1. 概述
本文档主要用于指导用户如何使用MacaRT推理引擎,并快速有效地将训练好的模型部署到曦云® 系列GPU上。
1.1. MacaRT介绍
MacaRT(MXMACA® Runtime)是在曦云系列GPU上进行人工智能算法模型部署和执行的推理引擎,它是在ONNX Runtime上扩展了MXMACA后端。 在进行推理时,只需指定MXMACA Execution Provider(MacaEP)就可以在曦云系列GPU上完成模型推理。MacaRT的使用方法与ONNX Runtime完全兼容。
MacaRT进行模型推理的整体架构,如图 1.1 所示,可以分为以下部分:
解析ONNX模型,获取模型图和参数信息
对模型图进行处理,包括图优化、图拆分、图编译等
通过MacaEP在曦云系列GPU上执行模型
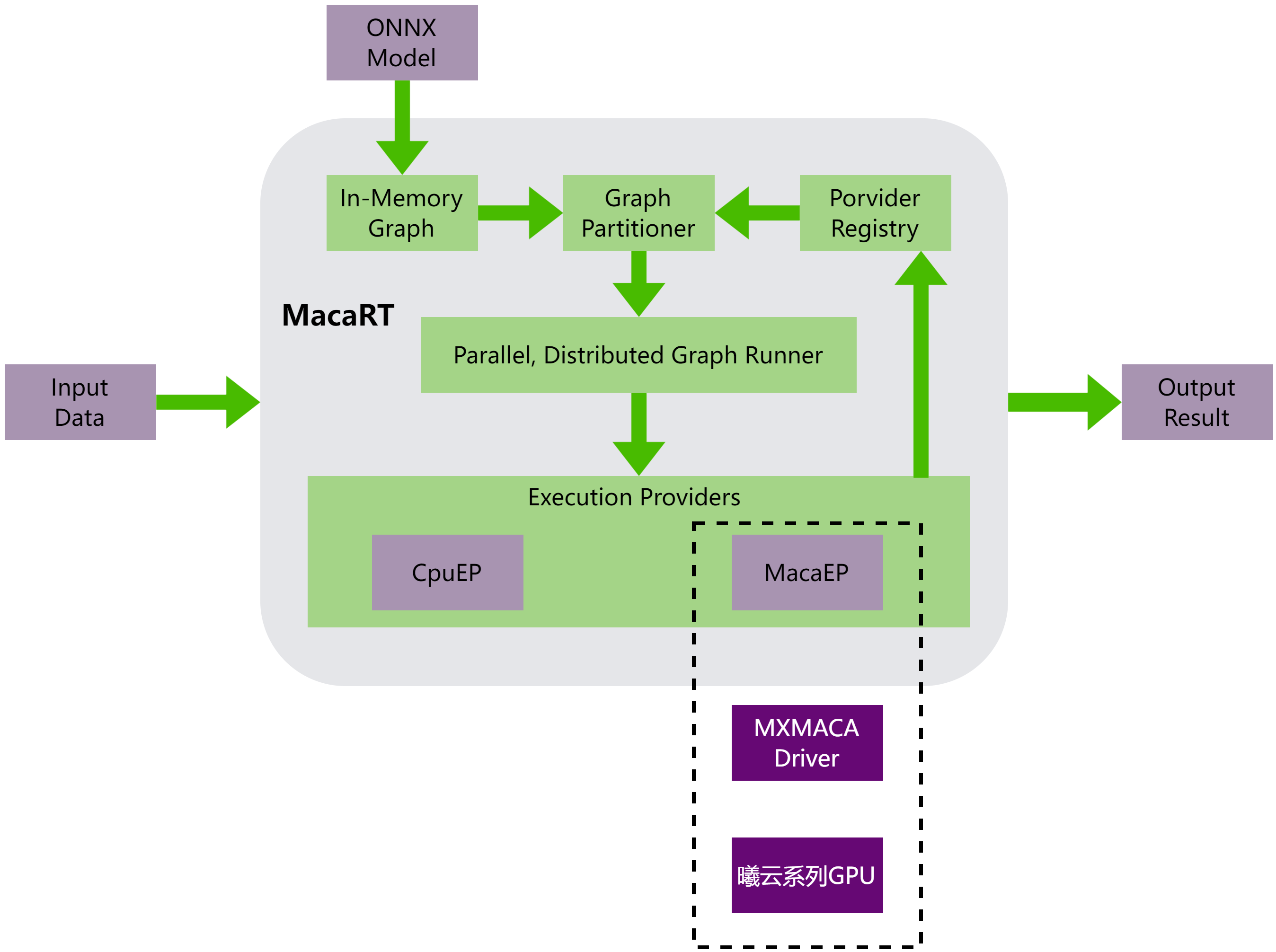
图 1.1 MacaRT的模型推理整体架构
1.2. MacaRT功能
MacaRT包含了以下的功能和特性:
MacaRT提供了C++和Python接口
支持多种模型数据类型,包括float32、float16、int8、uint8等
支持动态Batch推理
支持多线程调用和多进程调用
支持模型图优化、模型量化等特性
MacaRT工具链,包括MacaConverter、MacaPrecision、MacaQuantizer