3. 编程模型
本章节描述了MXMACA编程模型的几个主要概念。
3.1. GPGPU
GPU的处理内核远多于CPU。GPU最初用于图形处理,后来也用于向量计算和浮点运算,并逐渐用于很多高度并行计算的应用,进而衍生出了GPGPU,如图 3.1 所示。
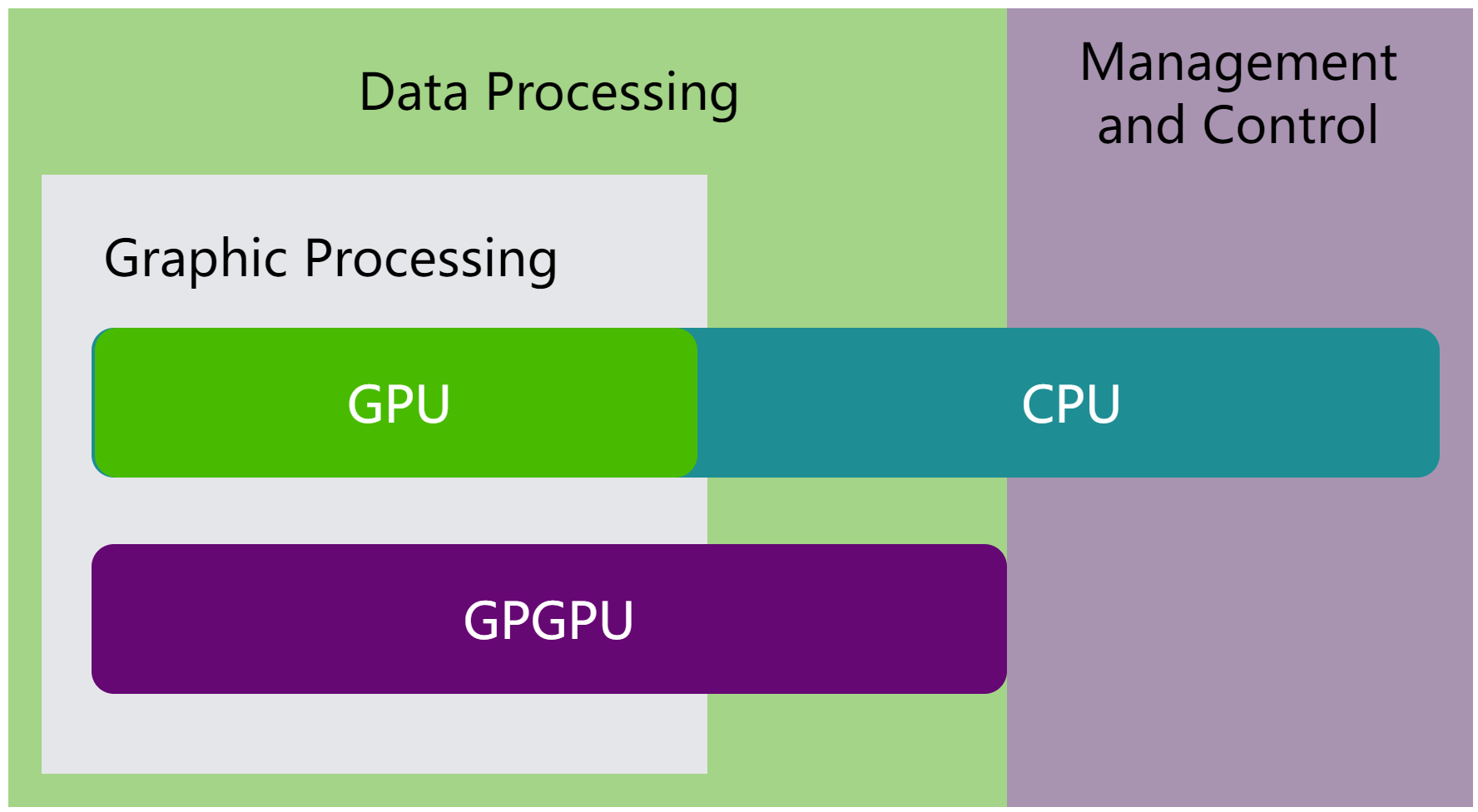
图 3.1 CPU、GPU和GPGPU概念介绍
GPGPU擅长并行计算,分解是并行处理的核心。分解指的是:
将算法划分为单独的任务
将数据集划分为可并行操作的离散块
通常,应用程序由并行计算和顺序计算混合组成,因此系统采用GPU和CPU的混合设计,以最大限度地提高系统整体性能。
3.2. MXMACA:通用并行计算平台和编程模型
MXMACA® 是一个通用并行计算平台和编程模型,主要用于开发高度并行性的应用程序并部署在沐曦GPU上。
MXMACA的软件环境允许开发人员使用C++作为高级编程语言。MXMACA软件栈如图 3.2 所示。
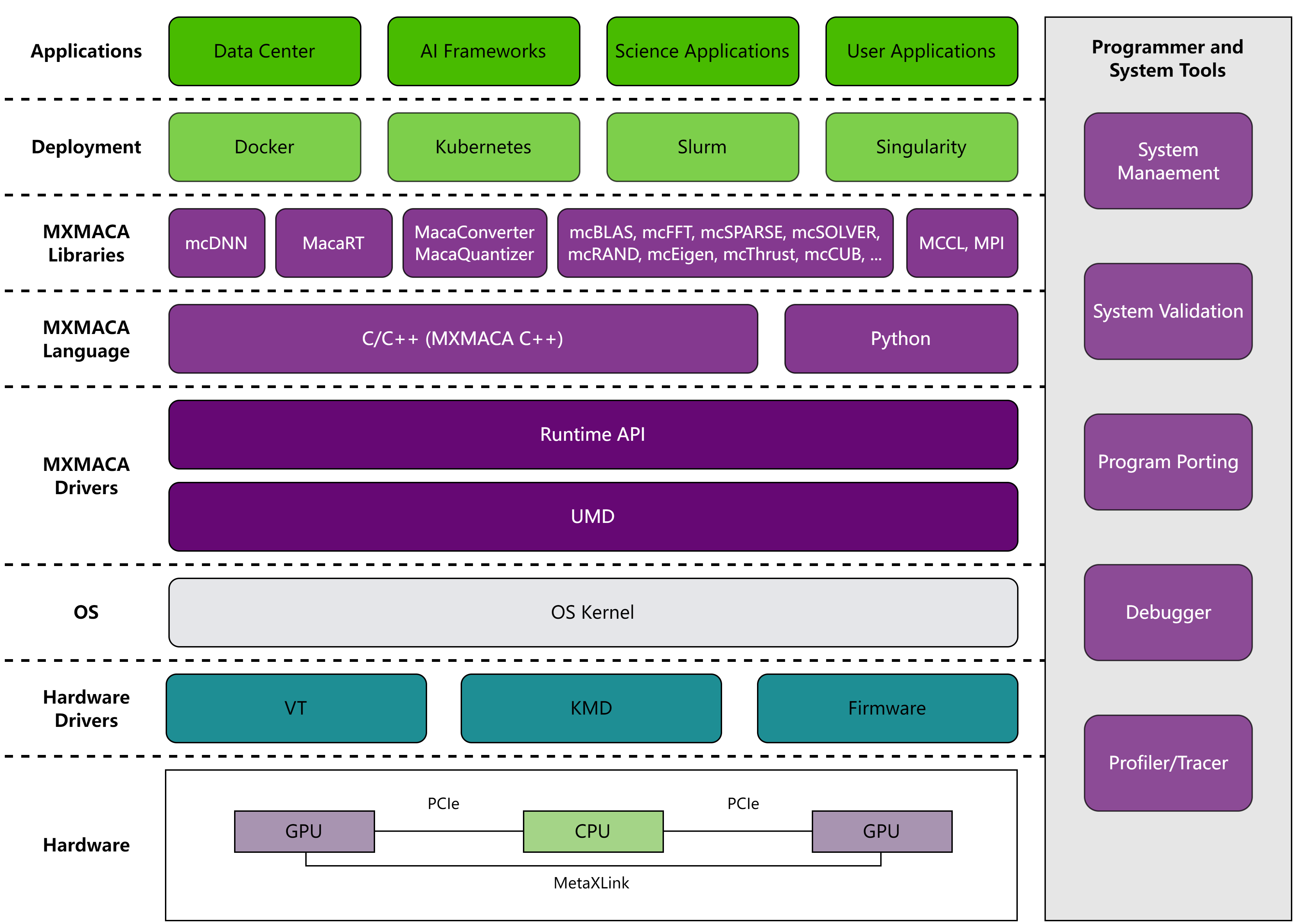
图 3.2 MXMACA软件栈
MXMACA支持使用C/C++编程语言,且包括以下功能:
Templates
C++11 Lambdas
Classes
namespaces等
使用mxcc编译MXMACA C++代码,构建在沐曦GPU平台上运行的MXMACA程序。MXMACA提供以下API接口:
MXMACA运行时库:实现MXMACA在功能模块上的运行时API,例如设备管理,流管理,内存管理,执行控制,事件管理等。
MXMACA人工智能和计算库(AI & Compute Library,ACL):为沐曦GPU定制的加速库,用于机器学习,数值分析和量子计算等现场应用。
MXMACA也为开发人员提供了一套专业的记录、跟踪、分析、部署和现场维护工具。
MXMACA平台支持多个GPU的并行计算,可以通过PCIe或MetaXLink在节点内,也可通过InfiniBand或以太网上的RDMA跨节点进行。 沐曦集合通信库(MetaX Collective Communication Library,MCCL)可用于多GPU编程,通过隐藏低级通信的细节来简化编程。