3. DLRover用户指南
3.1. 主要组件的配置
3.1.1. Helm Chart的配置
DLRover的controller通过Helm的方式部署,可选参数说明参见下表。
参数 |
说明 |
|---|---|
|
若集群使用本地镜像仓库,可设置此参数为 |
|
控制DLRover是否启用组调度,dragonfly拓扑下需要启用 |
|
拓扑域中每组节点数,dragonfly拓扑下通常为 |
|
用于识别拓扑关系的k8s节点标签key,通常无需修改 |
|
用于网络拓扑感知的配置文件,通常需要手动修改 |
|
controller组件镜像名称,默认为 |
|
dlrover-master组件镜像名称,默认为 |
|
指定controller组件的image tag |
|
指定dlrover master的image tag |
3.1.2. 提交训练任务的配置
训练任务YAML配置文件中的主要参数说明,参见下表。
参数 |
说明 |
|---|---|
|
任务名称 |
|
任务所在的命名空间,通常为 |
|
任务的分布式策略,PyTorch任务为 |
|
任务模式,通常为 |
|
子任务副本数 |
|
子任务最大的重启次数,默认为 |
|
任务镜像名称 |
|
任务镜像的拉取策略,可选为 |
|
任务启动所执行的命令 |
|
子任务所需的资源,如GPU资源 |
3.1.3. dlrover-run的配置
dlrover-run 已集成在DLRover的Python wheel包中,安装训练镜像后即可直接使用。主要参数说明参见下表。
参数 |
说明 |
|---|---|
|
训练进程的最大重启次数,达到最大值后将判定为子任务失败,通常配置为3次 |
|
训练启动或重启之前,将进行网络检测。检测失败的节点将被标记为故障,不参与训练任务 |
|
掉队检测,需要开启 |
|
网络检测的流程中,增加对于主机环境的switchbox 到GPU之间的光互连检查,默认为 |
|
指定switchbox中的socket配对,格式为 |
|
指定switchbox 到 GPU的最低门限带宽,低于这个值被认定为故障连接,单位为MB/s,默认为 |
|
指定switchbox 到 GPU之间的通道对正常工作的最小通道数,低于这个值被认定为节点故障,默认为 |
备注
dlrover-run 的其他参数与 torchrun 相同,且能自动处理 master_addr 和 master-port 参数,用户无需单独指定。
3.1.4. Flash Checkpoint的Python API应用
本组API接口主要用于训练进程,在保存和读取Checkpoint时,可替换训练框架中的对应代码。
3.1.4.1. DDP框架Flash Checkpoint应用示例
from dlrover.trainer.torch.flash_checkpoint.ddp import (
DdpCheckpointer,
StorageType,)
checkpointer = DdpCheckpointer(checkpoint_dir)
state_dict = {
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"step": step,}# 存储系统的 path
ckpt_path = os.path.join(checkpoint_dir, f"checkpoint-{iter_num}.pt")
# 将 checkpoint 秒级存入到内存中,可以很高频地写。如果训练进程失败,会自动
# 将内存中最近的 checkpoint 写入存储。
if iter_num % save_memory_interval == 0:
checkpointer.save_checkpoint(
step, state_dict, ckpt_path, storage_type=StorageType.MEMORY
)
# 将 checkpoint 异步存入到存储中,可以低频导出,也可以高频导出,但是高频导出会
# 占据很多存储空间,用户需要自行清理老的Checkpoint。
if iter_num % save_storage_interval == 0:
checkpointer.save_checkpoint(
step, state_dict, ckpt_path, storage_type=StorageType.DISK
)
ckpt_dict = checkpointer.load_checkpoint()
model.load_state_dict(ckpt_dict["model"])
optimizer.load_state_dict(ckpt_dict["optimizer"]
3.1.4.2. FSDP框架Flash Checkpoint应用示例
保存Checkpoint的API使用示例如下:
from dlrover.trainer.torch.flash_checkpoint.fsdp import (
FsdpShardCheckpointer,
StorageType,
)
checkpointer = FsdpShardCheckpointer(checkpoint_dir)
with FSDP.state_dict_type(model, StateDictType.SHARDED_STATE_DICT):
state_dict = {
"model": model.state_dict(),
"optim": FSDP.optim_state_dict(model, optimizer),
"step": step,
}
# 存储系统的 directory
ckpt_dir = os.path.join(checkpoint_dir, str(step))
# 将 checkpoint 秒级存入到内存中,可以很高频地写。如果训练进程失败,会自动
# 将内存中最近的 checkpoint 写入存储。
if step % save_memory_interval == 0:
checkpointer.save_checkpoint(
step, state_dict, ckpt_dir, storage_type=StorageType.MEMORY
)
# 将 checkpoint 异步存入到存储中,可以低频导出,也可以高频导出,但是高频导出会
# 占据很多存储空间,用户需要自行清理老的Checkpoint。
if step % save_storage_interval == 0:
checkpointer.save_checkpoint(
step, state_dict, ckpt_dir, storage_type=StorageType.DISK
)
读取Checkpoint的API使用示例如下,storage_reader 配置为 Flash Checkpoint 支持 FSDP 的 reader 即可。
checkpointer = FsdpShardCheckpointer(checkpoint_dir)
with FSDP.state_dict_type(model, StateDictType.SHARDED_STATE_DICT):
state_dict = {
"model": model.state_dict(),
"step": 0,
}
storage_reader = checkpointer.get_storage_reader()
if not storage_reader:
return
dist_cp.load_state_dict(
state_dict=state_dict,
storage_reader=storage_reader,
)
model.load_state_dict(state_dict["model"])
optim_state = load_sharded_optimizer_state_dict(
model_state_dict=state_dict["model"],
optimizer_key="optim",
storage_reader=storage_reader,
)
flattened_osd = FSDP.optim_state_dict_to_load(
model, optimizer, optim_state["optim"]
)
optimizer.load_state_dict(flattened_osd)
3.1.4.3. Megatron-LM框架Flash Checkpoint应用示例
存取Checkpoint的API和Megatron原生类似,使用示例如下:
# from megatron.checkpointing import load_checkpoint
# from megatron.checkpointing import save_checkpoint
from dlrover.trainer.torch.flash_checkpoint.megatron_dist_ckpt import save_checkpoint
from dlrover.trainer.torch.flash_checkpoint.megatron_dist_ckpt import load_checkpoint
from dlrover.trainer.torch.flash_checkpoint.megatron import StorageType
可以选择将Checkpoint保存到内存(StorageType.MEMORY)或者磁盘(StorageType.DISK)。通过StorageType.MEMORY将Checkpoint保存至内存的示例如下:
if args.save and iteration % save_memory_interval == 0:
save_checkpoint(iteration, model, optimizer, num_floating_point_operations_so_far=0,
opt_param_scheduler, storage_type=StorageType.MEMORY,)
args.iteration, _ = load_checkpoint(model, optimizer, opt_param_scheduler)
支持设置备份组的大小,在调用 save_checkpoint 和 load_checkpoint 操作时需指定。
if args.save and iteration % save_memory_interval == 0:
save_checkpoint(iteration, model, optimizer, num_floating_point_operations_so_far=0,
opt_param_scheduler, storage_type=StorageType.MEMORY, replica_count=2)
args.iteration, _ = load_checkpoint(model, optimizer, opt_param_scheduler,replica_count=2)
当前支持的Megatron-LM框架版本 ≥ 0.4.0。
0.5.0版本之前,save_checkpoint 无 num_floating_point_operations_so_far 参数,可传入 0 ;
load_checkpoint 返回 stat_dict 和 num_floating_point_operations_so_far,0.5.0版本之前可忽略 num_floating_point_operations_so_far。
3.2. 基本功能点配置
3.2.1. Spark数据预处理
DLRover提供了基于Spark的分布式处理能力进行训练数据的预处理,借助强大的Spark弹性分布式内存计算能力,可以为常用的训练模型提供快速的数据预处理。 详细的Spark使用参见 Spark官方文档。
以下以Spark在Megatron训练数据预处理中的应用为例,说明Spark的数据预处理能力。
Spark数据预处理关键代码位于 /path/to/dlrover_wheel_package/dlrover/python/preprocess/pyspark_preprocess.py,代码示例如下:
from pyspark.sql import SparkSession
import sys
import os
import lm_dataformat as lmd
import argparse
import numpy as np
import cloudpickle
import ftfy
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__) + '/megatron')))
print(sys.path)
import megatron
from megatron.tokenizer import build_tokenizer
from megatron.data import indexed_dataset
def get_args():
parser = argparse.ArgumentParser()
group = parser.add_argument_group(title="input data")
group.add_argument(
"--input",
type=str,
required=True,
help="Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated "
"list",
)
group.add_argument(
"--jsonl-keys",
nargs="+",
default=["text"],
help="space separate listed of keys to extract from jsonl. Defa",
)
group.add_argument(
"--num-docs",
default=None,
help="Optional: Number of documents in the input data (if known) for an accurate progress bar.",
type=int,
)
group = parser.add_argument_group(title="tokenizer")
group.add_argument(
"--tokenizer-type",
type=str,
required=True,
choices=[
"HFGPT2Tokenizer",
"HFTokenizer",
"GPT2BPETokenizer",
"CharLevelTokenizer",
"TiktokenTokenizer",
],
help="What type of tokenizer to use.",
)
group.add_argument(
"--vocab-file", type=str, default=None, help="Path to the vocab file"
)
group.add_argument(
"--merge-file",
type=str,
default=None,
help="Path to the BPE merge file (if necessary).",
)
group.add_argument(
"--append-eod",
action="store_true",
help="Append an <eod> token to the end of a document.",
)
group.add_argument("--ftfy", action="store_true", help="Use ftfy to clean text")
group = parser.add_argument_group(title="output data")
group.add_argument(
"--output-prefix",
type=str,
required=True,
help="Path to binary output file without suffix",
)
group.add_argument(
"--dataset-impl",
type=str,
default="mmap",
choices=["lazy", "cached", "mmap"],
help="Dataset implementation to use. Default: mmap",
)
group = parser.add_argument_group(title="runtime")
group.add_argument(
"--workers", type=int, default=1, help="Number of worker processes to launch"
)
group.add_argument(
"--log-interval",
type=int,
default=100,
help="Interval between progress updates",
)
args = parser.parse_args()
args.keep_empty = False
# some default/dummy values for the tokenizer
args.rank = 0
args.make_vocab_size_divisible_by = 128
args.model_parallel_size = 1
return args
class Encoder(object):
def __init__(self, args):
self.args = args
self.builders = {}
self.output_bin_files = {}
self.output_idx_files = {}
self.tokenizer = None
def initializer(self):
# Use Encoder class as a container for global data
self.tokenizer = build_tokenizer(self.args)
for key in self.args.jsonl_keys:
self.output_bin_files[key] = '{}_{}_{}.bin'.format(
self.args.output_prefix, key, 'document'
)
self.output_idx_files[key] = '{}_{}_{}.idx'.format(
self.args.output_prefix, key, 'document'
)
return self.tokenizer
def get_builder(self, key):
if key not in self.builders:
self.builders[key] = indexed_dataset.make_builder(
self.output_bin_files[key],
impl = self.args.dataset_impl,
vocab_size = self.tokenizer.vocab_size,
)
return self.builders[key]
def encode(self, text):
if self.args.ftfy:
text = ftfy.fix_text(text)
ids = {}
for key in self.args.jsonl_keys:
doc_ids = []
text_ids = self.tokenizer.tokenize(text)
if len(text_ids) > 0:
doc_ids.append(text_ids)
if self.args.append_eod:
doc_ids[-1].append(self.tokenizer.eod)
ids[key] = doc_ids
return ids, len(text)
def main():
spark = SparkSession.builder.appName('gpt-neox-process').getOrCreate()
args = get_args()
encoder = Encoder(args)
tokenizer = encoder.initializer()
broadcast_encoder = spark.sparkContext.broadcast(cloudpickle.dumps(encoder))
# 读取数据并缓存
lm_rdd = spark.sparkContext.parallelize(lmd.Reader(args.input).stream_data()) \
.repartition(200) # 调整为适当的分区数
# 使用 mapPartitions 替代 flatMap,减少数据传输
def process_partition(partition):
encoder = cloudpickle.loads(broadcast_encoder.value)
results = {key: [] for key in args.jsonl_keys}
for doc in partition:
encoded_doc, _ = encoder.encode(doc)
for key, value_list in encoded_doc.items():
results[key].extend(value_list)
return results.items()
def save_partition(partition):
encoder = cloudpickle.loads(broadcast_encoder.value)
encoder.initializer()
def add_item(key, value):
encoder.get_builder(key)
if isinstance(value, list):
for subitem in value:
if isinstance(subitem, list):
for e in subitem:
encoder.builders[key].add_item(np.array(e, dtype=encoder.builders[key].dtype))
else:
encoder.builders[key].add_item(np.array(value, dtype=encoder.builders[key].dtype))
encoder.builders[key].end_document()
for key, value in partition:
add_item(key, value)
for key in encoder.builders:
encoder.builders[key].finalize(encoder.output_idx_files[key])
lm_map_data = lm_rdd.mapPartitions(process_partition) \
.groupByKey().mapValues(list) \
.persist() # 持久化结果
# 触发计算并将结果保存到文件
result = lm_map_data.foreachPartition(save_partition)
# 清理缓存
lm_rdd.unpersist()
lm_map_data.unpersist()
# 关闭 SparkSession
spark.stop()
if __name__ == "__main__":
main()
Spark数据预处理的执行命令如下:
$ $SPARK_HOME/bin/spark-submit --executor-cores=2 --num-executors=2 ./pyspark_preprocess.py \
--input $DATA_PATH/input/stackexchange_aa.jsonl --output-prefix $DATA_PATH/output/result \
--vocab $DATA_PATH/20B_tokenizer.json --tokenizer-type HFTokenizer --append-eod --jsonl-keys text \
--workers 64 --append-eod
会在 $DATA_PATH/output 目录产生如下2个文件:
result_text_document.bin
result_text_document.idx
3.2.2. Flash Checkpoint异步保存
DLRover 提供异步保存Checkpoint的功能。Flash Checkpoint先同步从GPU保存至内存中,然后再异步持久化到磁盘。
加载Checkpoint时,优先从内存中读取。若内存中找不到,则会去磁盘加载Checkpoint。
保存Checkpoint时,支持选择保存在内存或者磁盘中。
目前分布支持的框架包括Megatron-LM,Torch DDP,Torch FSDP,HuggingFace和DeepSpeed等。详细的API接口参见 3.1.4 Flash Checkpoint的Python API应用。
3.2.3. 网络检查功能开启
训练脚本中,dlrover-run 增加 --network-check 选项开启网络检查的功能。
网络检查发生在训练任务开始之前,对于节点两两分组检查。
对于网络节点检测失败的组,在下一轮和正常的组混合,从而确定故障的节点。
对于故障的节点,DLRover支持标记为污点,新节点会重新加入训练组,确保新调度到的节点没有故障。
在执行 fine_tuning.py 脚本之前,会做网络检查。示例如下:
"dlrover-run --nnodes=$NODE_NUM --network-check \
--nproc_per_node=1 --max_restarts=1 \
./examples/pytorch/llama2/fine_tuning.py \
./examples/pytorch/llama2/btc_tweets_sentiment.json"
3.2.4. 动态资源扩缩容配置
dlrover-run 支持复用Torch的 --nnode 选项设置最大最小节点个数。当集群节点数量发生变化且满足约束条件时,DLRover支持扩缩容后重新开始训练。
当训练任务下发以后,如果有新的节点加入,只要满足节点数约束,DLRover会扩容后重新开始训练任务。
如果训练的节点发生故障且没有新节点加入时,只要满足节点数约束,DLRover会缩容后重新开始训练任务。
目前动态资源扩缩容仅支持Torch DDP模型。
在执行分布式训练的过程中,满足 min ≤ 节点数量 ≤ max 时,训练将立即开始。示例如下:
"dlrover-run --nnodes=min:max \
--nproc_per_node=1 --max_restarts=1 \
./examples/pytorch/llama2/fine_tuning.py \
./examples/pytorch/llama2/btc_tweets_sentiment.json"
3.2.5. 故障恢复与重启次数的配置
目前通过训练的YAML配置以及 dlrover-run 的配置设置重启的次数。
dlrover-run 通过设置 --max-restarts 指定子任务的重启次数,重启次数超过指定次数以后,训练的脚本会退出,子任务重启。主要应用在通过重启Python进程能恢复的故障。
通过训练的YAML配置 spec.replicaSpecs.worker.restartCounts 可以设置整个弹性训练中该rank的重启次数,即该rank旧的pod退出后分配新的pod的次数。
重启次数超过指定次数以后,训练任务会退出。主要应用在换节点也无法恢复的故障,该故障可能与训练框架有关。
在执行 fine_tuning.py 脚本的故障恢复时,如果没有超过3次,会在原节点自动重启训练子任务尝试恢复。示例如下:
"dlrover-run --nnodes=$NODE_NUM \
--nproc_per_node=1 --max_restarts=3 \
./examples/pytorch/llama2/fine_tuning.py \
./examples/pytorch/llama2/btc_tweets_sentiment.json"
YAML文件如下,指定了弹性训练中该rank的重启次数为 3:
apiVersion: elastic.iml.github.io/v1alpha1
kind: ElasticJob
metadata:
name: fine-tuning-llama2
namespace: dlrover
spec:
distributionStrategy: AllreduceStrategy
optimizeMode: single-job
replicaSpecs:
worker:
replicas: 4 # 任务数量
restartCounts: 3 #重启次数
template:
spec:
restartPolicy: Never
containers:
- name: main
# yamllint disable-line rule:line-length
image: registry.cn-hangzhou.aliyuncs.com/intell-ai/dlrover:llama-finetuning # 训练镜像
imagePullPolicy: Always
command: # 训练执行命令
- /bin/bash
- -c
- "dlrover-run --nnodes=$NODE_NUM \
--nproc_per_node=1 --max_restarts=1 \
./examples/pytorch/llama2/fine_tuning.py \
./examples/pytorch/llama2/btc_tweets_sentiment.json"
resources:
limits:
cpu: "8"
memory: 16Gi
metax-tech.com/gpu: 8 # 单个任务申请的GPU数量
3.2.6. 基于网络拓扑感知的调度优化
DLRover提供了基于网络拓扑感知的调度优化功能。支持通过configmap配置的方式,输入节点的网络拓扑,根据configmap配置的网络拓扑,对训练的集群节点进行排序。
默认情况下名称为 node-topology-config 的configmap配置为空,会随机给训练任务节点分配rank号;需要添加网络拓扑配置情况下,支持通过 kubectl edit 编辑网络拓扑配置。
排序后的节点集群网络的拓扑关系上邻近的节点拥有相邻的rank号。
目前的排序规则只负责按照集群节点上一层交换机从属关系编排rank号。
在执行任何分布式训练任务或网络测试之前,检查编辑网络拓扑的configmap配置。示例如下:
$ kubectl describe configmap node-topology-config -n dlrover
Name: node-topology-config
Namespace: dlrover
Labels: app.kubernetes.io/managed-by=Helm
Annotations:
Data
====
topology_config:
----
asw-0 psw-0 192.168.0.0
asw-1 psw-0 192.168.0.1
asw-2 psw-0 192.168.0.2
asw-3 psw-0 192.168.0.3
asw-0 psw-0 192.168.0.4
asw-1 psw-0 192.168.0.5
asw-2 psw-0 192.168.0.6
asw-3 psw-0 192.168.0.7
asw-0 psw-0 192.168.0.8
asw-1 psw-0 192.168.0.9
BinaryData
====
如需新建或修改网络拓扑的configmap配置,可以编辑Helm values.yaml 的 topoMapper. topology_config 字段,执行以下命令更新Helm Chart。
$ helm upgrade -n dlrover <release_name> <path_to_chart>
使用 kubectl logs -n dlrover <master-pod name> 命令检查日志会提供按rank排序的IP列表。
备注
配置拓扑排序后,训练的故障恢复必须从磁盘恢复。
3.2.7. 基于switchbox网络拓扑的网络检查
DLRover提供了基于switchbox网络拓扑的网络检查功能。可以检查单机GPU到switchbox之间的网络链路状态。单机检查采用 GPUA-switchbox-GPUB 的方式两两分组检测。发现链路故障后,会将单机设置污点,避免被调度到。
训练脚本中, dlrover-run 增加如下选项配置网络检查功能:
--switchbox-check:开启switchbox网络检查,需要在network-check开启之后使用。--box-pairs:指定switchbox中的socketid对,默认为0:1 2:4 3:5 6:7四对。--min-bandwidth:指定GPU到switchbox之间的最低门限带宽(MB/s),默认为10000MB/s,低于该设置值会被认定为链路故障。--min-channels:指定switchbox 到 GPU之间的通道对正常工作的最小通道数,默认为2组。
开启switchbox网络故障检测的配置示例如下:
"dlrover-run --network-check --switchbox-check --nnodes=$NODE_NUM \
--nproc_per_node=1 --max_restarts=3 \
./examples/pytorch/llama2/fine_tuning.py \
./examples/pytorch/llama2/btc_tweets_sentiment.json"
3.2.8. 基于xpu_timer的hang检测
xpu_timer 可以hook核函数并注入计时函数,基于计时函数判断指定核函数的执行时间是否超时。超时后会推送指标到server,标志该rank为hang住的状态, 并输出hang住的进程的栈信息。 用户通过查看多个hang进程合并后的Python和C的调用栈,分析具体hang的原因。
安装
执行以下命令安装xpu_timer:
pip install py_xpu_timer-1.1+maca231-cp310-cp310-linux_x86_64.whl
基本配置
通过
xpu_timer_launch python xxx.py加载程序。环境变量
XPU_TIMER_HANG_TIMEOUT:hang超时时间,缺省300秒XPU_TIMER_TIMELINE_PATH:进程调用栈stacktrace和timeline输出的路径,缺省/root/timeline
通过
xpu_timer_stacktrace_viewer --path /root/timeline合并调用栈,分别合并Python和C的调用栈。每个线程一个堆栈。合并堆栈命名规则为:
func@source_path@stuck_rank|leak_rankfunc:表示当前函数名,如果 gdb 获取不到会显示??source_path:表示这个函数符号在代码中的源地址stuck_rank:表示哪些 rank 的栈被合并,连续的 rank 号会折叠为 start-end,如 rank 0,1,2,3 折叠为0-3leak_rank:表示哪些rank 的栈没有被合并,连续的 rank 号也会折叠
示例
以两机llama2 7b 训练为例子,过程中reset 网卡触发超时。
reset网卡5分钟之后,部分的rank报hang超时(1,2,3,9,11~15),hang超时的rank输出相应的stacktrace文件到指定的目录。
通过工具
xpu_timer_stacktrace_viewer --path /root/timeline合并调用栈, 生成 cpp_stack.svg 和 py_stack.svg,如图 3.1 所示。
图 3.1 输出的stacktrace文件及合并后的svg文件
Python的调用栈如图 3.2 所示,可以看到部分卡在forward的P2P通信,部分卡在backward的P2P通信,这是底层网络故障导致的。
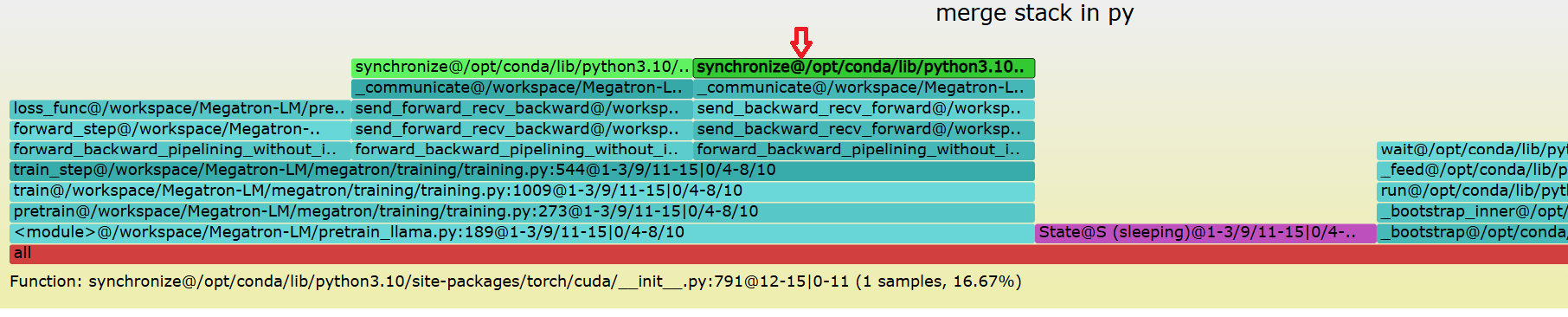
图 3.2 py_stack.svg示例