1. 概述
本文档主要用于指导用户在AI训练的场景下,使用曦云® 系列GPU进行人工智能算法的训练相关事宜。
本文档从MXMACA® 软件栈的维度来介绍曦云系列GPU硬件和配套软件提供的功能特性,指导用户达成对应的使用场景。
1.1. MXMACA软件栈
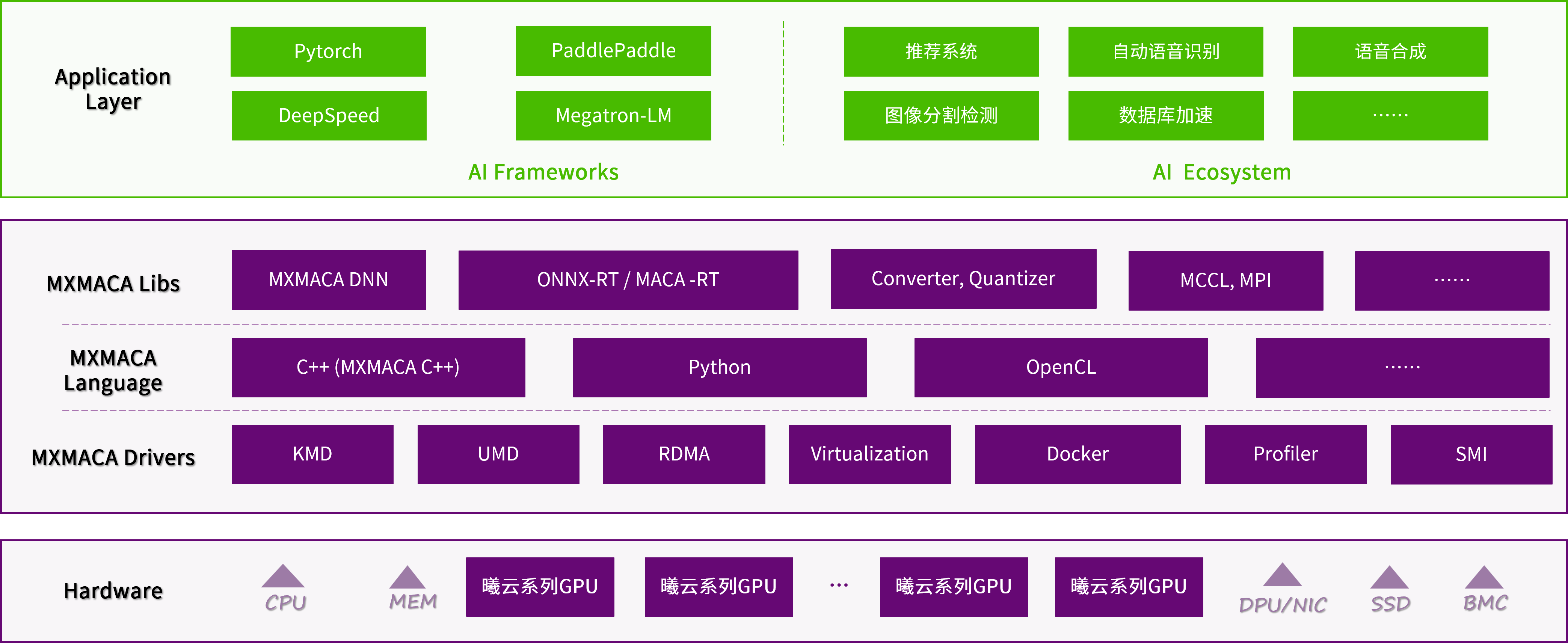
图 1.1 MXMACA整体架构
在整个MXMACA软件栈中,不可或缺的基础设施是硬件底座。硬件底座提供了算力保证,亦是作为特定场景下面的加速器来使用。
执行规则依托于硬件基础设施,并服务于上层应用。首先是MXMACA的Driver驱动层,对内封装了硬件的基础能力,对外提供了友好的API接口;在驱动层的基础上,进一步满足了不同高级语言的使用范式;此外,提供了针对硬件高度优化的函数库。
1.2. AI训练功能特性
曦云系列GPU支持以下AI训练功能和特性:
支持主流训练框架,如PyTorch、PaddlePaddle等
提供硬件高度适配的高性能算子库,如mcDNN库、mcBLAS库、mcSolverIT库等
提供友好的MXMACA生态用户编程接口
支持分布式训练
支持大模型训练框架
提供完备的工具链
支持容器化部署
2. 环境依赖及安装
2.1. 环境依赖
在AI训练的场景下,使用曦云系列GPU之前,必须确保服务器已安装曦云系列GPU板卡以及驱动程序。驱动的安装参见《曦云® 系列通用计算GPU驱动安装指南》中“安装驱动”章节。
2.2. 获取Docker容器镜像
MXMACA软件栈中提供了Docker容器镜像,便于用户使用曦云系列GPU。详细信息参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
3. 训练框架的支持
MXMACA软件栈支持主流的训练框架,包括PyTorch和PaddlePaddle等。
3.1. PyTorch
PyTorch是一个开源的Python机器学习库,基于Torch,底层由C++实现,应用于人工智能领域,如计算机视觉和自然语言处理。
MXMACA软件栈以Wrapper的方式兼容PyTorch下的GPU代码,从而实现为PyTorch支持MetaX的硬件后端。适配优化后的PyTorch以PIP安装包和源码的形式提供。
3.2. PaddlePaddle
PaddlePaddle(飞桨)深度学习框架有大量的官方模型库,支持大规模训练和端到端的部署,详细信息可参见 官方网站 。
基于MXMACA软件对PaddlePaddle的适配和优化,使得MXMACA程序开发人员可以在曦云系列GPU上方便高效地使用PaddlePaddle。适配优化后的PaddlePaddle以PIP安装包和源码的形式提供。
3.3. Tensorflow
TensorFlow是一个开源的深度学习框架,完全基于Python语言设计,底层由C++实现。TensorFlow可以训练和运行深度神经网络,可以应用于多个场景,比如图像识别、图像分类、自然语言处理和视频检测等。
基于MXMACA软件对TensorFlow的适配和优化,使得MXMACA程序开发人员可以在曦云系列GPU上方便高效地使用TensorFlow。适配优化后的TensorFlow以PIP安装包和源码的形式提供。
4. 高性能库
MXMACA软件栈提供硬件高度适配的高性能算子库,包括mcDNN库、mcBLAS库、mcSOLVER库、mcRAND库、mcFFT库等,初步涵盖了计算机视觉、人工智能、优化求解、分子动力学等领域。
4.1. mcDNN库
mcDNN深度神经网络库是一个GPU加速的深度神经网络原语库。mcDNN为标准例程提供了高度调优的实现,例如前向和后向卷积、池化、规范化和激活层;加速了广泛使用的深度学习框架,包括Caffe2、Keras、PaddlePaddle和PyTorch等。
mcDNN库的主要功能特性包括:
张量核心加速支持所有流行的卷积操作,包括2D卷积、3D卷积、分组卷积、深度可分离卷积等,支持channel first和channel last的输入和输出数据排布
为计算机视觉和语音模型提供深度优化的内核算子,包括ResNet、ResNext、EfficientNet、EfficientDet、SSD、MaskRCNN、Unet、VNet、BERT、GPT-2、Tacotron2和WaveGlow等
支持FP32、FP16、BF16和TF32浮点格式和INT8
支持将内存受限的操作(如逐点和简化)与计算受限的操作(如卷积和matmul)融合在一起
mcDNN库的详细信息,参见《曦云® 系列通用计算GPU mcDNN API参考》。
4.2. mcBLAS库
mcBLAS库提供了基本线性代数子程序(BLAS)的GPU加速实现。通过针对曦云系列GPU高度优化的BLAS API,加速AI和HPC应用程序。
mcBLAS库的主要功能特性包括:
完全支持所有152个标准BLAS例程
支持半精度和整数矩阵乘法
硬件张量核心的GEMM和GEMM扩展优化
GEMM性能调整用于各种深度学习模型的规格和数据类型
支持流并发操作
mcBLAS库的详细信息,参见《曦云® 系列通用计算GPU mcBLAS API参考》。
4.3. mcSolverIT库
mcSolverIT库提供了密集和稀疏的直接线性求解器和特征求解器的集合。基于曦云系列GPU,为计算机视觉、CFD、ODE、计算化学和线性优化应用提供了显著加速。
mcSolverIT 库支持以下求解器或预条件器:
代数多网格(Algebraic Multigrid,AMG)提供经典的AMG和聚合AMG,其中包含AMG求解过程的不同选项
简单的松弛迭代求解器,例如高斯-赛戴尔(Gauss-Seidel)、雅可比(Jacobi)及其变体
多项式迭代求解器,例如切比雪夫多项式(Chebyshev Polynomial)方法
克雷洛夫求解器,例如共轭梯度(Conjugate Gradient,CG)、广义最小残差(Generalized Minimum Residual,GMRES)及其变体
不完全直接求解器,例如Cholesky分解,LU 分解,SVD分解和QR分解等
预条件求解器,例如预条件共轭梯度(Preconditioned Conjugate Gradient,PCG)、预条件广义最小残差(Preconditioned Generalized Minimum Residual,PGMRES)等
mcSolverIT库的详细信息,参见《曦云® 系列通用计算GPU mcSolverIT API参考》。
4.4. mcRAND库
mcRAND库提供高性能GPU加速随机数生成(RNG)。mcRAND库充分利用曦云系列GPU的高并发能力,以极致的速度提供高质量的随机数。
mcRAND库的主要功能特性包括:
灵活的使用模式
Host API用于在GPU上批量生成随机数
内联实现允许在GPU函数/内核中使用,或者在您的Host代码中使用
高质量的RNG算法
MRG32k3a
MTGP Merseinne Twister
XORWOW伪随机生成
Sobol的准随机数生成器,包括对加密的和64位RNG的支持
多个RNG分布选项
均匀分布
正态分布
对数正态分布
单精度或双精度
泊松分布
mcRAND库的详细信息,参见《曦云® 系列通用计算GPU mcRAND API参考》。
4.5. mcFFT库
mcFFT库是基于曦云系列GPU的快速傅里叶变换(FFT)的实现,用于构建跨学科的应用程序,如深度学习、计算机视觉、计算物理、分子动力学、量子化学以及地震和医学成像。使用mcFFT,应用程序自动受益于定期的性能改进和新的GPU架构。
mcFFT库的主要功能特性包括:
复数和实数类型的1D、2D、3D傅里叶变换算法
提供与Fastest Fourier Transform in the West(FFTW)类似的API接口
灵活的数据布局允许在单个元素和数组维度之间任意跨越
流式异步执行
半精度、单精度和双精度变换
批处理执行
In-place 和out-of-place转换
线程安全,可从多个主机线程调用
mcFFT库的详细信息,参见《曦云® 系列通用计算GPU mcFFT API参考》。
4.6. mcThrust库
Thrust是一个强大的并行算法和数据结构库,为GPU编程提供了一个灵活的高级接口,极大地提高了开发人员的工作效率。使用Thrust,C++开发人员只需编写几行代码就可以执行GPU加速的排序、扫描、转换和约简操作。Thrust为一些算法和数据结构提供类似STL的模板接口,这些算法和数据结构是为高性能异构并行计算而设计的。
为了减少用户迁移的成本,MXMACA软件栈提供了mcThrust,针对曦云系列GPU架构做了深层次的优化,但是面向用户的API接口不变。当用户的应用使用了Thrust的API接口,MXMACA软件栈提供了wrapper工具来帮助代码的移植。只需要切换到MXMACA软件栈的环境变量,相应的编译器工具mxcc将会自动参与后续的工作,对用户不感知。
mcThrust库的详细信息,参见《曦云® 系列通用计算GPU mcThrust API参考》。
4.7. mcCUB库
CUB是一个C++头文件only的函数库,为编程模型的每一层提供了最先进的可重用软件组件,包括并行的原语和一些工具。这些并行原语包括warp维度的原语、block维度的原语和device维度的原语。工具集包括智能迭代器、线程和线程块IO、device,kernel和存储管理。一般CUB会与Thrust库配合起来使用。
MXMACA软件栈提供了mcCUB,针对曦云系列GPU架构做了深层次的优化,但是面向用户的API接口不变。当安装了MXMACA软件栈的Toolkit以后,将会自动拷贝CUB和Thrust的头文件到系统中,默认是MXMACA软件栈路径。不需要单独构建CUB,要在代码中使用CUB原语,只需要获取最新的CUB发行版,并包含CUB原语的C++头文件<cub/cub.cuh>,或者特定的头文件。然后使用MXMACA软件栈的mxcc编译器编译您的程序即可。
mcCUB库的详细信息,参见《曦云® 系列通用计算GPU mcCUB API参考》。
5. 用户编程接口
在整个MXMACA软件栈中,为了满足不同用户和不同场景的诉求,提供了更细粒度、更友好的MXMACA软件栈用户编程接口。对于AI训练领域,主要会涉及到编译器的接口、运行时接口、集合通信接口以及图像处理和视频编解码等方面的接口。
5.1. 编译器接口
mxcc(MXMACA C/C++ Compiler)是MXMACA软件栈中针对MetaX GPU的硬件架构和功能特性设计和发布的编译器,其底层实现也是在LLVM的基础之上,可以支持C、C++、原生代码以及MXMACA软件栈中编程语言、接口和范式,最终生成可以在MetaX GPU上运行的高性能的可执行文件。
mxcc工具的详细介绍,参见《曦云® 系列通用计算GPU mxcc编译器用户指南》。
5.2. 运行时接口
运行时接口规范了基于MetaX GPU的编程模型和使用的范式,可以帮助开发人员利用曦云系列GPU提供的计算资源,快速构建自己的应用,并在特定的领域中发挥GPU加速的最佳性能。
MXMACA软件栈中运行时接口主要包括设备管理API,事件管理API,流管理API,内存管理API,模型推理API,图像处理API以及视频处理API等。
MXMACA软件栈中运行时接口的详细介绍,参见《曦云® 系列通用计算GPU运行时API编程指南》。
5.3. 集合通信接口
MetaX Collective Communications Library(MCCL,发音为“Mickel”)是一个提供 GPU 间通信原语的通讯库,这些原语具有拓扑感知能力,并且使用方便。MCCL 实现集合通信和点对点发送/接收原语。
MCCL通信库的详细介绍,参见《曦云® 系列通用计算GPU MCCL编程指南》。
5.4. 图像处理和视频编解码接口
MXMACA软件栈中,对于数据预处理和视频编解码提供对应的接口和方法,支持主流的H264、H265、AV1、AVS2和JPEG等格式。此外,基于FFmpeg在多媒体领域的广泛应用和用户的开发需求,曦云系列GPU支持将MCRUNTIME中VPU和G2D集成到FFmpeg中,并选取FFmpeg4.3作为集成的基线。
视频编解码库的详细介绍,参见《曦云® 系列通用计算GPU视频编解码VPU编程指南》。
6. 分布式训练
分布式训练主要为了解决单节点设备的算力和内存不足的问题。通常主流的训练框架会提供对应的分布式训练的接口和使用方式。MXMACA软件栈通过对主流训练框架的支持,提供分布式训练的能力。
此外对于大型和超大型模型来说,其本身的模型特点和超出常规的参数量,使得只能通过分布式的算力基础设施来做训练。对此在PyTorch训练框架的基础上,涌现出了类似于Megatron和DeepSpeed这些框架,降低大语言模型训练的门槛。所有的技术底层都离不开分布式训练的各种并行方式和组合策略。本章简要介绍各种并行的方式。
6.1. 数据并行
数据并行的基本使用场景是需要更大的batch来训练某个模型,但是过大的batch会导致显存的OOM,因此单机多卡甚至是多机多卡的数据并行训练将是一个很好的方式。大的batch会被切分到mini-batch供给单卡训练,每个单卡都是一个完整的训练实例,通过对每个step的所有训练实例的权重进行聚合操作并求取均值,然后用这个均值来更新单个训练实例的梯度。
6.2. 模型并行
随着模型规模和参数量的激增,特别是大语言模型的流行,模型并行将是更好的选择。通过将模型进行拆分,放置在不同的训练卡上以满足训练要求。通常有两种类型的并行:张量并行和流水线并行。
6.2.1. 张量并行
张量并行指的是将计算图中层内的参数切分到不同设备,即层内并行,如矩阵-矩阵乘法的拆分。张量并行的关键点在于如何切分模型到不同的设备上和如何保证切分的正确性,因此需要额外的通信开销来保证计算的正确性。例如,对于矩阵乘操作的切分,可以按照左右矩阵的行或列进行切分。不同的切分方式将影响在执行后续操作前是否需要reduce操作以及各种通信和计算的开销。
6.2.2. 流水线并行
流水线并行指的是按模型layer层切分到不同设备,即层间并行。在前向传递过程中,每个设备将中间的激活传递给下一个阶段。在后向传递过程中,每个设备将输入张量的梯度传回给前一个流水线阶段。这允许设备同时进行计算,并增加了训练的吞吐量。流水线并行训练会有一些设备参与计算的冒泡时间,可能导致计算资源的浪费。
6.3. 混合并行
通常单一的并行方式并不能得到最优的资源利用率,特别是在超大模型的训练过程中。为了进一步消除计算设备的冒泡时间,会采取混合的并行方式,即数据并行和模型并行协作的方式来提高训练的效率。
以训练GPT-3 为例,它首先被分为 64 个阶段,进行流水并行。每个阶段都运行在 6 台主机上。在6台主机之间,进行的是数据并行训练;每台主机有 8 张 GPU 显卡,同一台机器上的8张 GPU 显卡之间是进行模型并行训练。
7. 大模型训练框架的支持
7.1. Megatron
Megatron-LM是一套基于PyTorch训练框架的开源实现库,支持大规模大型Transformer 语言模型训练。它为基于Transformer 的预训练语言模型,如GPT(Decoder Only)、BERT(Encoder Only)和T5(Encoder-Decoder),提供了高效的张量、流水线和基于序列的模型并行解决方案。即使用混合精度开发了高效、模型并行(张量、序列和管道)和基于Transformer 的模型多节点预训练。
Megatron-LM对于大语言模型的训练,充分体现了数据并行和模型并行的混合使用,尽可能减少额外的通信,尽量做到节点间数据并行,节点内张量并行,提高利用率和训练效率。
MXMACA软件栈以Wrapper的方式兼容Megatron下的GPU代码,从而实现为Megatron支持MetaX的硬件后端。适配优化后的Megatron以源码的形式提供。容器中/workspace文件夹下有适配完成的Megatron-LM源码,该环境可以直接上手使用,使用方式和原始的Megatron-LM相同。
7.2. DeepSpeed
DeepSpeed是一款易于使用的深度学习优化软件套件,可为深度学习训练和推理提供前所未有的规模和速度。DeepSpeed-Chat具有以下三大核心功能:
简化ChatGPT类型模型的训练和强化推理体验:只需一个脚本即可实现多个训练步骤,包括使用 Huggingface 预训练的模型、使用 DeepSpeed-RLHF 系统运行 InstructGPT 训练的所有三个步骤、甚至生成自己的类ChatGPT模型。此外,还提供了一个易于使用的推理API,用于用户在模型训练后测试对话式交互。
DeepSpeed-RLHF模块:DeepSpeed-RLHF 复刻了 InstructGPT 论文中的训练模式,并确保包括监督微调(SFT)、奖励模型微调和基于人类反馈的强化学习(RLHF)在内的三个步骤与其一一对应。此外,还提供了数据抽象和混合功能,以支持用户使用多个不同来源的数据源进行训练。
DeepSpeed-RLHF系统:将DeepSpeed 的训练(training engine)和推理能力(inference engine)整合到一个统一的混合引擎(DeepSpeed Hybrid Engine,DeepSpeed-HE)中用于 RLHF 训练。DeepSpeed-HE 能够在 RLHF 中在推理和训练模式之间无缝切换,使其能够利用来自 DeepSpeed-Inference 的各种优化,如张量并行计算和高性能MXMACA算子进行语言生成,同时训练部分还能从 ZeRO-based 和 LoRA-based 内存优化策略中受益。DeepSpeed-HE 还能够自动在 RLHF 的不同阶段进行智能的内存管理和数据缓存。
MXMACA软件栈以Wrapper的方式兼容DeepSpeed下的GPU代码,从而实现为DeepSpeed支持MetaX的硬件后端。适配优化后的DeepSpeed以PIP安装包和源码的形式提供。
7.3. Colossal-AI
Colossal-AI是一款易于使用的深度学习优化软件套件,通过多维并行、大规模优化器、自适应任务调度、消除冗余内存、降低能量损耗等方式,打造一个高效的分布式人工智能训练系统:
多维并行
目前主流的AI并行方案,都使用3维并行,即数据并行、流水并行、一维模型并行。Colossal-AI在兼容数据并行、流水并行的基础上,进一步使用自行研发的2维模型并行,3维模型并行和2.5维模型并行。此外,针对大图片、视频、长文本、长时间医疗监控等数据,Colossal-AI的序列并行,能突破原有机器能力限制,直接处理长序列数据。因此,Colossal-AI可以将计算并行度从原有的最高3维提升到5维甚至6维,极大提高了AI模型并行计算效率。
大规模优化器
数据并行可以提升训练AI模型的全局批量大小,进而加速训练过程,但这通常会导致严重的优化问题,AI模型难以保持精度。Colossal-AI的LAMB、LARS等大规模优化器,首次将批大小由512扩展到了65536,在极大缩短模型训练时间的同时保持精度。Colossal-AI将会基于该方向的深厚积累,进一步探索推出新的大规模优化器。
自适应任务调度
现有的任务调度器主要通过GPU个数判断任务规模,缺乏足够的弹性,AI任务扩展效率差。Colossal-AI的自适应可扩展调度器,能根据批大小等因素自适应弹性扩展,并通过MCCL网络通信实现高效任务迁移。
消除冗余内存
在训练过程中,除了模型参数本身,梯度、优化器状态等还会进一步严重消耗显存,不能充分利用GPU计算能力。对此,Colossal-AI使用zero redundancy optimizer技术,通过切分优化器状态、梯度、模型参数,使GPU仅保存当前计算所需要的部分,从而减少训练过程中的GPU显存消耗,提高GPU利用率。
降低能量损耗
在分布式训练中,能耗的重要来源是数据移动,尤其是不同服务器之间的通信。Colossal-AI允许使用特大批量进行训练,能够通过减少迭代次数来减少通信次数。而多维模型并行也极大减少了通信次数。例如,在1000个处理器并行时,若现有的一维模型并行,每个处理器需要与其他999个处理器通信,而在Colossal-AI的3维模型并行中,每个处理器仅需与其他9个处理器通信。
MXMACA软件栈以Wrapper的方式兼容Colossal-AI下的GPU代码,从而实现为Colossal-AI支持MetaX的硬件后端。适配优化后的Colossal-AI以源码的形式提供。容器中 /workspace文件夹下有适配完成的Colossal-AI源码,该环境可以直接上手使用,使用方式和原始的Colossal-AI相同。
7.4. InternLM
InternLM是一个轻量级的大模型训练框架,是一套基于PyTorch训练框架的开源实现库。
卓越的推理性能:在数学推理方面取得了同量级模型较优精度,模型可以实现与Llama3和Gemma2-9B实现相媲美的性能。
有效支持百万字超长上下文,模型在1百万字长输入中几乎完美地实现长文“大海捞针”,而且在LongBench等长文任务中的表现也达到开源模型中的领先水平。可以通过LMDeploy尝试百万字超长上下文推理。
工具调用能力整体升级,InternLM2.5支持从上百个网页搜集有效信息进行分析推理,相关实现将于近期开源到Lagent。InternLM2.5具有更强和更具有泛化性的指令理解、工具筛选与结果反思等能力,新版模型可以更可靠地支持复杂智能体的搭建,支持对工具进行有效的多轮调用,完成较复杂的任务。
MXMACA软件栈以Wrapper的方式兼容InternLM下的GPU代码,从而实现为InternLM支持MetaX的硬件后端。适配优化后的InternLM以源码的形式提供。容器中 /workspace文件夹下有适配完成的InternLM源码,该环境可以直接上手使用,使用方式和原始的InternLM相同。
8. 容器化安装部署
MXMACA软件栈提供对Docker以及Kubernetes的支持。开发人员可以借助于容器引擎,运行预先构建好的MXMACA容器镜像,快速建立软件开发或运行所需的环境。开发人员仅需执行一条docker run命令就可获得一个干净而完整的板卡开发环境。
在运行MXMACA容器镜像前,请确认环境满足以下条件:
已正确安装曦云系列GPU内核驱动。
已安装Docker,Docker版本≥18.09。
容器的获取、安装以及具体的使用方式,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
9. 附录
9.1. 术语/缩略语
术语/缩略语 |
全称 |
说明 |
|---|---|---|
CFD |
Computational Fluid Dynamics |
计算流体力学 |
Cholesky分解 |
Cholesky 分解是把一个对称正定的矩阵表示成一个下三角矩阵L和其转置的乘积的分解 |
|
LU分解 |
Lower-Upper Decomposition |
LU分解是矩阵分解的一种,可以将一个矩阵分解为一个单位下三角矩阵和一个上三角矩阵的乘积 |
MXMACA |
MetaX Advanced Compute Architecture |
沐曦推出的GPU软件栈,包含了沐曦GPU的底层驱动、编译器、数学库及整套软件工具套件 |
ODE |
Ordinary Differential Equation |
常微分方程 |
OOM |
Out Of Memory |
内存耗尽 |
QR分解 |
正交三角分解,用于将矩阵转换为 A = QR 形式 |
|
RNG |
Random Number Generation |
随机数生成 |
SVD |
Singular Value Decomposition |
奇异值分解,是线性代数中一种重要的矩阵分解 |