还是一样的报错,这不是缺依赖的问题吗,怎么总用mx-smi在卡上找原因
Cafba
- Members
- Joined 2025年12月9日
-
-
刚创建了一个,另外论坛没有删帖功能吗,好像发了两个一模一样的帖子
apiVersion: v1 kind: Pod metadata: name: sample-pod spec: schedulerName: hami-scheduler containers: - name: ubuntu image: ubuntu:22.04 imagePullPolicy: IfNotPresent command: ['bash', '-c'] args: ["sleep infinity"] resources: limits: metax-tech.com/sgpu: 1 # requesting 1 GPU metax-tech.com/vcore: 60 # requesting 60% compute of full GPU metax-tech.com/vmemory: 4 # requesting 4 GiB device memory of full GPU -
一、软硬件信息
1.服务器厂家:
2.沐曦GPU型号:C550
3.操作系统内核版本:Linux mx-oam-151 5.15.0-58-generic #64~20.04.1-Ubuntu SMP Fri Jan 6 16:42:31 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
4.是否开启CPU虚拟化:开启
二、具体问题1
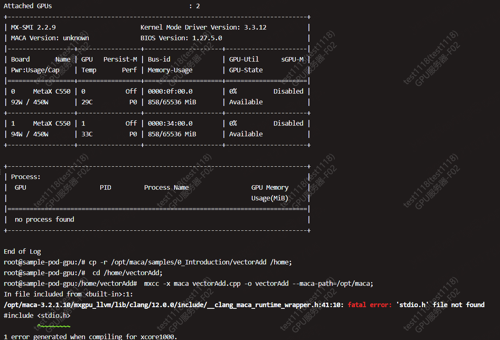
GPU-Operator部署后使用的SDK如图,
创建的pod如下apiVersion: v1 kind: Pod metadata: name: task-sample-pod-2 spec: schedulerName: hami-scheduler containers: - name: ubuntu-task image: docker.io/ubuntu:20.04 imagePullPolicy: Never command: [ "bash", "-c", "cp -r /opt/maca/samples/0_Introduction/vectorAdd /home; cd /home/vectorAdd; mxcc -x maca vectorAdd.cpp -o vectorAdd --maca-path=/opt/maca; ./vectorAdd > log/vectoradd_exec_output.log; tail -f /dev/null", ] resources: limits: metax-tech.com/sgpu: 1 # requesting 1 GPU metax-tech.com/vcore: 40 # requesting 60% compute of full GPU metax-tech.com/vmemory: 4 # requesting 4 GiB device memory of full GPU报错如下:
三、具体问题2
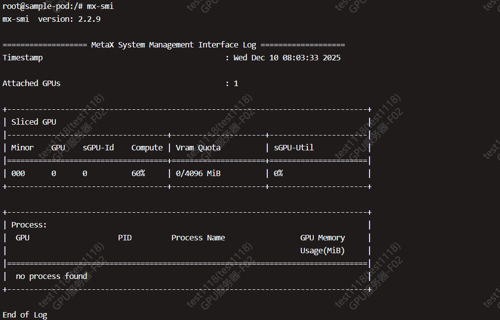
如果新创建一个 pod,会显示
Allocate failed due to rpc error: code = Unknown desc = set 0000:c2:00.0 model error write /proc/1/root/sys/bus/pci/devices/0000:c2:00.0/model: device or resource busy, which is unexpected
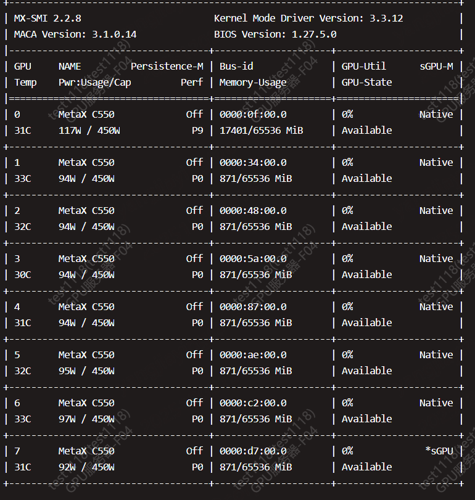
但mx-smi如下,并没有使用第二张卡