式,支持GPU直通到虚拟机中使用
SRIOV,基于硬件虚拟化的算力切分,支持以下两种模式:
Flat模式,在宿主机上直接使用VF
VF透传模式,支持VF直通到虚拟机中使用
sGPU(Sliced GPU),基于软件虚拟化的算力切分
不同的虚拟化特性可以满足不同的虚拟化场景需求,例如:
需要硬件/OS隔离和GPU互联的场景可以使用物理GPU透传
需要硬件隔离和算力切分的场景可以开启SRIOV
需要细粒度算力显存资源切分的场景可以使用sGPU
3.1. 虚拟机环境配置选项
在使用物理GPU透传模式或VF透传模式时,需要使用虚拟机。在虚拟机中正确使用GPU的虚拟化功能,需要按照以下建议正确配置宿主机的BIOS和OS启动选项。
3.1.1. 宿主机BIOS配置说明
开启虚拟化首先需要确认BIOS的配置是否满足,常见影响虚拟化的BIOS配置如下:
CPU的虚拟化配置(以x86为例)
Intel CPU VT-x Support,选择
EnabledAMD CPU AMD-V(或SVM)Support,选择
Enabled
MMIO空间相关配置
MMIO Size,如果有该选项,建议使用最高配置
PCI相关配置
SRIOV Support,选择
EnabledARI Support,选择
EnabledACS Support,选择
EnabledIOMMU(或SMMU)Support,选择
Enabled
备注
由于不同服务器厂商使用的BIOS版本不同,有些参数可能不支持或是隐藏的配置,如对BIOS的虚拟化支持有疑问,请咨询相关服务器厂商。
3.1.2. 宿主机Linux内核虚拟化参数配置
使用透传模式时,Linux内核参数需要增加IOMMU的相关配置。
操作步骤
例如,运行在Intel CPU上的Ubuntu系统中,使用root用户修改 /etc/default/grub。
将
GRUB_CMDLINE_LINUX_DEFAULT=""修改为GRUB_CMDLINE_LINUX_DEFAULT="iommu=pt intel_iommu=on"执行以下命令。
sudo update-grub重启系统,登入系统查看 /proc/cmdline,确保改动生效。
cat /proc/cmdline
x86平台上Linux内核IOMMU配置参数,参见表 3.1。Arm平台上Linux内核IOMMU配置参数,参见表 3.2。
参数格式 |
说明 |
|---|---|
|
启用Intel IOMMU |
|
启用AMD IOMMU |
|
仅在PCI设备透传时使用IOMMU |
参数格式 |
说明 |
|---|---|
|
仅在PCI设备透传时使用SMMU |
3.1.3. Hypervisor支持
沐曦虚拟化功能支持以下Hypervisor:
QEMU/KVM及基于QEMU/KVM实现的云平台软件,例如OpenStack
VMware ESXi,仅支持物理GPU透传
3.1.4. 虚拟机配置建议
关于虚拟机的配置建议如下:
对于x86平台,建议使用Q35虚拟硬件平台,Q35支持PCIe相关特性。
配置虚拟机时,需要根据服务器的NUMA拓扑合理分配CPU与内存资源,否则可能会影响性能。
对于虚拟机内支持PCIe P2P,由于虚拟机依赖IOMMU,默认需要开启ACS,开启ACS会影响PCIe设备的P2P I/O路径,引入性能问题。
建议对支持ATS的PCIe设备透传后,打开其P2P路径上PCIe bridge的ACS Direct Translated bit,以降低ACS引入的性能损失。
使用OpenStack的虚拟机管理软件配置GPU透传时,需要根据当前的固件版本选择设备类型:
不支持SRIOV的固件,物理GPU透传对应的设备类型为type-PCI
支持SRIOV的固件,物理GPU透传对应的设备类型为type-PF
支持SRIOV的固件,VF透传对应的设备类型为type-VF
3.2. 内核驱动程序
曦云系列GPU的内核驱动有以下两个:
MetaX GPU Virtualization Manager(mxgvm),在开启GPU SRIOV硬件虚拟化的环境中,运行在宿主机上的PF驱动,负责管理监控VF的运行。SRIOV以外的虚拟化模式下,无需安装和加载此项。
MetaX GPU Driver(metax),驱动物理GPU和虚拟GPU(VF/sGPU),根据场景可以运行于宿主机或虚拟机上。
3.2.1. 驱动安装与反安装
3.2.2. mxgvm驱动的配置文件和主要参数
除加载mxgvm时可以指定参数之外,也可以编辑/etc/mxgvm_config来配置参数,常用参数参见表 3.3。
参数格式 |
说明 |
|---|---|
|
开启多VF时,建议使用4VF,兼顾多实例的同时,相比8VF可获得更高的利用率 |
|
指定设备列表,配合 |
|
|
/etc/mxgvm_config上会自动记录上一次mxgvm加载时的配置参数。再次加载时,若不指定任何参数,则默认使用/etc/mxgvm_config中的配置。
更改VF的数量无需重启,只需卸载mxgvm(参见 3.5.1.2 驱动加载与卸载),再使用新的 vf_num 参数重新加载mxgvm即可。
卸载mxgvm包时,会提示是否需要保留/etc/mxgvm_config文件,用户可根据自己的需求进行选择。
3.3. 设备模型
metax驱动程序用于驱动物理GPU和虚拟GPU(VF/sGPU),针对不同类型的设备,驱动定义了不同的设备模型,目前支持的设备模型有:
Native设备模型(默认),用于驱动真实可见的硬件设备,如物理GPU,SRIOV的VF
sGPU设备模型,用于软件虚拟GPU,适用于基于容器的云端业务场景
引入设备模型的目的在于细分虚拟化应用场景,满足多元化的业务需求。
驱动程序默认的设备模型为Native设备模型,用户可以在不重启主机不卸载驱动(无运行业务)的情况下切换设备模型,以满足线上的动态配置需求。
Native设备模型配置简单,除了指定Native模型无需其它配置,模型切换及sGPU模型的配置参见 3.6 sGPU。
3.4. 物理GPU透传
物理GPU透传不需要开启SRIOV,因此不需要安装mxgvm驱动。
将目标物理GPU上所有业务停止后,配置虚拟机将GPU通过VFIO驱动绑定到虚拟机,启动虚拟机;然后在虚拟机里安装metax驱动,参见 2.2.3 安装驱动;驱动安装后,虚拟机启动时会自动加载metax驱动。
3.4.1. 固件
在物理GPU透传模式下,更新固件在虚拟机中进行,操作步骤参见 2.2.4 更新固件。
备注
请使用常规的VBIOS固件文件,不要使用带-VF后缀的VBIOS固件文件。
如需在虚拟机开启GPU的ATS功能,需要使用带-ATS后缀的VBIOS固件文件。
更新VBIOS后,需要重启宿主机或对GPU执行warm reset才能使新VBIOS生效,只重启虚拟机无法使其生效。
3.4.2. 注意事项
若要对透传到虚拟机中的GPU执行warm reset,需要在宿主机安装mxhv包,具体参见《曦云® 系列通用计算GPU Warm Reset使用指南》中“PF透传虚拟机场景”章节。
3.5. SRIOV
SRIOV可以将物理GPU虚拟为多个VF使用,每个VF拥有物理GPU的部分硬件资源。开启SRIOV硬件虚拟化时可以指定VF数量,以及对哪些GPU设备开启虚拟化。
多个VF的资源是均等的。VF可以在宿主机上使用,这种使用方式称为flat模式;VF也可以透传到虚拟机中使用,这种使用方式称为透传模式。
3.5.1. Flat模式
3.5.1.1. 驱动安装与反安装
操作步骤
将驱动的run安装文件下载到目标机器上,进入文件所在目录,执行以下命令安装驱动:
sudo ./metax-driver-mxc500-x.x.x.x-deb-x86_64.run -- -f -m vt_flat
如果安装过程中检测到VBIOS版本过低,此时驱动只提供升级VBIOS的功能,不支持正常的业务功能,请根据 3.5.1.3 固件中的步骤升级VBIOS。
重启服务器。
sudo reboot执行以下命令,查询mxgvm驱动是否已加载。
lsmod | grep mxgvm
执行以下命令,若回显信息列出所有GPU和VF的信息,则mxgvm驱动工作正常。
maca-vt
备注
安装mxgvm包后,会在/etc/modprobe.d路径下生成mxgvm.conf配置文件,内容如下:
options metax vf_only
目的是让metax驱动只识别VF设备,不会自动和PF设备绑定。因此若不使用VF功能,需要反安装mxgvm包,否则物理GPU无法正常工作。
(可选)若要反安装mxgvm包,执行以下命令,然后重启系统:
sudo /opt/mxdriver/mxdriver-install.sh -U
3.5.1.2. 驱动加载与卸载
安装驱动包后,在系统启动时会自动加载mxgvm和metax。加载mxgvm时会启用GPU的SRIOV虚拟化功能,卸载mxgvm时会禁用GPU的SRIOV虚拟化功能。
若因配置需求,需要手动卸载mxgvm,执行以下操作步骤。
操作步骤
卸载VF驱动。
sudo modprobe -r metax 或 sudo rmmod metax
确保VF没有与任何驱动绑定后,执行以下命令查看mxgvm驱动的“Used by”计数。如果计数为0,说明mxgvm没有被VF使用,可以卸载。
lsmod | grep mxgvm
卸载mxgvm驱动。
sudo modprobe -r mxgvm 或 sudo rmmod mxgvm
备注
卸载后,GPU的虚拟化功能关闭,VF设备不再可见。
手动加载mxgvm时可以通过vf_num参数来指定VF个数。例如,开启4VF:
sudo modprobe mxgvm vf_num=4
备注
此时metax驱动会自动加载,无需再手动加载。
3.5.1.3. 固件
在Flat模式下更新VBIOS固件的操作与PF模式一致,操作步骤参见 2.2.4 更新固件。
备注
请务必安装带-VF后缀的VBIOS固件文件。
更新VBIOS并重启宿主机后,可使用以下命令检查当前VBIOS是否支持SRIOV:
sudo mx-smi --show-vbios | grep SRIOV
若显示为Support,则当前VBIOS支持虚拟化。
3.5.2. VF透传
3.5.2.1. 驱动安装与反安装
操作步骤
将驱动的run安装文件下载到宿主机上,进入文件所在目录,执行以下命令安装驱动:
sudo ./metax-driver-mxc500-x.x.x.x-deb-x86_64.run -- -f -m vt_pt
如果安装过程中检测到VBIOS版本过低,此时驱动只提供升级VBIOS的功能,不支持正常的业务功能,请根据 3.5.2.3 固件中的升级步骤升级VBIOS。
重启服务器。
sudo reboot执行以下命令,查询mxgvm驱动是否已加载。
lsmod | grep mxgvm
执行以下命令,若回显信息列出所有GPU和VF的信息,则mxgvm驱动工作正常。
maca-vt
将需要透传的VF卡上所有业务停止后,配置虚拟机将VF透传进虚拟机,启动虚拟机。
(可选)若要反安装mxgvm包,执行以下命令,然后重启系统:
sudo /opt/mxdriver/mxdriver-install.sh -U
3.5.2.2. 驱动加载与卸载
安装驱动包后,在宿主机系统启动时会自动加载mxgvm,在虚拟机启动时会自动加载metax。加载mxgvm时会启用SRIOV虚拟化,卸载mxgvm时会禁用SRIOV虚拟化。
若因配置需求,需要手动卸载mxgvm,执行以下操作步骤。
操作步骤
在虚拟机中,执行以下命令卸载VF驱动。
sudo modprobe -r metax 或 sudo rmmod metax
关闭虚拟机,确保VF没有与任何驱动绑定后,执行以下命令查看mxgvm驱动的“Used by”计数。如果计数为0,说明mxgvm没有被VF使用,可以卸载。
lsmod | grep mxgvm
卸载mxgvm驱动。
sudo modprobe -r mxgvm 或 sudo rmmod mxgvm
备注
卸载后,GPU的虚拟化功能关闭,VF设备不再可见。
手动加载mxgvm时可以通过vf_num参数来指定VF个数。例如,开启4VF:
sudo modprobe mxgvm vf_num=4
3.5.2.3. 固件
在VF透传模式下,无法在虚拟机中通过VF驱动更新VBIOS固件,需要在宿主机上操作,操作步骤参见 2.2.4 更新固件。
备注
请务必安装带-VF后缀的VBIOS固件文件。
更新VBIOS并重启宿主机后,可使用以下命令检查当前VBIOS是否支持SRIOV:
sudo mx-smi --show-vbios | grep SRIOV
若显示为Support,则当前VBIOS支持虚拟化。
3.5.3. 注意事项
3.5.3.1. VF0显存大小
开启SRIOV后,当VF数量大于1时,VF0的显存比其它VF少256M。
3.5.3.2. Linux DRM对显卡数量的限制
Linux内核版本低于6.8的内核DRM子系统最多支持64个GPU设备。在8卡环境下,每张卡开启8个VF时,共有64个VF,此时如果服务器自带显卡,有可能会占用一个DRM设备,导致最后一个VF无法正常工作。
3.5.3.3. 互联模式的限制
一旦开启SRIOV,物理GPU与VF将不支持MetaXLink互联。
3.5.3.4. VF不支持ATS
开启SRIOV后,VF不支持ATS功能。
3.6. sGPU
sGPU是软件实现的算力切分方案,可以基于物理GPU创建最多16个虚拟GPU实例,称之为sGPU设备,主要面向基于容器的云端推理和小模型训练场景,不支持多租户场景。每个sGPU设备可以按照配额分配一定的物理GPU算力和显存单独进行计算。多个sGPU在同一张物理GPU上按照时分复用的方式运行,并按照各自的算力配额进行调度。
3.6.1. 设备管理
使用sGPU的第一步是确认物理GPU是否开启sGPU模型,具体参见 3.7.2.1 设置sGPU设备模型。开启sGPU模型后,可以根据业务需求创建sGPU实例,创建sGPU实例时可以指定实例所需的显存、算力配额。
每个sGPU实例在对应的物理GPU上都有一个sGPU ID,取值范围为0-15,用户可以结合物理GPU ID和sGPU ID找到对应的sGPU实例并进行各种配置操作。
在sGPU实例不再使用且无正在运行的业务时,可以移除sGPU实例来释放其所占用的物理GPU资源。
sGPU运行业务时,可以通过mx-smi命令查看GPU利用率,具体参见 3.7.2.9 查看sGPU利用率。需要结合具体的调度策略来解读利用率。
3.6.2. 资源管理
3.6.2.1. 显存配额
sGPU的显存配额最小为1M,最大显存配额比物理GPU实际显存少,因为驱动需要预留部分显存作为内部使用。
除了创建sGPU时必须指定显存大小,创建后sGPU的显存支持动态伸缩,在业务运行时可以动态调整显存大小。 动态增大显存的前提是物理GPU有足够的可分配显存,动态减少显存的前提是减少的显存小于sGPU当前未使用的显存大小。
3.6.2.2. 算力配额
sGPU的算力配额粒度为1%,最大可配配额为100%。 如果创建sGPU时未指定算力配额且物理GPU可分配算力配额足够,默认算力配额为5%;如果物理GPU的可分配算力配额低于指定的算力配额,sGPU的算力配额为0。
sGPU支持三种调度策略,参见 3.6.3.1 调度策略。算力配额在不同的策略下有不同的解读:
在Best effort策略下,不使用算力配额,即不论算力配额是什么值都不生效
在Fixed share策略下,算力配额代表sGPU实例可使用的最大算力,0代表不参与调度
在Burst share策略下,算力配额代表sGPU实例可使用的最小算力,0代表不参与调度
sGPU创建后,sGPU的算力配额支持动态伸缩,支持在业务运行时进行调整。动态增大算力配额的前提是物理GPU有足够的可分配算力配额。
3.6.3. 调度机制
sGPU基于时分复用的方式共享物理GPU算力,sGPU调度器提供了多种调度策略以满足不同的算力切分需求,不同的调度策略在算力利用率、并行度及算力控制上侧重不同。
3.6.3.1. 调度策略
sGPU支持三种调度策略:
Best effort策略(默认),物理GPU上的所有sGPU实例基于GPU最大硬件并行度并行工作,最大限度使用物理GPU的算力。
Fixed share策略,每个sGPU实例严格按照指定的算力配额使用物理GPU算力,在单位时间内一个sGPU实例使用完自己的算力配额后就会让给其它sGPU实例进行调度。
Burst share策略,如果物理GPU有可分配算力配额,可分配配额按照当前所有算力配额非0的sGPU实例数量进行均分,每个sGPU的实际算力配额为指定算力配额加均分后的配额之和。 如果物理GPU没有可分配配额,sGPU实例算力配额就是指定配额,等价于Fixed share策略。
物理GPU切换到sGPU模型后,默认调度策略是Best effort,该物理GPU上的所有sGPU实例统一按照物理GPU当前调度策略进行调度。 在sGPU模型下,即使物理GPU有sGPU正在运行业务时,也可以随时修改物理GPU的调度策略。如何配置调度策略参见 3.7.2.7 配置查看调度策略。
3.6.3.2. sGPU优先级
sGPU支持在线/离线业务混布的功能,在线业务可以抢占离线业务,此功能通过设置sGPU的优先级来实现。sGPU支持两种优先级:
Normal(默认),此优先级的sGPU受物理GPU调度策略的控制,运行离线业务。
High,此优先级的sGPU不受物理GPU调度策略的控制,运行在线业务。
如何配置查看sGPU优先级参见 3.7.2.6 配置查看sGPU优先级。
备注
sGPU创建时默认优先级为Normal,无论sGPU是否有业务在运行, 都可以动态调整sGPU的优先级。
当物理GPU中存在High sGPU时,即使High sGPU没有运行业务,此物理GPU下的所有Normal sGPU都将不再调度。
当Normal sGPU被High sGPU抢占后,Normal sGPU的业务处于挂起状态, 但占有的显存资源不会释放,直到该物理GPU的High sGPU都被移除才会继续运行。
当物理GPU中存在多个High sGPU时,它们之间以Best effort策略进行调度。
3.6.3.3. timeslice
物理GPU提供了timeslice属性来定义1%的算力配额所对应的时间片,也就是说,调度窗口的大小是timeslice乘以100,timeslice的默认值为10ms,有效值为1ms-100ms。 timeslice的大小与业务的计算模式相关,对GPU使用率和吞吐率有一定的影响。 对于推理和小模型训练通常10ms是比较合适的,对于计算量较大的业务可以适当提高timeslice的值来获取更佳的GPU利用率和吞吐率。
如何配置timeslice参见 3.7.2.8 配置timeslice。
3.6.4. 容器接口
将一个sGPU设备绑定到容器时,容器管理软件需要感知以下接口:
/dev/mxcd,metax驱动管理字符设备
/dev/dri/renderDXXX,sGPU所属物理GPU对应的DRI设备文件,XXX是3位的十进制数字,代表了DRI设备的minor ID
/dev/sgpuXXX,代表一个sGPU设备对应的字符设备,XXX是3位的十进制数字,代表了sGPU的minor ID
3.6.4.1. 获取物理GPU DRI设备文件的minor ID
执行以下命令查看物理GPU的设备ID和PCI总线地址的对应关系:
mx-smi -L例如,获得如下显示结果:
GPU#0 0000:01:00.0
执行以下命令获取物理GPU的DRI设备文件:
ls -l /dev/dri/by-path | grep 0000:01:00.0
例如,获得如下显示结果,其中renderD129即为要获取的设备信息:
lrwxrwxrwx 1 root root 13 Oct 24 19:03 pci-0000:01:00.0-render -> ../renderD129
3.6.4.2. 获取sGPU设备文件的minor ID
在使用mx-smi显示sGPU实例时,会显示sGPU实例的minor ID,具体命令行参见 3.7.2.2 创建和移除sGPU。
3.6.5. 注意事项
使用sGPU时需要注意以下问题:
启用sGPU需依赖2.32.0.x及之后版本的metax driver和MXMACA® SDK
使用sGPU的Fixed share和Burst share调度策略时,MXMACA SDK不支持开启graph mode,运行业务时需要手动将下列环境变量的值设为0:
MACA_GRAPH_LAUNCH_MODE
MACA_DIRECT_DISPATCH
sGPU主要面向基于容器的云端业务场景,建议使用沐曦配套的容器组件进行部署管理
sGPU设备实例不支持互联功能,互联功能包括PCIe P2P和MetaXLink
sGPU的目标业务场景是推理和小模型训练,除了GPU的性能,服务器侧的硬件性能对该场景下性能指标也有较大影响
当sGPU实例数量较多时,Best effort策略在某些平台上存在一定的算力不均衡
隔离性不如SRIOV,致命故障或恶意代码会影响物理GPU上的所有sGPU实例,因此不支持多租户场景
建议在生产环境部署中一个容器只绑定一个sGPU设备
使用Profiler时,GPU与sGPU利用率信息会失真
3.7. mx-smi的虚拟化支持
本节仅列出虚拟化常用命令,更多mx-smi命令参见《曦云® 系列通用计算GPU mx-smi使用手册》。
3.7.1. SRIOV支持
3.7.1.1. 显示VF
显示当前系统所有GPU和VF设备。
mx-smi -L
显示结果中,每个VF都有特定的ID,可用于在其它操作中指定目标VF。
3.7.1.2. VF FLR
触发第二个VF的FLR。
mx-smi -i 1 –vfflr
3.7.2. sGPU支持
3.7.2.1. 设置sGPU设备模型
使用以下命令可以查看每个物理GPU当前是否开启sGPU设备模型:
mx-smi sgpu --show-mode
相应的输出结果如图 3.1 所示:
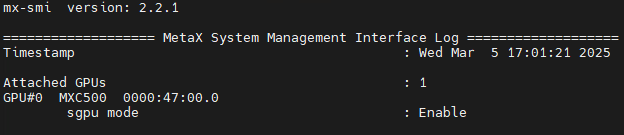
图 3.1 查看设备模型
如果sgpu mode为Disabled,使用以下命令启用sGPU:
mx-smi sgpu --enable -i 0
其中的 -i 0 指定的是物理GPU的ID。使用 --disable 选项就会禁用sGPU,切换回Native设备模型。
3.7.2.2. 创建和移除sGPU
在sGPU设备模型下,使用以下命令可以在一张物理GPU上创建sGPU实例:
mx-smi sgpu -c --compute 10 --vram 4G --alias sgpu-test -i 0
命令行中的各个选项含义如下:
选项
-c表示创建sGPU实例选项
--compute指明新建sGPU实例的算力为物理GPU的10%选项
--vram指明新建sGPU实例的显存大小为4G选项
--alias指明新建sGPU实例的别名,别名是用户自定义的字符串,便于区分设备选项
-i指明在ID为0的物理GPU上创建sGPU
创建sGPU实例后,可以使用以下命令查看sGPU实例:
mx-smi sgpu
输出结果如图 3.2 所示:
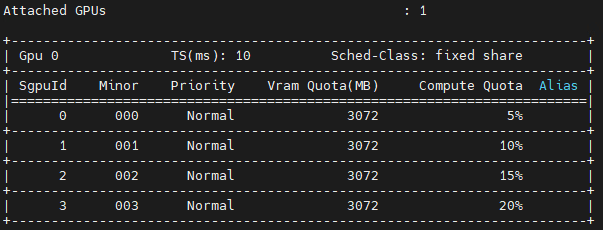
图 3.2 查看sGPU实例
若要将物理GPU 0上的sGPU ID为3的sGPU实例移除,执行以下命令:
mx-smi sgpu -r 3 -i 0
命令行中的各个选项含义如下:
选项
-r表示移除目标物理GPU上sGPU ID为3的sGPU实例选项
-i指明目标物理GPU的ID为0
对正在运行业务的sGPU执行移除操作会报错,需要在业务终止后再进行移除。
一张物理GPU上最多可以创建16个sGPU实例,按照创建顺序,每个sGPU有自己的sGPU ID,ID值范围是0-15。
3.7.2.3. 配置显存配额
除了在创建sGPU时可以指定显存配额,sGPU创建后也可以通过以下命令修改显存大小:
mx-smi sgpu --set 0 --vram 4G -i 0
命令行中的各个选项含义如下:
选项
--set指明目标sGPU的ID为0选项
--vram指明新的显存大小为4G选项
-i指明目标物理GPU的ID为0
使用以下命令可以查看sGPU的显存配额和显存使用情况:
mx-smi sgpu --show-memory
输出结果如图 3.3 所示:
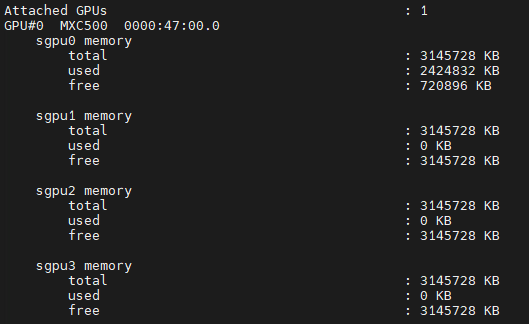
图 3.3 查看sGPU内存信息
3.7.2.4. 配置算力配额
除了创建sGPU时可以指定算力配额,sGPU创建后也可以通过以下命令修改算力配额:
mx-smi sgpu --set 0 --compute 50 -i 0
命令行中的各个选项含义如下:
选项
--set指明目标sGPU的ID为0选项
--compute指明新的算力配额为50%选项
-i指明目标物理GPU的ID为0
3.7.2.5. 查看物理GPU可用资源
在创建sGPU前,可执行以下命令查看当前物理GPU可分配资源:
mx-smi sgpu --show-remain
输出结果中包含物理GPU总显存大小、可分配显存大小和可分配算力配额。
3.7.2.6. 配置查看sGPU优先级
执行以下命令修改sGPU的优先级:
mx-smi sgpu --set-queue-priority 1 -s 2 -i 0
命令行中的各个选项含义如下:
选项
--set-queue-priority指明目标sGPU的优先级为High0:Normal
1:High
选项
-s指明目标sGPU的ID为2选项
-i指明目标物理GPU的ID为0
执行以下命令查看当前sGPU的优先级:
mx-smi sgpu
显示页面的 Priority 列指明对应行的sGPU的优先级。
3.7.2.7. 配置查看调度策略
执行以下命令修改物理GPU的调度策略:
mx-smi sgpu --set-sched-class 1 -i 0
命令行中的各个选项含义如下:
选项
--set-sched-class指明目标GPU的调度策略为fixed share0:best effort
1:fixed share
2:burst share
选项
-i指明目标物理GPU的ID为0
执行以下命令查看当前物理GPU调度策略:
mx-smi sgpu --show-sched-class -i 0
3.7.2.8. 配置timeslice
执行以下命令修改物理GPU的timeslice:
mx-smi sgpu --set-timeslice 20 -i 0
命令行中的各个选项含义如下:
选项
--set-timeslice指明目标GPU的timeslice为20ms选项
-i指明目标物理GPU
执行以下命令查看当前物理GPU的timeslice:
mx-smi sgpu --show-timeslice -i 0
3.7.2.9. 查看sGPU利用率
使用以下命令查看sGPU实例利用率:
mx-smi sgpu --show-usage
4. 驱动与固件功能依赖
本节介绍1.12.0.0及之后版本固件的主要新增或变化,及其对内核驱动的最低版本要求。
固件版本 |
要求驱动最低版本 |
固件主要新增或变化 |
|---|---|---|
1.12.0.0 |
2.4.0 |
|
1.13.0.0 |
2.5.0 |
支持PCC/PWRBRK查询和设置 |
1.16.0.0 |
2.6.0 |
|
1.18.0.0 |
2.9.0 |
|
1.20.0.0 |
2.11.0 |
|
1.22.2.0 |
2.12.4 |
新增MetaXLink端口状态查询功能 |
1.23.0.0 |
2.13.0 |
|
1.24.1.0 |
2.14.0 |
新增风扇PWM占空比查询接口 |
1.26.0.0 |
2.16.0 |
|
5. 附录
5.1. 术语/缩略语
术语/缩略语 |
全称 |
描述 |
|---|---|---|
ACS |
Access Control Services |
访问控制服务 |
ARI |
Alternative Routing-ID Interpretation |
可替换的Routing ID |
BAR |
Base Address Register |
基地址寄存器 |
BIOS |
Basic Input/Output System |
基本输入输出系统 |
CSM |
Compatibility Support Module |
兼容性支持模块 |
Docker |
一个开源的应用容器引擎 |
|
IOMMU |
Input-Output Memory Management Unit |
输入输出内存管理单元 |
KMD |
Kernel-Mode Driver |
内核模式驱动程序 |
KVM |
Kernel Virtual Machine |
基于内核的虚拟机,是一种内建于Linux的开源虚拟化技术 |
MetaXLink |
沐曦GPU D2D接口总线 |
|
MMIO |
Memory Mapped I/O |
内存映射I/O,是PCI规范的一部分 |
MXMACA |
MetaX Advanced Compute Architecture |
沐曦推出的GPU软件栈,包含了沐曦GPU的底层驱动、编译器、数学库及整套软件工具套件 |
NUMA |
Non-Uniform Memory Access |
非一致性内存访问 |
PCI |
Peripheral Component Interconnect |
一种连接主板和外部设备的总线标准 |
PCIe |
PCI Express |
一种高速串行计算机扩展总线标准 |
P2P |
Peer-to-Peer |
PCIe P2P是PCIe的一种特性,使两个PCIe设备之间可以直接传输数据 |
PF |
Physical Function |
物理功能 |
QEMU |
一个开源的模拟器和虚拟机 |
|
sGPU |
Sliced GPU |
基于软件切分的GPU |
SMMU |
System Memory Management Unit |
系统内存管理单元 |
SRIOV |
Single Root I/O Virtualization |
将单个物理PCIe设备虚拟化为多个PCIe设备的技术 |
VBIOS |
Video BIOS |
图形卡的基本输入输出系统 |
VF |
Virtual Function |
虚拟功能 |
sGPU |
Sliced GPU |
软件切分的GPU |