vllm-metax:0.15.0-maca.ai3.5.3.203-torch2.8-py310-ubuntu22.04-amd64
0.15.0版本的镜像已经可以支持qwen3.5了,欢迎前往开发者社区软件下载
vllm-metax:0.15.0-maca.ai3.5.3.203-torch2.8-py310-ubuntu22.04-amd64
0.15.0版本的镜像已经可以支持qwen3.5了,欢迎前往开发者社区软件下载
developer.metax-tech.com/developer/blog
详见PDE AI Release Announcement内容
SMI使用手册里面有,去沐曦开发者的文档里面可以找到最新版本
developer.metax-tech.com/api/client/document/preview/334/index.html
发表于 2025-4-18 09:39:22 | 只看楼主 | 阅读模式打印 上一主题 下一主题
GPU 实现 多种精度 精度计算的方法
一、硬件架构支持
CUDA Core 核心驱动
多种精度 多种精度计算主要由 CUDA Core 实现,其通过并行处理架构支持高精度浮点运算,适用于科学模拟、气候建模等需高精度的场景。
计算单元设计:每个 CUDA Core 支持 多种精度 的乘加运算(FMA),通过增加 SM(流式多处理器)中的核心数量提升吞吐量。
性能指标:例如 H100 GPU 的 多种精度 理论性能为 67 TFLOPS,而阉割版 H20 仅 44 TFLOPS,核心数量直接影响算力。
显存与带宽优化
高带宽显存(HBM):如 H200 显存带宽达 4.0 TB/s,确保 多种精度 计算时数据高速传输。
NVLink 互联:多 GPU 并行时通过 NVLink(如 H100 的 900 GB/s)减少通信延迟,提升大规模 多种精度 任务的扩展性。
二、软件与指令优化
混合精度加速策略
动态精度切换:在保证精度的前提下,通过混合精度(如 多种精度 与 FP32 结合)减少计算量,例如部分科学计算任务仅关键步骤使用 多种精度。
CUDA 数学库:调用 cuBLAS、cuSOLVER 等库优化 多种精度 矩阵运算,利用算法级并行减少冗余计算。
指令集与调度优化
FMA 指令融合:单个指令完成乘法和加法操作,提升 多种精度 计算效率(如 多种精度 FMA 指令吞吐量达 1/2 峰值)。
任务分块与流水线:将大规模 多种精度 计算拆分为小块,通过 GPU 流水线并行处理,减少显存占用和延迟。
三、应用场景与资源配置
场景 资源配置要点 案例
科学计算 高 CUDA Core 占比 + 高显存带宽 H100 用于气候建模,多种精度 算力 67 TFLOPS
工程仿真 多 GPU NVLink 互联 + 混合精度调度 Ansys 仿真软件优化 多种精度 并行负载
金融建模 低延迟显存 + 高指令吞吐量 蒙特卡洛模拟通过 多种精度 确保数值稳定性
四、限制与权衡
算力与功耗平衡
多种精度 计算功耗显著高于 FP32/FP16,需通过动态频率调节(如 NVIDIA 的 PowerBoost)优化能效比。
Tensor Core 不参与 多种精度
Tensor Core 专注低精度加速(如 FP16/INT8),多种精度 计算依赖传统 CUDA Core,需针对性分配计算资源。
总结
GPU 实现 多种精度 计算的核心方法包括:CUDA Core 架构优化、高带宽显存与 NVLink 支持、混合精度与指令级优化。实际应用中需根据任务需求平衡精度、算力及功耗,例如科学计算优先选择 H100/A100 等 CUDA Core 密集型 GPU。
本帖最后由 inkstone 于 2025-4-6 11:09 编辑
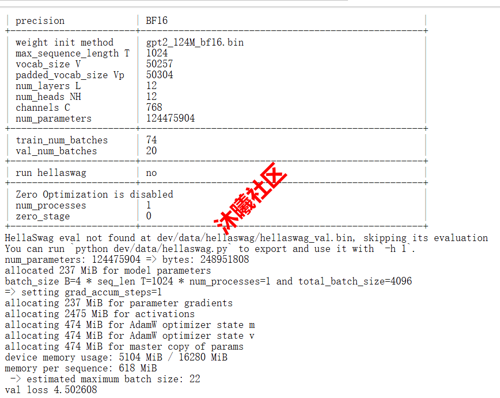
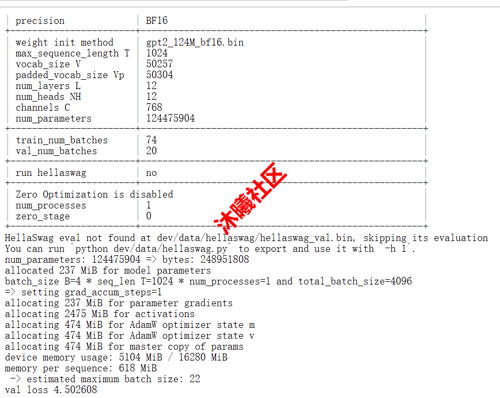
支持 CUDA语言持续开发和自动迁移到沐曦GPU,新增 MXMACA 原生语言开发支持:
gitee.com/Inkstoneydz/llm.c/tree/master/dev/maca
楼主| inkstone 注册会员 发表于 2025-4-6 10:45:11 | 只看该作者
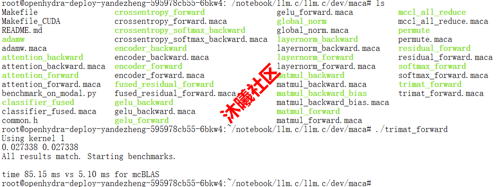
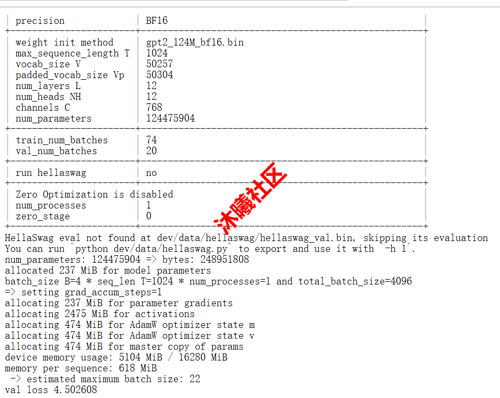
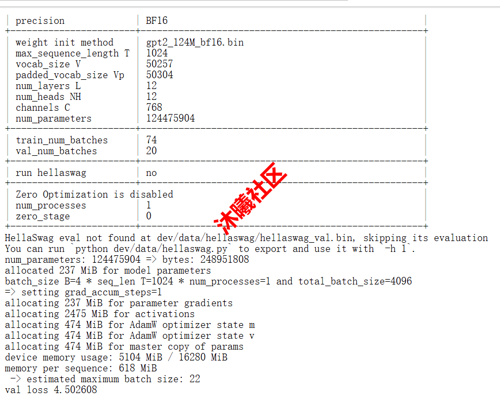
在 METAX GPU 算力切分后的某虚拟机上运行截图
本帖最后由 inkstone 于 2025-4-6 10:46 编辑
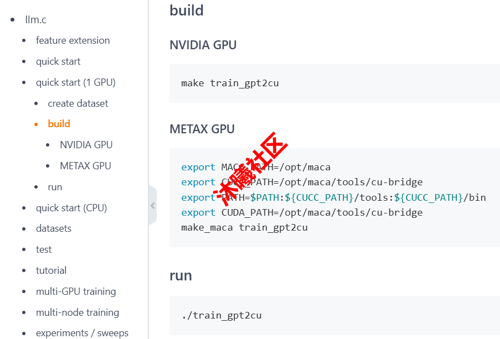
具体操作不同点(NVIDIA GPU vs METAX GPU)
gitee.com/Inkstoneydz/llm.c#build