5. PyTorch精度对比工具
PyTorch精度对比工具支持在PyTorch脚本中插入接口,用来记录和保存PyTorch的Python op API的输入输出tensor信息,并提供接口比较不同device输出的tensor的精度异同,从而方便在复杂网络中定位到MXMACA算子相对CUDA算子哪个算子产生了较大的误差及误差是多少。
5.1. 接口介绍
5.1.1. start_record
start_record(enabled: bool, output_dir: str = "./record_dir", record_level: int = 2, record_stack = True, record_input: bool = True, record_output: bool = True, op_range: List[str] = [], op_list: List[str] = [], skip = 0, process_group = None, ranks = []) -> None
功能描述:初始化精度工具,从start_record开启之后的Python算子会被record。
参数说明:
enabledbool类型,控制是否启用精度工具,初始化工具配置,默认值为
True。output_dirstring类型,record数据存储路径,默认为存储在当前路径的 record_dir 目录。
record_levelint类型,控制dump算子的输入和输出信息的详细程度,取值包括
2、1和0,默认为2。Level 2:表示dump该算子输入输出的所有信息,包含Tensor的完整信息。
Level 1:表示不会dump Tensor的完整信息,只包含Tensor的概述信息(我们定义的TensorSummary类型包含了Tensor的数据类型、形状、步长、元素最大值和最小值)。
Level 0:表示不会dump算子的输入输出信息。
record_stackbool类型,是否record算子的Python端调用栈信息,默认为
True。反向算子是hook函数的调用栈,随算子的输入或者输出信息一起保存到一个文件。record_inputbool类型,是否record算子的输入信息,默认为
True。record_outputbool类型,是否record算子的输出信息,默认为
True。op_rangeList[str]类型,控制record信息范围。只能传空列表、包含Python端API信息的字符串或者None,长度为2的列表,例如:
["torch.nn.Conv1d.6.fwd", "torch.nn.AdaptiveAvgPool2d.256.bwd"]、[None, "torch.nn.AdaptiveAvgPool2d.256.bwd"]、["torch.nn.Conv1d.6.fwd", None]。None表示不限制record的开始或者结束边界。
字符串由3部分组成:算子的API官方名称、按照执行时间顺序对应的是第几个前向算子、前向(fwd)还是反向(bwd)。该控制范围前闭后开,默认为空列表,表示不限制record范围。
p_listList[str]类型,控制record的具体前反向算子。字符串命名规则同
op_range,并且支持指定某一类API。 例如:api_list=["relu"]会record包含torch.relu、torch.relu\_、torch.Tensor.relu、torch.nn.ReLU和torch.nn.functional.relu\_等前反向算子。 默认为空列表,表示不限制算子。skipint类型,表示每间隔
skip次op后record一次。默认为0。process_grouptorch.distributed.ProcessGroup类型,表示需要record的进程组。默认为None,表示只会record默认进程组,如果不是分布式场景,不需要设置该参数。 有关进程组的详细内容,参见PyTorch官方分布式模块相关文档。ranksList[int]类型,表示需要record进程组里面的哪些进程。默认为空列表,表示不限制。
5.1.2. record
record(enabled: bool, output_dir: str = "./record_dir", record_level: int = 2, record_stack = True, record_input: bool = True, record_output: bool = True, op_range: List[str] = [], op_list: List[str] = [], skip = 0, process_group = None, ranks = []) -> None
功能描述:上下文管理器,方便控制record范围,功能同 5.1.1 start_record。
参数说明:同 5.1.1 start_record。
5.1.3. record_switch
功能描述:开关record功能。
参数说明:
enabledbool类型,是否开启record数据,无默认值。
5.1.4. gen_report
gen_report(dir0: str, dir1: str, output_dir: str = "./") -> None
功能描述:输入record生成的算子tensor目录,生成逐tensor的误差、tensor的概述信息和相关调用栈信息的excel表格报告。
参数说明:
dir0string类型,device0的record数据路径,无默认值。
dir1string类型,device1的record数据路径,无默认值。
output_dirstring类型,比较结果的输出目录。默认为输出到当前目录。
5.2. 生成文件介绍
PyTorch精度工具,当开启 start_record 后会在指定的 output_dir 下生成pt文件,使用 gen_report 分析不同device的 output_dir 可以生成对比的excel表格。
pt文件:pt文件有自己的命名方式,例如:
torch.nn.Conv1d.6.fwd指的是前向第6个算子,这个算子是torch.nn.Conv1d
torch.nn.AdaptiveAvgPool2d.256.bwd,指的是反向第256个算子,算子是torch.nn.AdaptiveAvgPool2d
excel表格:如下图,生成的excel表格中包括device0和device1对应算子输入输出tensor的数据类型,shape,最大最小值以及diff1(相对误差)diff2(标准差),和op的Python调用栈。

图 5.1 生成文件
5.3. 使用流程
分别在device0(如CUDA-GPU或CPU)和device1(如MXMACA-GPU)上运行精度比较工具,保存网络训练中间数据。
再次运行精度比较工具比对device0和device1保存下来的数据,计算误差并输出比对结果。
gen_report分析比对结果,分析的过程类似二分法,设置一个比较大的skip数(加快速度),找出导致误差大的算子。 如果没有找到误差大的算子,则需要重新调整record范围减小skip数,再次record。 如果找到误差大的算子,说明这个op_range存在误差大的算子,但由于skip存在这个误差大的算子只是skip的区间末尾,所以应该将skip设置为0找到具体某个op导致的精度误差。
下面是一个简单的测试用例, start_record 和 record_switch(False) 之间的op将被record:
import torch
import torch.nn as nn
import copy
from maca_tools import accuracy
dtype = torch.float16
shape, out_c, k, s, p, d, g = (256, 1, 3600), 4, 5, 1, 2, 1, 1
input = torch.randn(shape, dtype = dtype, device="cpu")
input_d = input.clone().cuda()
m = nn.Conv1d(shape[1], out_c, k, stride = s, padding = p, dilation = d, groups = g, dtype = dtype)
m_d = copy.deepcopy(m)
m_d = m_d.to("cuda")
accuracy.start_record(record_level=2)
output = m_d(input_d)
accuracy.record_switch(False)
如果执行kernel过多,则需要重新调整record范围减小skip数再次record。
下述案例为skip=10,表示每间隔10次op后record一次,统计到torch.nn.Conv1d.6.fwd结束。
import torch
import torch.nn as nn
import copy
from maca_tools import accuracy
dtype = torch.float16
shape, out_c, k, s, p, d, g = (256, 1, 3600), 4, 5, 1, 2, 1, 1
input = torch.randn(shape, dtype = dtype, device="cpu")
input_d = input.clone().cuda()
m = nn.Conv1d(shape[1], out_c, k, stride = s, padding = p, dilation = d, groups = g, dtype = dtype)
m_d = copy.deepcopy(m)
m_d = m_d.to("cuda")
accuracy.start_record(record_level=2, skip=10, op_range=[None, "torch.nn.Conv1d.6.fwd"])
output = m_d(input_d)
accuracy.record_switch(False)
在CUDA运行时,安装maca_tools的方法如下:
通过以下命令解压MXMACA torch的wheel包,在当前目录下会得到maca_tools的文件夹。
unzip torch-*.whl在CUDA环境下,将上述解压获得的maca_tools拷贝到环境中wheel包存放的目录。
cp -r maca_tools/ $(pip show torch | grep Location | awk '{print $2}')
其余部分CUDA运行方式与MXMACA相同,同上所述。
5.4. 注意事项
保证两次record过程调用的算子数量和算子顺序一致。
为使比较结果更准确,需提前消除网络计算中的随机性和因算子算法差异导致的比对误差等干扰因素。
如果存在有算子API在工具初始化之前被导入,可能会导致错过Python接口劫持时机,进而导致这些Python接口不会被record。
算子可能record不完整,具体表现在:该工具只能record Python侧op,如果这个Python op对应的是多个C++拼接实现的算子,只是record最后那个C++算子的输出。
目前不能单独record反向算子的相关信息,必须带上相应的前向算子。
开启record功能的网络性能会有一定程度下降。保存信息庞大,用户需预留足够空间存放。
本工具跟PyTorch版本绑定,不保证其他版本的PyTorch也能使用。
分布式多卡训练时,start_record需要在init_process_group初始化之后执行。
网络脚本中如果直接调用torch._C._VariableFunctions.xxx或者torch._C._TensorBase.xxx这两种PyTorch内部使用的接口,目前无法record。
暂不支持record少数不在API返回值中的原位算子的输出,如: torch.Tensor.__setitem__、torch._amp_foreach_non_finite_check_and_unscale_。
暂不支持record少数不涉及计算的tensor构造类API,包括torch.tensor、torch.empty、torch.empty_like、torch.empty_strided、torch.empty_quantized。
暂不支持record torch.Tensor.__getitem__。
不支持record工具初始化所在进程的子进程和子线程的算子的输入输出信息。
不支持导出torch.Generator类型的算子参数的完整信息。
不支持record稀疏Tensor、量化Tensor、NestedTensor及相关算子的输入输出信息。
不支持record通信原语。
不支持record torch.jit.script后的ScriptModule和ScriptFunction的输入和输出信息。
由于torch.Tensor.uniform\_.fwd算子的input为随机值,因此可以忽略。
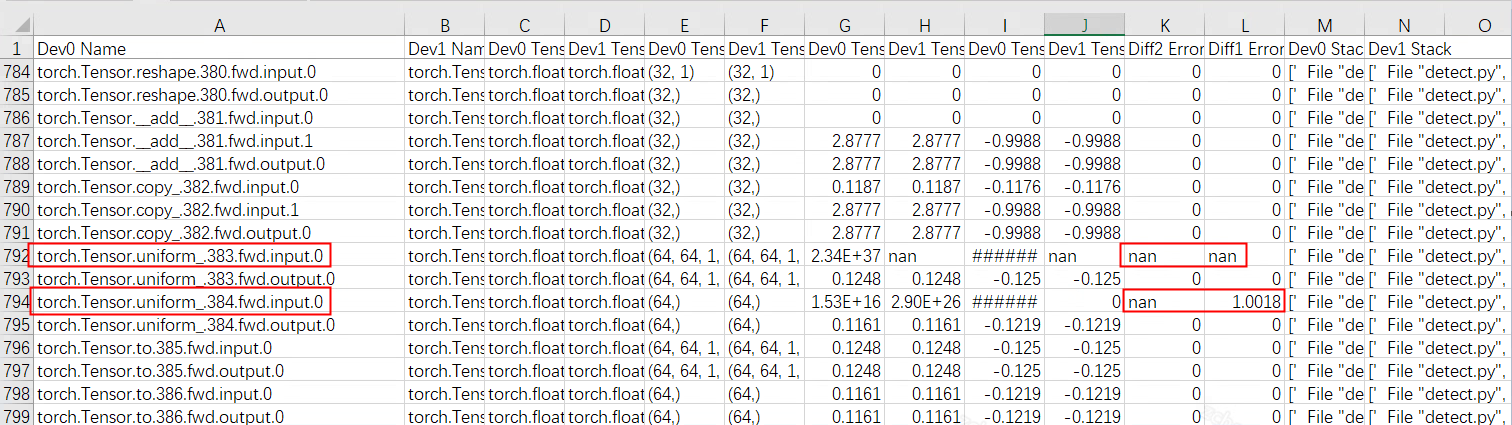
图 5.2 input示例