1. 概述
本文档主要用于指导用户如何使用MacaRT推理引擎,并快速有效地将训练好的模型部署到曦云® 系列GPU上。
1.1. MacaRT介绍
MacaRT(MXMACA® Runtime)是在曦云系列GPU上进行人工智能算法模型部署和执行的推理引擎,它是在ONNX Runtime上扩展了MXMACA后端。 在进行推理时,只需指定MXMACA Execution Provider(MacaEP)就可以在曦云系列GPU上完成模型推理。MacaRT的使用方法与ONNX Runtime完全兼容。
MacaRT进行模型推理的整体架构,如图 1.1 所示,可以分为以下部分:
解析ONNX模型,获取模型图和参数信息
对模型图进行处理,包括图优化、图拆分、图编译等
通过MacaEP在曦云系列GPU上执行模型
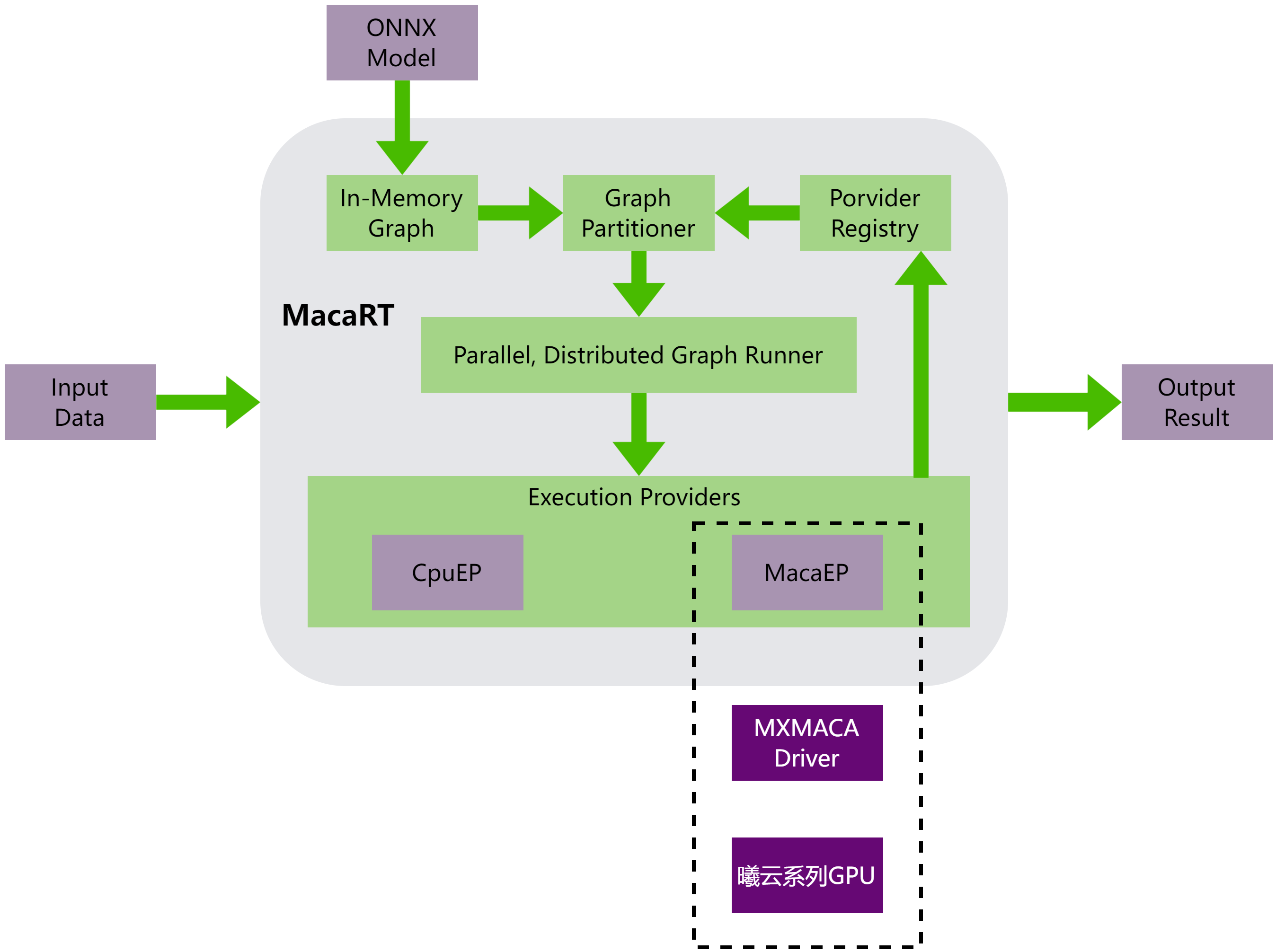
图 1.1 MacaRT的模型推理整体架构
1.2. MacaRT功能
MacaRT包含了以下的功能和特性:
MacaRT提供了C++和Python接口
支持多种模型数据类型,包括float32、float16、int8、uint8等
支持动态Batch推理
支持多线程调用和多进程调用
支持模型图优化、模型量化等特性
MacaRT工具链,包括MacaConverter、MacaPrecision、MacaQuantizer
2. 环境依赖及MacaRT安装
2.1. 环境依赖
在使用MacaRT之前,必须确保服务器已安装曦云系列GPU板卡及其驱动程序。
2.2. 安装MacaRT
操作步骤
执行以下命令,快速安装MacaRT的deb软件安装包。deb软件安装包可以在相应GPU的软件发布包中找到。
dpkg -i onnxruntime-maca_*.deb
安装结束后,MacaRT相关文件均会安装到/opt/maca-ai/onnxruntime-maca目录中。
2.2.1. MacaRT C++
操作步骤
执行以下命令,快速验证是否已正确安装MacaRT C++库。
/opt/maca-ai/onnxruntime-maca/bin/maca_test --model_dir /opt/maca-ai/onnxruntime-maca/sample/test_add --check_mode 1
对获取到的test_add中模型在CpuEP和MacaEP上执行的结果进行对比,若对比结果相同则代表正确安装了MacaRT。
2.2.2. MacaRT Python
MacaRT Python版本的wheel安装包可在/opt/maca-ai/onnxruntime-maca/python中发现。 在安装wheel包之前,须确保当前Python版本和wheel包上标识的Python版本一致。当前为Python 3.8及Python 3.10。
操作步骤
执行以下命令,安装MacaRT Python版本wheel包:onnxruntime_gpu-1.12.0+mc*.whl。
pip install /opt/maca-ai/onnxruntime-maca/python/onnxruntime_gpu-1.12.0+mc*.whl
执行以下命令,快速验证是否已正确安装MacaRT。
python /opt/maca-ai/onnxruntime-maca/sample/python/maca_test.py -m /opt/maca-ai/onnxruntime-maca/sample/test_add
备注
MacaRT Python主要依赖numpy、protobuf等,在使用pip进行安装时会自动安装MacaRT Python的依赖包。
2.3. 使用MacaRT容器镜像
从发布的软件包中获取onnxruntime容器镜像并启动。onnxruntime容器镜像包含MacaRT及工具链。 容器镜像的使用,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
3. MacaRT C++ API
3.1. 部署ONNX模型
MacaRT支持使用C++ API将ONNX模型部署到曦云系列GPU上,并完成推理。
3.1.1. 创建Session
操作步骤
配置日志对象
Ort::Env。#include <onnxruntime_cxx_api.h> std::string ep_name = "MacaEP"; Ort::Env env(OrtLoggingLevel::ORT_LOGGING_LEVEL_INFO, ep_name.c_str());
在
SessionOption中添加MacaEP的信息。OrtMACAProviderOptions maca_options; maca_options.device_id=0; Ort::SessionOptions sessionOptions; sessionOptions.AppendExecutionProvider_MACA(maca_options);
备注
SessionOption用于在创建Session时,指定MacaRT所使用的EP信息。SessionOption的详细信息,可参考ONNX Runtime相关文档。
创建Session对象。
Ort::Session session(env, your_onnx_model_path, sessionOptions);
3.1.2. 获取模型图的输入输出信息
操作步骤
执行以下命令,获取模型图的输入输出信息。
Ort::AllocatorWithDefaultOptions allocator; std::vector<const char*> inputNames, outputNames; for ( size_t i=0; i< session.GetInputCount(); i++){ inputNames.push_back(session.GetInputName(i , allocator)); } for ( size_t i=0; i< session.GetOutputCount(); i++){ outputNames.push_back(session.GetOutputName(i , allocator)); }
3.1.3. 构建模型输入Tensors
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,并且输入数据处于可分页内存上。
void* input_data[inputNames.size()]; // input data ptr size_t input_data_len[inputNames.size()]; // input data len
创建
MemoryInfo,用于标识输入数据所在的设备信息。Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator,OrtMemType::OrtMemTypeDefault);
创建输入Tensors。假设模型的输入形状是固定的。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i],input_data_len[i],inputDims.data(),inputDims.size(),inputType)); }
3.1.4. 获取模型输出Tensors
操作步骤
执行以下命令,通过同步执行的方式,获取模型的输出Tensors。在不指定设备信息的情况下,输出Tensors中的数据默认位于可分页内存上。
auto ouput = session.Run(Ort::RunOptions{nullptr},inputNames.data(), inputTensors.data(),inputNames.size(), ouputNames.data(), outputNames.size()); mcStreamSynchronize(stream);
3.2. 绑定输入输出设备
有多个模型且模型间存在数据拷贝时,绑定输入输出内存信息,可帮助减少模型之间不必要的输入输出数据拷贝。MacaRT支持将模型的输入或输出绑定到:
两种Host端的内存页面:可分页内存(Pageable Memory)和固页内存(Pinned Memory)
一种Device端的内存信息:曦云系列GPU显存(Video Memory)
推荐使用固页内存存储模型输入输出数据,可以提高数据传输效率。
3.2.1. 绑定输入输出数据到可分页内存上
3.2.2. 绑定输入输出数据到固页内存上
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,并且输入数据处于固页内存上。
void* input_data[inputNames.size()]; // input data ptr size_t input_data_len[inputNames.size()]; // input data len
创建
MemoryInfo,用于标识输入数据所在的设备信息。constexpr const char* MACA_PINNED_STR= "MacaPinned"; Ort:MemoryInfo memoryInfo = Ort::MemoryInfo(MACA_PINNED_STR, OrtAllocatorType::OrtDeviceAllocator,0, OrtMemType::OrtMemTypeCPUOutput);
创建输入Tensors。假设模型的输入形状是固定的。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i],input_data_len[i],inputDims.data(),inputDims.size(),inputType)); }
执行以下命令,使用IOBinding来获取模型输出。
Ort::IoBinding ioBinding(session); for(size_t i=0; i< inputNames.size(), i++){ ioBinding.BindInput(inputNames[i],inputTensors[i]); } for(size_t i=0; i< outputNames.size(), i++){ ioBinding.BindOutput(outputNames[i],memoryInfo); } session.Run(Ort::RunOptions{nullptr},ioBinding); auto outputs=ioBinding.GetOutputValues();
3.2.3. 绑定输入输出数据到显存上
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,并且输入数据处于曦云系列GPU显存上。
void* input_batch_data[inputNames.size()]; // input data ptr size_t input_batch_data_len[inputNames.size()]; // input data len
创建MemoryInfo,用于标识输入数据所在的内存信息。
constexpr const char* MACA_STR= "Maca"; Ort:MemoryInfo memoryInfo = Ort::MemoryInfo(MACA_STR, OrtAllocatorType::OrtDeviceAllocator, gpu_id, OrtMemType::OrtMemTypeDefault);
创建输入Tensors。假设模型的输入形状是固定的。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i], input_data_len[i], inputDims.data(), inputDims.size(),inputType)); }
执行以下命令,使用IOBinding来获取模型输出。
Ort::IoBinding ioBinding(session); for(size_t i=0; i< inputNames.size(), i++){ ioBinding.BindInput(inputNames[i],inputTensors[i]); } for(size_t i=0; i< outputNames.size(), i++){ ioBinding.BindOutput(outputNames[i],memoryInfo); } session.Run(Ort::RunOptions{nullptr},ioBinding); auto outputs=ioBinding.GetOutputValues();
3.3. 动态Batch推理
MacaRT支持ONNX Runtime的动态Batch推理功能,在指定推理后端为MacaEP时,使用 BatchSize 值为-1的模型。
推理原理
推理原理如图 3.1 所示,其中input_i_j代表第i组Batch数据,模型的第j个输入,M为模型结构需要的输入个数,N为输入的Batch数目,K为模型结构的输出个数。 input_i包含了input_0_i到input_N_i的所有输入数据。
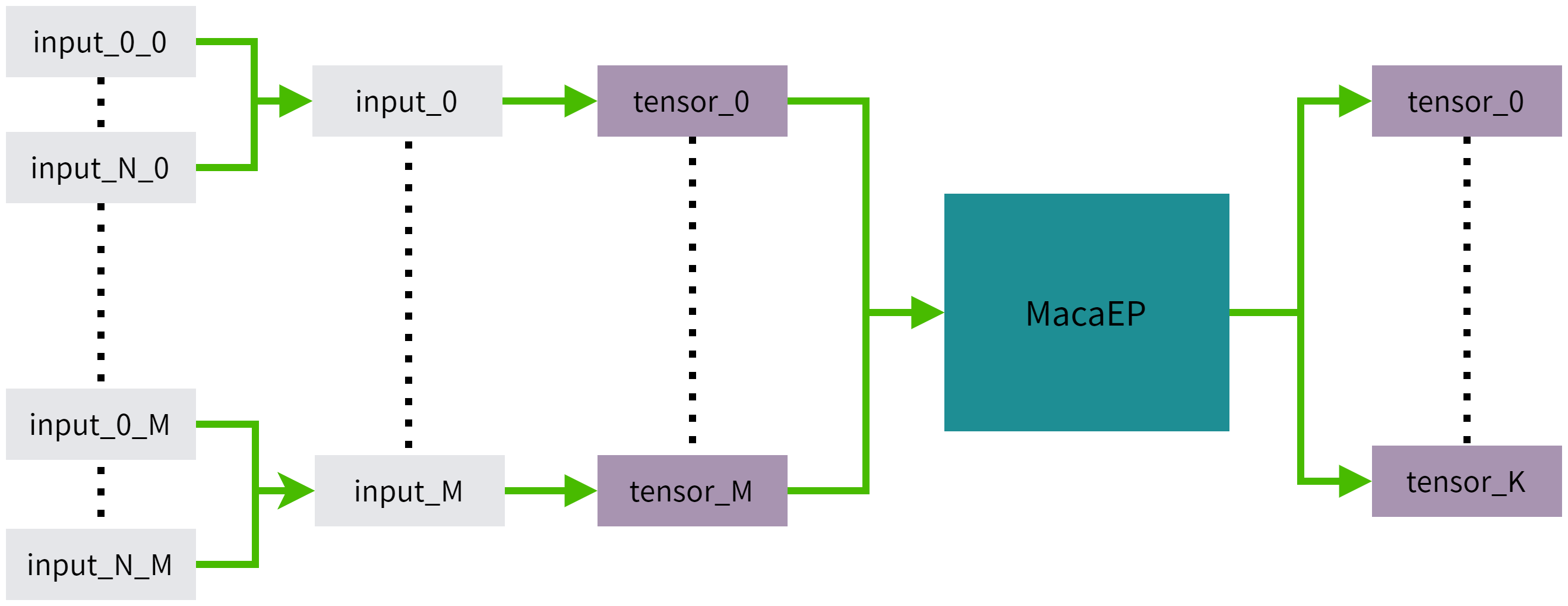
图 3.1 动态Batch推理原理图
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,input_data包含了Batch为N的输入数据,且输入数据位于可分页内存上。
void* input_data[inputNames.size()]; size_t input_data_len[inputNames.size()];
创建MemoryInfo,用于标识输入数据所在的设备信息。
Ort::MemoryInfo memoryInfo =Ort::MemoryInfo::CreateCpu( OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
创建输入Tensors。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputDims[0]=N; inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i], input_data_len[i], inputDims.data(), inputDims.size(),inputType)); }
支持使用以下两种方式获取模型输出。
// session run auto ouput = session.Run(Ort::RunOptions{nullptr},inputNames.data(), inputTensors.data(),inputNames.size(), ouputNames.data(),outputNames.size());
或
// iobinding Ort::IoBinding ioBinding(session); for(size_t i=0; i< inputNames.size(), i++){ ioBinding.BindInput(inputNames[i],inputTensors[i]); } for(size_t i=0; i< outputNames.size(), i++){ ioBinding.BindOutput(outputNames[i],memoryInfo); } session.Run(Ort::RunOptions{nullptr},ioBinding); auto outputs = ioBinding.GetOutputValues();
3.4. 提升曦云系列GPU推理性能
使用MacaRT将ONNX模型部署到曦云系列GPU上时,MacaEP配置信息 OrtMACAProviderOptions 会直接影响MacaRT的推理速度。
OrtMACAProviderOptions 支持的配置选项参见表 3.1。
选项 |
说明 |
|---|---|
device_id |
配置所使用的设备号 |
gpu_mem_limit |
MacaRT使用的最大显存量 |
arena_extend_strategy |
显存增长策略 |
default_memory_arena_cfg |
内存管理配置 |
3.4.1. 设备ID
当有多个 GPU 时,需通过配置 gpu_id 来管理。通过在 OrtMACAProviderOptions 中配置 device_id,可以指定所使用的 gpu_id,默认为0。
OrtMACAProviderOptions maca_options;
maca_options.device_id = your_gpu_id;
3.4.2. MacaRT显存管理
MacaRT提供BFCarena显存管理策略,可以有效地使用显存,避免显存重复申请和显存碎片。有关BFCarena的更多信息,可参考ONNX Runtime相关文档。
有以下两种方法可以配置MacaEP显存管理策略:
直接使用
OrtMACAProviderOptions配置。OrtMACAProviderOptions maca_options; maca_options.gpu_mem_limit=SIZE_MAX; maca_options.arena_extend_strategy=0;
创建一个
OrtArenaCfg对象。auto cfg = Ort::ArenaCfg(SIZE_MAX,0,-1,-1); OrtMACAProviderOptions maca_options; maca_options.default_memory_arena_cfg=cfg.release();
3.5. 自定义算子
MacaRT支持用户定义非官方的ONNX算子进行推理。
操作步骤
使用C++的API构建自定义算子库。
通过使用C++ API或Python API将自定义算子库注册到
SessionOptions对应的MacaEP。加载包含自定义算子的模型进行推理。
上述步骤的具体实现细节,可以参考ONNX Runtime官方文档中关于Cuda EP自定义算子的实现步骤,MacaEP保持基本一致。 也在 /opt/maca-ai/onnxruntime-maca/custom_op_test中提供了完整的实现样例。
以下介绍MacaEP自定义算子的不同之处。
3.5.1. Domain的定义
将自定义算子注册到MacaEP的后端时, Domain 必须设置为 custom.op,即:
static const char* c_OpDomain="custom.op";
3.5.2. Kernel输入输出的数据排布
在构建自定义算子库时,在MacaRT中新增接口用于指定Kernel需要的输入输出数据排布。
OrtDataLayout GetInputDataLayout(size_t index); //指定输入的数据排布
OrtDataLayout GetOutputDataLayout(size_t index); //指定输出的数据排布
当前MacaEP的自定义算子支持以下三种数据排布:
typedef enum OrtDataLayout{
NCHW,
NHWC8,
NHWC16,
}OrtDataLayout;
需要注意的是:
在默认情况下,所有自定义算子Kernel的输入输出都是NCHW格式。
模型的输入数据排布必须是NCHW格式,MacaEP会根据Kernel需求自动进行数据排布的转换。
模型的输出会被MacaEP自动转换为NCHW格式的排布。
4. MacaRT Python API
4.1. 部署ONNX模型
MacaRT支持使用Python API将ONNX模型部署到曦云系列GPU上,并完成推理。
4.1.1. 创建Session
操作步骤
执行以下命令,创建Session。
import onnxruntime as ort provider_options=[{'device_id':0}] session = ort.InferenceSession(your_onnx_model_path, providers=["MACAExecutionProvider"],provider_options=provider_options)
4.1.2. 获取模型图的输入输出信息
操作步骤
执行以下命令,获取模型图的输入输出信息。
input_nodes = session.get_inputs() input_names = [i_n.name for i_n in input_nodes] output_nodes = session.get_outputs() output_names = [o_n.name for o_n in output_nodes]
4.1.3. 构建模型输入字典
操作步骤
准备输入数据。假设已创建一个包含所有模型输入数据的List,List中的元素为模型的每个输入的
numpy数据,且输入List的变量名为input_data_list。构建输入字典。
input_dict ={} for i_d, i_n in zip(input_data_list, input_names): input_dict[i_n] = i_d
4.1.4. 获取模型输出
操作步骤
执行以下命令,获取模型输出。
output_data = session.run([], input_dict )
4.2. 绑定输入输出设备
有多个模型且模型间存在数据拷贝时,绑定输入输出内存信息,可帮助减少模型之间不必要的输入输出数据拷贝。
MacaRT Python API也支持将模型的输入或输出绑定到可分页内存、固页内存和显存上。
4.2.1. 绑定输入输出数据到可分页内存上
操作步骤
操作步骤同 4.1.2 获取模型图的输入输出信息。
执行以下命令,使用IOBinding获取模型输出。
io_binding = session.io_binding() for key in input_dict.keys(): io_binding.bind_ortvalue_input(key,ort.OrtValue.ortvalue_from_numpy(input_dict[key], "cpu",0)) for o_n in output_names: io_binding.bind_output(o_n,"cpu") session.run_with_iobinding(io_binding) output = io_binding.get_outputs()
4.2.2. 绑定输入输出数据到固页内存上
操作步骤
操作步骤同 4.1.2 获取模型图的输入输出信息。
执行以下命令,使用IOBinding获取模型输出。
io_binding = session.io_binding() for key in input_dict.keys(): io_binding.bind_ortvalue_input(key,ort.OrtValue.ortvalue_from_numpy(input_dict[key], "maca_pinned",gpu_id)) for o_n in ouput_names: io_binding.bind_output(o_n,"maca_pinned") session.run_with_iobinding(io_binding) output = io_binding.get_outputs()
4.2.3. 绑定输入输出数据到显存上
操作步骤
操作步骤同 4.1.2 获取模型图的输入输出信息。
执行以下命令,使用IOBinding获取模型输出。
io_binding = session.io_binding() for key in input_dict.keys(): io_binding.bind_ortvalue_input(key,ort.OrtValue.ortvalue_from_numpy(input_dict[key], "maca",gpu_id)) for o_n in output_names: io_binding.bind_output(o_n,"maca",device_id = gpu_id) session.run_with_iobinding(io_binding) output = io_binding.get_outputs()
4.3. 动态Batch推理
操作步骤
准备输入数据。如下所示,其中
input_*代表由模型图的其中一个输入,且每一个输入数据的BatchSize都为N。input_data = [input_0,input_1,...,input_N]
操作步骤同 4.1.2 获取模型图的输入输出信息。
使用IOBinding获取输出。
io_binding = session.io_binding() for i_n,b_d in zip(input_names,input_data): io_binding.bind_ortvalue_input(i_n,ort.OrtValue.ortvalue_from_numpy(b_d, "cpu",0)) for o_n in ouput_names: io_binding.bind_output(o_n,"cpu") session.run_with_iobinding(io_binding) output = io_binding.get_outputs()
4.4. 提升曦云系列GPU推理性能
使用MacaRT将ONNX模型部署到曦云系列GPU上时,MacaEP的配置信息 provider_options 会直接影响MacaRT的推理速度。
相关配置信息的介绍,参见 3.4 提升曦云系列GPU推理性能。
4.4.1. 设备ID设置
操作步骤
执行以下命令,配置
device_id来指定gpu_id,以管理多个GPU。provider_options=[{'device_id': your_gpu_id }]
5. MacaRT工具链
MacaRT提供以下工具:
模型转换工具MacaConverter。针对各种深度学习框架(如PyTorch,Caffe,Tensorflow)训练出来的模型,可以使用MacaConverter将训练的模型转换为ONNX模型。
精度分析工具MacaPrecision。通过比较CPU和曦云系列GPU在各个层的输出值,更好地调试模型。
模型量化工具MacaQuantizer。相对于MacaRT提供的模型量化功能,MacaQuantizer可以在模型量化后达到更高的精度和更快的速度。
MacaRT模型部署工具链如下图所示:
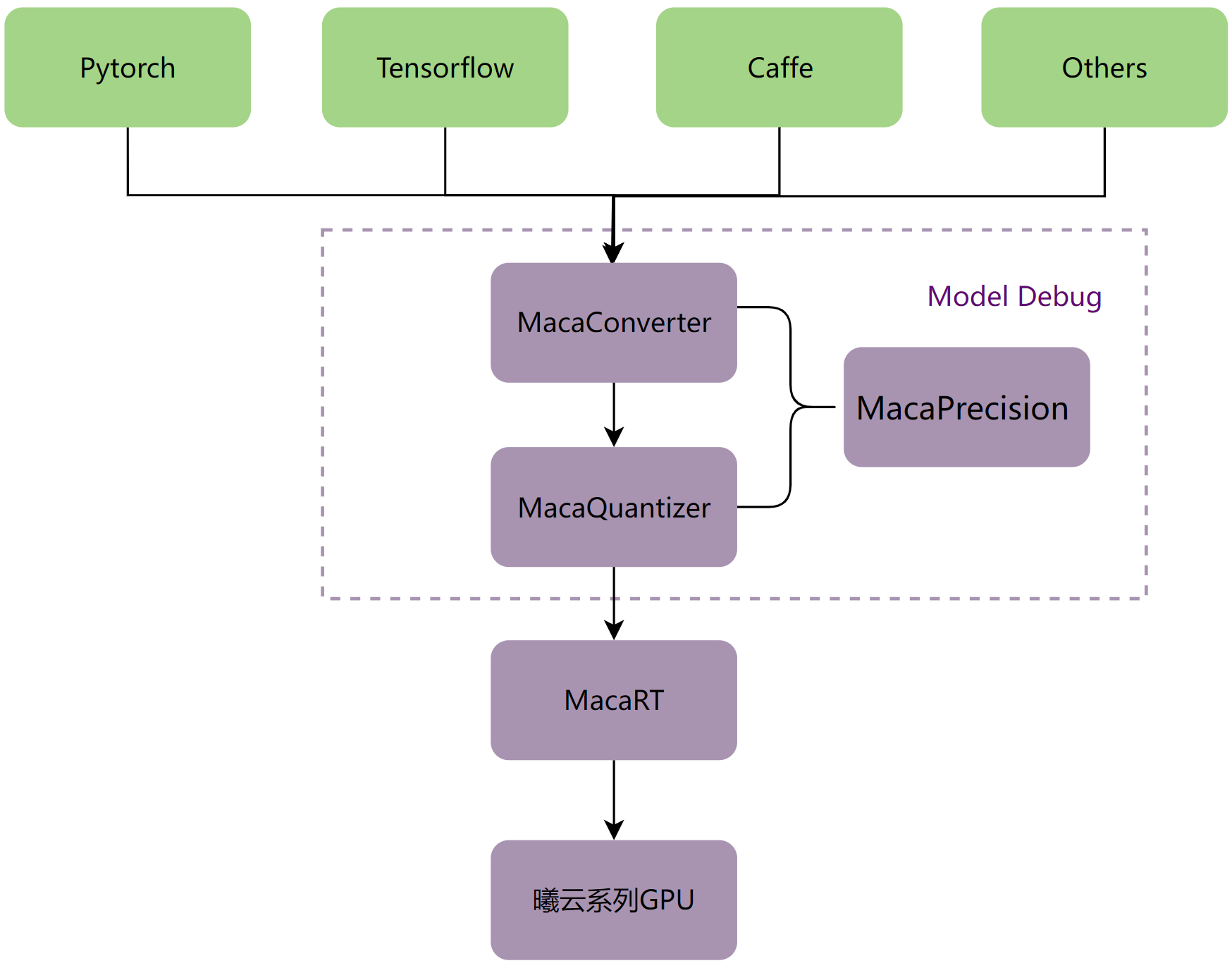
图 5.1 MacaRT模型部署工具链
5.1. MacaConverter
ONNX是一种便于在各个主流深度学习框架中迁移模型的中间表达格式,可用于存储训练好的模型。它使得不同的深度学习框架(如PyTorch,Caffe,TensorFlow)可以采⽤相同格式存储模型数据,从而进行推理任务的执行。
为了将不同深度学习框架的模型转换为ONNX格式的模型,MacaConverter的内部封装了常用的开源转换工具,对外提供统一的转换接口(命令行),同时提供了部分算子优化功能。
5.1.1. 安装
MacaConverter以wheel安装包的形式对外发布,建议在Conda环境中安装(建议Python版本3.10)。安装MacaRT后,可以在/opt/maca-ai/onnxruntime-maca/python/tools目录下找到MacaConverter对应的Python安装包。
操作步骤
执行以下命令,安装MacaConverter。
conda create -n maca_test python=3.10 source activate maca_test pip install onnxruntime_gpu-1.12.0+mc*.whl pip install maca_converter-*.whl
备注
若运行时报以下错误:
ImportError: libpython3.10.so.1.0: cannot open shared object file: No such file or directory
可执行以下命令:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/xxx/anaconda3/envs/maca_test/lib/
wheel包安装过程中会自动下载相关依赖库,主要有:
numpy
onnx
onnxruntime-gpu
TensorFlow==2.4.0
torch
torchvision
onnxoptimizer==0.2.6
rich==12.0.0
packaging
pyyaml
paddlepaddle
paddle2onnx
5.1.2. 功能列表
MacaConverter支持将多种类型的模型转换为ONNX模型,参见表 5.1。
源模型框架 |
目标模型框架 |
说明 |
|---|---|---|
Caffe |
ONNX |
支持将Caffe模型转换为ONNX模型 |
TensorFlow |
ONNX |
支持将TensorFlow模型转换为ONNX模型(包括CheckPoint,SavedModel,pb和H5四种格式) |
PyTorch |
ONNX |
支持将PyTorch模型转换为ONNX模型 |
PaddlePaddle |
ONNX |
支持将PaddlePaddle模型转换为ONNX模型 |
Darknet |
ONNX |
支持将Darknet模型转换为ONNX模型(目前只支持yolov3和yolov4) |
MacaConverter还支持其他功能,参见表 5.2。
功能 |
说明 |
|---|---|
动态batch转换 |
支持将BatchSize非动态的模型修改为动态BatchSize |
ONNX优化 |
支持常规的优化操作(如常量折叠、Conv+BN融合) |
Float32转Float16 |
支持将模型中相关算子的输入类型由Float32改为Float16 |
子图提取 |
按照给定的输入/输出提取模型的子图 |
融合Pad+Pool |
将相邻的Pad算子融合进Pool算子中 |
op_set版本转换 |
支持将原ONNX模型的op_set版本转换为目标版本 |
Float32转Uint8 |
支持将模型的输入类型由Float32改为Uint8(仅针对模型的input数据,非所有算子) |
5.1.3. 使用说明
5.1.3.1. Caffe模型转ONNX模型
操作步骤
执行以下命令,将Caffe模型转为ONNX模型。
python -m maca_converter --model_path ./caffe_model --model_type caffe --output ./output.onnx
参数说明:
model_path:Caffe模型路径(文件夹,需包含.prototxt和.caffemodel)model_type:模型类型(此处固定为caffe)output:目标模型的路径
5.1.3.2. TensorFlow(H5)模型转ONNX模型
操作步骤
执行以下命令,将TensorFlow H5格式的模型转为ONNX模型。
python -m maca_converter --model_path ./test.h5 --model_type tf-h5 --output ./output.onnx
参数说明:
model_path:H5模型路径model_type:模型类型(此处固定为tf-h5)output:目标模型的路径
5.1.3.3. TensorFlow(SavedModel)模型转ONNX模型
操作步骤
执行以下命令,将TensorFlow SavedModel格式的模型转为ONNX模型。
python -m maca_converter --model_path ./tfsm --model_type tf-sm --output ./output.onnx
参数说明:
model_path:SavedModel模型路径(文件夹,需包含assets/saved_model.pb/variables)model_type:模型类型(此处固定为tf-sm)output:目标模型的路径
5.1.3.4. TensorFlow(CheckPoint)模型转ONNX模型
操作步骤
执行以下命令,将TensorFlow CheckPoint格式的模型转为ONNX模型。
python -m maca_converter --model_path ./ckpt/test.meta --model_type tf-ckpt --output ./output.onnx --inputs x:0,y:0 --outputs op_to_store:0 –-inputs_as_nchw x:0,y:0
参数说明:
model_path:CheckPoint模型路径(文件夹,需包含checkpoint、.meta、.index、.data文件,此参数需指向.meta文件的路径)model_type:模型类型(此处固定为tf-ckpt)output:目标模型的路径inputs:TensorFlow模型的输入(tensor变量的名称,一般后面需加:0)outputs:TensorFlow模型的输出(tensor变量的名称,一般后面需加:0)inputs_as_nchw:可选项,如果原始输入维度是nhwc,可使用此选项转变为nchw
5.1.3.5. TensorFlow(pb)模型转ONNX模型
操作步骤
执行以下命令,将TensorFlow pb格式的模型转为ONNX模型。
python -m maca_converter --model_path ./test.pb --model_type tf-graph --output ./output.onnx --inputs x:0,y:0 --outputs op_to_store:0 --inputs_as_nchw x:0,y:0
参数说明:
model_path:pb模型路径model_type:模型类型(此处固定为tf-graph)output:目标模型的路径inputs:TensorFlow模型的输入(tensor变量的名称,一般后面需加:0)outputs:TensorFlow模型的输出(tensor变量的名称,一般后面需加:0)inputs_as_nchw:可选项,如果原始输入维度是nhwc,可使用此选项转变为nchw
5.1.3.6. PyTorch模型转ONNX模型(输入包含模型定义和权重)
操作步骤
执行以下命令,将PyTorch模型转为ONNX模型(输入包含模型定义和权重)。
python -m maca_converter --model_path ./mnist_model.pkl --model_type pytorch --output ./torch.onnx --model_def_file ./CNN.py --model_class_name CNN --input_shape [1,1,28,28]
参数说明:
model_path:PyTorch模型路径(模型中包含了权重和定义)model_type:模型类型(此处固定为pytorch)output:目标模型的路径model_def_file:模型定义文件(必须和执行命令的路径在同一目录下)model_class_name:模型中定义的类名input_shape:模型的输入形状
5.1.3.7. PyTorch模型转ONNX模型(输入仅包含权重)
操作步骤
执行以下命令,将PyTorch模型转为ONNX模型(输入仅包含权重)。
python -m maca_converter --model_path ./xxx --model_type pytorch --output ./unet.onnx --model_def_file ./unet.py --model_class_name Net --model_weights_file ./9_epoch_0.56322173.pth --input_shape [64,3,32,32]
参数说明:
model_path:PyTorch模型路径(此处可任意指定,因为这种场景下只有权重文件,没有模型)model_type:模型类型(此处固定为pytorch)output:目标模型的路径model_def_file:模型定义文件(必须和执行命令的路径在同一目录下)model_class_name:模型中定义的类别名称model_weights_file:模型权重文件的路径input_shape:模型的输入形状
5.1.3.8. PyTorch模型转ONNX模型(输入仅包含权重,且模型定义在Torchvision中)
操作步骤
执行以下命令,将PyTorch模型转为ONNX模型(输入仅包含权重,且模型定义在Torchvision中)。
python -m maca_converter --model_path ./xxx --model_type pytorch --output ./output.onnx --model_class_name torchvision.models.resnet50 --model_weights_file ./0.9696.pth --input_shape [16,3,256,256]
参数说明:
model_path:PyTorch模型路径(此处可任意指定,因为这种场景下只有权重文件,没有模型)model_type:模型类型(此处固定为pytorch)output:目标模型的路径model_class_name:模型中定义的类别名称input_shape:模型的输入形状
5.1.3.9. Darknet模型转ONNX模型
操作步骤
执行以下命令,将Darket模型转为ONNX模型。
python -m maca_converter --model_path ./my_model --model_type darknet --output ./output.onnx
参数说明:
model_path:Darknet模型路径(文件夹,需包含.cfg和.weights文件)model_type:模型类型(此处固定为darknet)output:目标模型的路径
5.1.3.10. PaddlePaddle模型转ONNX模型(输入包含权重和定义)
操作步骤
执行以下命令,将PaddlePaddle模型转为ONNX模型(输入包含权重和定义)。
python -m maca_converter --model_path ./paddle_model --model_type paddle --output ./output.onnx
参数说明:
model_path:PaddlePaddle模型路径(文件夹,需包含.pdmodel,.pdiparams.info和.pdiparams文件)model_type:模型类型(此处固定为paddle)output:目标模型的路径
5.1.3.11. PaddlePaddle模型转ONNX模型(输入仅包含权重)
操作步骤
执行以下命令,将PaddlePaddle模型转为ONNX模型(输入仅包含权重)。
python -m maca_converter --model_path ./xxx --model_type paddle --output ./paddle.onnx --model_def_file ./mnist.py --model_class_name LeNet --model_weights_file ./paddle_checkpoint/final.pdparams --input_shape [1,1,28,28]
参数说明:
model_path:PaddlePaddle模型路径(可任意指定,因为此场景下只有权重文件,没有模型)model_type:模型类型(此处固定为paddle)output:目标模型的路径model_def_file:模型定义文件(必须和执行命令的路径在同一目录下)model_class_name:模型中定义的类别名称model_weights_file:模型权重文件的路径input_shape:模型的输入形状
5.1.3.12. PaddlePaddle模型转ONNX模型(输入仅包含权重,模型在paddle.vision中定义)
操作步骤
执行以下命令,将PaddlePaddle模型转为ONNX模型(输入仅包含权重,模型在paddle.vision中定义)。
python -m maca_converter --model_path ./xxx --model_type paddle --output ./paddle.onnx --model_class_name paddle.vision.models.LeNet --model_weights_file ./final.pdparams --input_shape [1,1,28,28]
参数说明:
model_path:PaddlePaddle模型路径(此处可任意指定,因为这种场景下只有权重文件,没有模型)model_type:模型类型(此处固定为paddle)output:目标模型的路径model_class_name:模型中定义的类别名称model_weights_file:模型权重文件的路径input_shape:模型的输入形状
5.1.3.13. 动态Batch转换
操作步骤
执行以下命令,将BatchSize非动态的模型转换为动态模型。
python -m maca_converter --model_path ./caffe_model --model_type caffe --output ./output.onnx --dynamic_batch 1
5.1.3.14. ONNX简化
操作步骤
执行以下命令,对输入的模型进行常规优化(如常量折叠,Conv+BN融合等)。
python -m maca_converter --model_path ./test.onnx --model_type onnx --output ./output.onnx
备注
该功能默认打开。如需关闭,可加参数
–simplify 0。
5.1.3.15. FP32转FP16
操作步骤
执行以下命令,将模型中相关算子的输入类型由Float32改为Float16。
python -m maca_converter --model_path ./test.onnx --model_type onnx --output ./output.onnx --fp32_to_fp16 1
5.1.3.16. 子图提取
操作步骤
执行以下命令,按照给定的input/output,提取子图,保存模型。
python -m maca_converter --model_path ./test.onnx --model_type onnx --output ./output.onnx --extract_sub 1 --inputs input_1 --outputs functional_1/concatenate/concat
5.1.3.17. op_set版本转换
操作步骤
执行以下命令,转换ONNX模型的op_set版本。
python -m maca_converter --model_path ./test.onnx --model_type onnx --output ./output.onnx --op_set 13
5.1.3.18. Pad融合
操作步骤
执行以下命令,将模型中相邻的Pad+Pool组合,融合进Pool算子里。
python -m maca_converter --model_path ./test.onnx --model_type onnx --output ./output.onnx --fuse_pad_pool 1
5.1.3.19. Float32转Uint8(仅针对模型的input数据,非所有算子)
操作步骤
执行以下命令,将模型的输入类型由Float32改为Uint8。
python -m maca_converter --model_path ./test.onnx --model_type onnx --output ./output.onnx --fp32_to_u8 1
5.2. MacaPrecision
GPU开发过程中,针对ONNX模型中每一个算子,需要验证其在GPU硬件上的计算结果是否正确,以保证相关算子软硬件实现的可靠性。MacaPrecision是用于保证整个流程完备性的精度对比工具。
MacaPrecision主要实现以下三个方面的功能:
逐层比较AI模型在GPU与CPU上的运行输出结果。
支持全量比较与指定节点比较两种方式。
单层计算结果的精度对比,支持SNR/Cosine/MSE三种方式。
5.2.1. 安装
MacaPrecision以wheel安装包的形式对外发布,建议在Conda环境中安装(建议Python版本为3.10)。 安装MacaRT后,可以在/opt/maca-ai/onnxruntime-maca/python/tools目录下找到MacaPrecision对应的Python安装包。
操作步骤
执行以下命令,安装MacaPrecision。
conda create -n maca_test python=3.10 source activate maca_test pip install onnxruntime_gpu-1.12.0+mc*.whl pip install maca_precision-*.whl
wheel包安装过程中会自动下载相关依赖库,主要有:
onnx
onnxruntime-gpu
numpy
5.2.2. 使用说明
MacaPrecision以CPU计算结果为基准,对比每一层的输出结果,误差超过一定范围,认为计算精度有误。具体流程如下:
加载ONNX模型。
解析ONNX模型,分析input变量,生成随机输入数据。
在CPU上运行模型,保存输出结果(output_cpu)。
在GPU上运行模型,保存输出结果(output_gpu)。
逐层比较output_cpu与output_gpu,如某一层的差值超过预设的阈值,则认为GPU计算精度存在问题,需要排查。
由于常规模型与量化模型在内部处理方式上存在差异,所以执行操作时需要区分常规模型与量化模型。
5.2.2.1. 常规模型(FP32/FP16)
全量模式
执行以下命令,在全量模式下进行常规模型推理。
python -m maca_precision -i ./test.onnx -c snr -t common -b 6
参数
-i指定需要测试的模型路径;参数
-c指定用于逐层对比的计算方法,支持snr/mse/cosine三种方式(可不指定,默认snr);参数
-t指定模型类型,此处固定为common;参数
-b指定每次比较的中间节点的个数,可不指定,默认为5(此处需要分批比较的原因是中间结果的参数量可能会比较大,如果直接全部比较会占用大量显存,如指定-1,则一次进行全量比较)。
全量模式下,会首先进行最后一层的比较,如果结果一致,则认为模型推理无异常,不会进行中间节点的比较。
指定模式
执行以下命令,在指定模式下进行常规模型推理。
python -m maca_precision -i ./test.onnx -c snr -t common -m Conv_0,Relu_1
参数 -m 指定需要比较的中间节点的名称,多个名称以逗号分隔。
指定模式下,无论最终的结果是否一致,都会进行指定的中间节点的比较。
5.2.2.2. 量化模型(经过MacaQuantizer量化后的模型)
量化模型的操作与常规模型基本一致,也分为全量模式和指定模式。指定模式下的节点,只能为量化节点。
唯一不同的是, -t 参数需要指定为 quantize。
例如:
python -m maca_precision –i ./test.onnx –t quantize -b 3
或
python -m maca_precision –i ./test.onnx –t quantize –m PPQ_Operation_152,PPQ_Operation_160
5.3. MacaQuantizer
MacaQuantizer是一个高效的神经网络量化工具,通过自定义的量化算子库、网络执行器、神经网络调度器、量化计算图等设计,即便在网络极度复杂的情况下,依然能够得到正确的网络量化结果。 量化过程中会通过读取配置参数文件,自动搜索最优的量化方案,同时量化中严格控制硬件模拟误差,保证硬件推理时的精度。
目前MacaQuantizer使用ONNX(opset 11~13)模型文件作为输入,覆盖常用的80余种ONNX算子类型。如果是PyTorch,TensorFlow等其他模型,可使用MacaConverter将模型转换为ONNX模型。
5.3.1. 安装
操作步骤
安装Python(建议版本为3.10)。
安装MacaRT后,可以在/opt/maca-ai/onnxruntime-maca/python/tools目录下找到MacaQuantizer对应的Python安装包。
执行以下命令,安装MacaQuantizer。
pip install maca_quantizer-xxxx-py3-none-any.whl
5.3.2. 使用说明
为了提高量化速度,MacaQuantizer 量化工具可以使用曦云系列GPU进行量化加速。使用曦云系列GPU可以加速量化过程中的重训练过程,提高量化速度。
默认采用曦云系列GPU进行加速计算。如果没有曦云系列GPU环境,可以使用CPU版本进行量化工具,通过设置以下环境变量来进行GPU版和CPU版切换。 环境变量设置为 0 时表示使用CPU版本进行加速计算,为 1 时表示使用曦云系列GPU进行加速计算。
export MACA_QUANTIZER_USING_MXGPU=0
运行MacaQuantizer之前,需要配置一个yaml格式的参数文件。格式如下所示:
import_model: /path/to/mode.onnx
export_model: /path/to/export_model.onnx
export_type: onnx
export_batch: 1
quant_algorithm: percentile
output_threshold: 0.1
without_bs: False
force_advance_quant: False
collecting_device: gpu
dataset:
calib_dir: /path/to/dataset/calibrate/
calib_num: 200
batch_size: 8
preprocessing:
enable: True
attributes:
isreverse: False
mean: [123.76, 116,28, 103,53]
std: [58.4, 57.12, 57.37]
resize:
keep_ratio: False
to: [3, 256, 256]
centercrop: [224, 224]
其中每个参数的说明,参见表 5.3。
参数 |
值 |
默认值 |
说明 |
|---|---|---|---|
import_model |
输入模型路径,目前只支持ONNX模型 |
||
export_model |
输出模型路径,目前只支持ONNX模型 |
||
export_type |
[onnx, native] |
onnx |
导出模型的类型 onnx:导出onnx qdq格式 native:导出qdq格式外,额外导出二进制的模型 |
quant_algorithm |
[percentile, minmax,mse, kl] |
percentile |
量化算法选择 |
export_batch |
[True, False] |
1 |
导出模型的BatchSize,默认为1 |
output_threshold |
0-1 |
0.1 |
量化后SNR误差最大允许范围 |
without_bs |
[True, False] |
False |
模型输入是否带有BatchSize维度 |
force_advance_quant |
[True, False] |
False |
是否量化过程中开启强制优化 |
calib_dir |
校准数据集的目录或dataset.txt路径。如果模型为多输入,仅支持dataset.txt文本格式,且数据为npy或二进制数据 |
||
calib_num |
[50-500] |
校准数据集的数量 |
|
batch_size |
量化计算时的BatchSize |
||
enable |
[True, False] |
是否对数据做预处理 False:校准数据需要是npy或二进制数据 |
|
isreverse |
[True, False] |
是否将图像通道RGB转为BGR |
|
mean |
预处理均值 |
||
std |
预处理方差。 |
||
keep_ratio |
[True, False] |
Resize是否保持等比例。 |
|
to |
Resize大小[chw]。 |
||
pad_value |
0 |
Resize边缘填充的值。 |
|
centercrop |
[True, False] |
False |
centercrop大小[h, w]。 如不需要centercrop,可删除该参数。 |
操作步骤
执行以下命令,运行模型量化。
python -m maca_quantizer -c quantize.yaml
参数说明:
-c/--config:yaml参数文件
5.3.2.1. 预处理说明
预处理流程如图 5.2 所示。

图 5.2 预处理流程
如果提供的预处理方案与模型的预处理方式不一致或无法满足要求时,可将预处理后的数据离线保存为npy或二进制格式,关闭数据读取时的预处理,直接读取预处理后的数据。
yaml示例如下所示:
import_model: /path/to/mode.onnx
export_model: /path/to/export_model.onnx
export_type: onnx
quant_algorithm: percentile
export_batch: 1
without_bs: False
force_advance_quant: False
dataset:
calib_dir: /path/to/dataset/calibrate/
calib_num: 200
batch_size: 8
preprocessing:
enable: False
5.3.2.2. dataset.txt文本格式说明
若输入 calib_dir 为dataset.txt文本格式,请参考如下格式。
单输入模型:只读取每行第一列参数(空格分割);
val/ILSVRC2012_val_00000001.JPEG 66 val/ILSVRC2012_val_00000002.JPEG 971 val/ILSVRC2012_val_00000003.JPEG 231 val/ILSVRC2012_val_00000004.JPEG 810 val/ILSVRC2012_val_00000005.JPEG 517 val/ILSVRC2012_val_00000006.JPEG 58 val/ILSVRC2012_val_00000007.JPEG 335 val/ILSVRC2012_val_00000008.JPEG 416 val/ILSVRC2012_val_00000009.JPEG 675
多输入模型:每一行为一个数据样本,输入空格分割。
1000000000_input_ids.npy 1000000000_input_mask.npy 1000000000_segment_ids.npy 1000000001_input_ids.npy 1000000001_input_mask.npy 1000000001_segment_ids.npy 1000000002_input_ids.npy 1000000002_input_mask.npy 1000000002_segment_ids.npy 1000000003_input_ids.npy 1000000003_input_mask.npy 1000000003_segment_ids.npy 1000000004_input_ids.npy 1000000004_input_mask.npy 1000000004_segment_ids.npy 1000000005_input_ids.npy 1000000005_input_mask.npy 1000000005_segment_ids.npy
5.3.3. 注意事项
目前只支持ONNX模型的量化,如果不是,建议量化前使用MacaConverter对模型进行转换。
目前只支持ONNX(opset 11~13)模型文件作为输入,如果不是,建议量化前使用MacaConverter对模型转换。
目前MacaQuantizer支持的算子参见表 5.4 :
Gemm |
ReduceMean |
Sqrt |
grid_sampler |
ReduceSum |
Log |
GlobalAveragePool |
Relu |
Floor |
GlobalMaxPool |
Reshape |
RoiAlign |
Greater |
Resize |
MMCVRoiAlign |
LeakyRelu |
ScatterElements |
SpaceToDepth |
Less |
ScatterND |
DepthToSpace |
MatMul |
Shape |
Tanh |
Max |
Sigmoid |
Pow |
MaxPool |
Slice |
InstanceNormalization |
Min |
Softmax |
HardSigmoid |
Mul |
Softplus |
HardSwish |
NonMaxSuppression |
Split |
Neg |
NonZero |
Squeeze |
GRU |
Not |
Sub |
Swish |
Pad |
Tile |
Identity |
PRelu |
TopK |
OneHot |
Range |
Transpose |
Reciprocal |
ReduceL2 |
Unsqueeze |
Mish |
ReduceMax |
Where |
Elu |
Sum |
Erf |
6. MacaRT-LLM
6.1. MacaRT-LLM介绍
MacaRT-LLM是在曦云系列GPU上进行大模型部署和执行的推理引擎,是在MXMACA后端适配了OpenPPL-LLM。使用MacaRT-LLM在曦云系列GPU上进行大模型推理,其方法和功能与OpenPPL-LLM完全兼容。
OpenPPL-LLM进行大模型推理的整体流程,如图 6.1 所示,可以分为以下部分:
LLM模型转换,使用MacaPMX将LLM原始模型转换成OpenPPL-LLM支持的ONNX模型。
在PPL.NN.LLM上对模型图进行处理,包括图优化、图拆分、图编译等。
适配PPL.LLM Serving,支持LLM云端服务。
PPL.LLM Kernel Library通过MXMACA Driver在曦云系列GPU上执行模型。
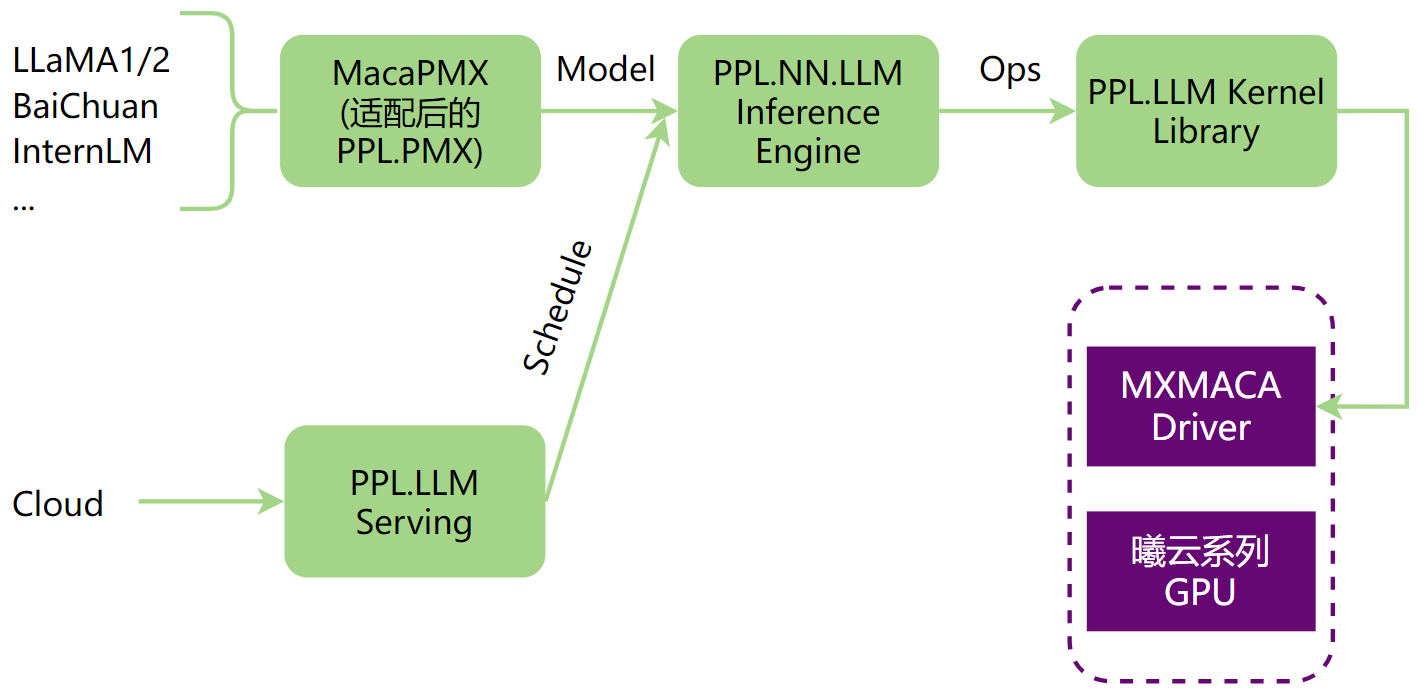
图 6.1 OpenPPL-LLM大模型推理流程图
6.2. MacaRT-LLM功能
MacaRT-LLM完全适配了OpenPPL-LLM,包含了以下功能和特性:
完全适配PPL.PMX,提供MacaPMX支持多种主流大模型进行模型转换。
完全适配PPL.NN.LLM,支持多个主流大模型的推理和模型切分多卡并行推理。
完全适配PPL.LLM.Serving,支持大模型服务化部署。
6.3. MacaRT-LLM使用流程
本章节介绍MacaRT-LLM的使用步骤,主要分为模型转换、本地模型部署验证及服务化部署三个部分。
6.3.1. 模型转换
使用MacaPMX进行模型转换,MacaPMX与PPL.PMX完全适配,为每个OP提供了一组标准的操作符规范文档和相应的函数Python API,使用户可以轻松地在Python中使用PMX自定义的OP构建需要的模型。
目前,MacaPMX主要负责LLM模型结构的表达。 除了PPL.PMX提供的开箱即用的LLM model zoo,用户还可使用MacaPMX提供的模型转换工具(从不同社区的模型到PMX模型)、Tensor并行分割工具和PMX模型合并工具。
6.3.1.1. 安装
MacaPMX以wheel安装包的形式对外发布,建议在Conda环境中安装(建议Python版本3.8)。
操作步骤
下载解压相应发行版的ppl.llm.serving发布包(例如:mxc500-ppl.llm.serving-2.17.3-1-ubuntu18.04-x86_64.tar.xz)后,在解压路径/wheel下找到MacaPMX对应的Python安装包。
执行以下命令,安装MacaPMX。
conda create -n maca_test python=3.8 source activate maca_test pip install macaPMX-*-py3-none-any.whl
wheel包的依赖库主要有:
onnx
torch
fire
sentencepiece
safetensors
其中,torch应为安装相应的曦云系列GPU软件发布包后得到的版本,其余依赖库会在安装MacaPMX时自动安装。
6.3.1.2. 转换为PMX模型
操作步骤(以llama-7b为例)
解压ppl.llm.serving发布包后,在解压路径/ai_deb中可以看到适配后的ppl.llm.serving安装包(ppl.llm.serving_*.deb),执行以下命令进行安装。
sudo dpkg -i ppl.llm.serving_*.deb
安装完成后,在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型转换示例脚本ConvertWeightToPmx.py。
根据需要,修改第4行导入相应模型的转换函数。当前支持的模型及对应导入代码参见表 6.1。
表 6.1 MacaPMX支持的大模型及对应转换函数 LLM Model
ConvertWeightToPmx.py导入代码
Llama全系/其它类Llama大模型
from macaPMX.model_zoo.llama.huggingface import write_pmx_model
chatglm2_6B/chatglm3_6B
from macaPMX.model_zoo.chatglm2.huggingface import write_pmx_model
internlm_7B
from macaPMX.model_zoo.internlm.huggingface import write_pmx_model
BaiChuan2_7B
from macaPMX.model_zoo.baichuan.huggingface import write_pmx_model
Mixtral8x7B
from macaPMX.model_zoo.mixtral.huggingface import write_pmx_model
QWen系列模型
from macaPMX.model_zoo.qwen.huggingface import write_pmx_model
备注
Llama系列对应的PMX转换函数,支持的参数与其它模型不同,支持转换
safetensors格式的原始权重,若使用use_safetensors参数,需要取消示例代码中16-21行及26行的注释。 该参数仅在Llama系列模型上生效,其余模型不能设置该参数,否则程序会执行失败。执行以下命令,将LLM原始权重转换为PMX模型。
python ConvertWeightToPmx.py --input_dir <hf_model_dir> --output_dir <pmx_model_dir> --use_safetensors True
参数说明:
input_dir:LLM原始权重模型路径(文件夹)output_dir:输出PMX模型目标路径(文件夹)use_safetensors:原始权重文件格式是否为safetensors,仅Llama系列支持该参数
6.3.1.3. 模型切分
当模型需要在多卡环境上进行并行推理时,需要将生成的PMX模型进行切分,以适应多卡并行推理。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型切分示例脚本Split.py。
根据需要,修改第2行导入相应模型的切分函数。当前支持的模型及对应导入代码参见表 6.2。
表 6.2 MacaPMX支持的大模型及对应PMX切分函数 LLM Model
Split.py导入代码
Llama/Qwen/其它类Llama大模型
import macaPMX.model_zoo.llama.modeling.SplitModel as SplitModel
Mixtral8x7B
import macaPMX.model_zoo.mixtral.modeling.SplitModel as SplitModel
执行以下命令,进行模型拆分。
python Split.py --input_dir <input_directory_path> --num_shards <number_of_shards> --output_dir <output_directory_path>
参数说明:
input_dir:待切分PMX模型路径(文件夹)num_shards:PMX模型切分份数output_dir:切分后PMX模型目标路径(文件夹)
6.3.1.4. 模型合并(可选)
该操作与模型切分相反,将多个切分后的PMX模型合并成一个。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型合并示例脚本Merge.py。
根据需要,修改第2行导入相应模型的合并函数。当前支持的模型及对应导入代码参见表 6.3。
表 6.3 MacaPMX支持的大模型及对应PMX合并函数 LLM Model
Merge.py导入代码
Llama/Qwen/其它类Llama大模型
import macaPMX.model_zoo.llama.modeling.MergeModel as MergeModel
Mixtral8x7B
import macaPMX.model_zoo.mixtral.modeling.MergeModel as MergeModel
执行以下命令,对切分后PMX模型进行合并。
python merge.py --input_dir <input_directory_path> --num_shards <number_of_shards> --output_dir <output_directory_path>
参数说明:
input_dir:待合并PMX模型路径(文件夹)num_shards:PMX子模型的份数output_dir:合并后PMX模型目标路径(文件夹)
6.3.1.5. PMX模型测试
当生成PMX模型后,使用torch加载PMX模型并执行LLM推理,根据输出结果验证PMX模型转换的正确性。 同时,若设置相应dump参数,可以将模型对应step的输入、输出保存下来,作为后续本地部署精度验证的输入及输出参考值。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型测试示例脚本Demo.py。
根据需要,修改第2行导入相应模型的PMX运行函数。当前支持的模型及对应导入代码参见表 6.4。
表 6.4 MacaPMX支持的大模型及对应PMX模型运行函数 LLM Model
Demo.py导入代码
Llama全系/其它类Llama大模型
from macaPMX.model_zoo.llama.huggingface import run_demo
chatglm2_6B/chatglm3_6B
from macaPMX.model_zoo.chatglm2.huggingface import run_demo
internlm_7B
from macaPMX.model_zoo.internlm.huggingface import run_demo
BaiChuan2_7B
from macaPMX.model_zoo.baichuan.huggingface import run_7B
Mixtral8x7B
from macaPMX.model_zoo.mixtral.huggingface import run_demo
QWen系列模型
from macaPMX.model_zoo.qwen.huggingface import run_demo
备注
BaiChuan2_7B对应的PMX运行函数与其余模型不同,需要同步修改第5行中的函数名。
执行以下命令,验证PMX模型精度。
OMP_NUM_THREADS=1 torchrun --nproc_per_node $num_gpu Demo.py --ckpt_dir <llama_dir> --tokenizer_path <llama_tokenizer_dir>/tokenizer.model --fused_qkv 1 --fused_kvcache 1 --auto_causal 1 --quantized_cache 1 --dynamic_batching 1 --seqlen_scale_up 1 --max_gen_len 256 --dump_steps 0,1,255 --dump_tensor_path <dump_dir> --batch 1 --cache_layout 3
参数说明:
num_gpu:模型推理需要的GPU数量ckpt_dir:PMX模型路径tokenizer_path:tokenizer模型路径当需要保存测试数据时,设置以下参数:
seqlen_scale_up:输入字节大小的比例因子(序列长度按8放大)max_gen_len:指定生成的最大输出长度(以字节为单位)dump_steps:保存测试数据的step,可以指定多个step,以“,”分隔。若只保存单个step,必须用“,”结尾,否则会执行失败。dump_tensor_path:保存测试数据的路径batch:指定数据处理的批大小cache_layout:cacheAttention中cache存储layout,当前仅支持0和3。0:layout为[MaxT, L, 2, H, Dh];3:layout为[L, 2, H, MaxT, Dh]。建议设置为3,性能更佳。其余参数与命令中保持一致即可。
备注
cache_layout的设置需要与 6.3.1.6 导出为ONNX模型 中的设置一致,否则 6.3.2 本地模型部署精度验证 会失败。
6.3.1.6. 导出为ONNX模型
在验证PMX模型精度无误后,可以执行最终步骤:将PMX导出至ONNX模型。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取ONNX模型导出示例脚本Export.py。
根据需要,修改第2行导入相应模型的ONNX导出函数。当前支持的模型及对应导入代码参见表 6.5。
表 6.5 MacaPMX支持的大模型及对应ONNX导出函数 LLM Model
Export.py导入代码
Llama全系/其它类Llama 大模型
from macaPMX.model_zoo.llama.huggingface import run_export
chatglm2_6B/chatglm3_6B
from macaPMX.model_zoo.chatglm2.huggingface import run_export
internlm_7B
from macaPMX.model_zoo.internlm.huggingface import run_export
BaiChuan2_7B
from macaPMX.model_zoo.baichuan.huggingface import export_7B
Mixtral8x7B
from macaPMX.model_zoo.mixtral.huggingface import run_export
QWen系列模型
from macaPMX.model_zoo.qwen.huggingface import run_export
备注
BaiChuan2_7B对应的ONNX导出函数与其余模型不同,需要同步修改第5行中的函数名。
执行以下命令,将PMX模型导出为ONNX模型。
OMP_NUM_THREADS=1 torchrun --nproc_per_node $num_gpu Export.py --ckpt_dir <llama_dir> --tokenizer_path <llama_tokenizer_dir>/tokenizer.model --fused_qkv 1 --fused_kvcache 1 --auto_causal 1 --quantized_cache 1 --dynamic_batching 1 --export_path <export_dir> --cache_layout 3
参数说明:
num_gpu:模型推理需要的GPU数量ckpt_dir:PMX模型路径tokenizer_path:tokenizer模型路径;chatglm系列模型不支持此参数,无需设置。export_path:导出ONNX模型目标路径cache_layout:cacheAttention中cache存储layout,当前仅支持0和3。0:layout为[MaxT, L, 2, H, Dh];3:layout为[L, 2, H, MaxT, Dh]。建议设置为3,性能更佳。其余参数与命令中保持一致即可。
6.3.2. 本地模型部署精度验证
大多数情况下,大模型会依托服务端部署提供服务端接口供客户端调用,但在服务化部署前,需要依托本地模型部署进行推理验证,以确认模型精度是否符合预期。 本章节介绍模型本地部署及精度验证的方法。
本地部署精度验证依赖工具如下:
pplnn_llm:本地部署可执行文件,安装ppl.llm.serving_*_amd64.deb后在/opt/maca-ai/ppl.llm.serving/bin/下获取。
操作步骤
创建一个测试bash脚本benchmark.sh,内容如下:
if [ -n "$MPI_LOCALRANKID" ]; then MPI_LOCALRANKID=$MPI_LOCALRANKID elif [ -n "$OMPI_COMM_WORLD_RANK" ]; then MPI_LOCALRANKID=$OMPI_COMM_WORLD_RANK elif [ -n "$PMI_RANK" ]; then MPI_LOCALRANKID=$PMI_RANK else echo "[WARNING] MPI_LOCALRANKID not found, set to 0" MPI_LOCALRANKID=0 fi DEVICE_ID=$MPI_LOCALRANKID STEP=$1 if [ ! -n "$STEP" ]; then STEP=0 fi MODEL_PATH="/path/to/exported/model/model_slice_${MPI_LOCALRANKID}/model.onnx" OUTPUT_DIR="/path/to/output_dir/rank_${MPI_LOCALRANKID}" # we should make the rank_* directories first TEST_DATA_DIR="/path/to/dumped/tensor/data/rank_${MPI_LOCALRANKID}" # we should rearrange the input tensors if the model exporting parameters has been changed. TOKEN_IDS=`ls ${TEST_DATA_DIR}/step${STEP}_token_ids-*` ATTN_MASK=`ls ${TEST_DATA_DIR}/step${STEP}_attn_mask-*` SEQSTARTS=`ls ${TEST_DATA_DIR}/step${STEP}_seqstarts-*` KVSTARTS=`ls ${TEST_DATA_DIR}/step${STEP}_kvstarts-*` CACHESTARTS=`ls ${TEST_DATA_DIR}/step${STEP}_cachestarts-*` DECODING_BATCHES=`ls ${TEST_DATA_DIR}/step${STEP}_decoding_batches-*` START_POS=`ls ${TEST_DATA_DIR}/step${STEP}_start_pos-*` AX_SEQLEN=`ls ${TEST_DATA_DIR}/step${STEP}_max_seqlen-*` MAX_KVLEN=`ls ${TEST_DATA_DIR}/step${STEP}_max_kvlen-*` KV_CAHCE=`ls ${TEST_DATA_DIR}/step${STEP}_kv_cache-*` KV_SCALE=`ls ${TEST_DATA_DIR}/step${STEP}_kv_scale-*` TEST_INPUTS="$TOKEN_IDS,$ATTN_MASK,$SEQSTARTS,$KVSTARTS,$CACHESTARTS,$DECODING_BATCHES,$START_POS,$MAX_SEQLEN,$MAX_KVLEN,$KV_CAHCE,$KV_SCALE" INPUT_DEVICES="device,device,device,device,device,host,device,host,host,device,device" CMD="/opt/maca-ai/ppl.llm.serving/bin/pplnn_llm --use-llm-cuda \ --onnx-model $MODEL_PATH \ --shaped-input-files $TEST_INPUTS \ --save-outputs \ --device-id $DEVICE_ID \ --save-data-dir $OUTPUT_DIR \ --in-devices $INPUT_DEVICES \ --enable-profiling \ --min-profiling-seconds 3 \ --warmup-iterations 10" echo "RUN RANK${MPI_LOCALRANKID} STEP${STEP} -> $CMD" eval "$CMD"
参数说明:
MODEL_PATH: 6.3.1.6 导出为ONNX模型 中导出的ONNX模型路径OUTPUT_DIR:模型输出文件保存路径TEST_DATA_DIR:模型输入文件保存路径,模型输入数据的操作步骤参见 6.3.1.5 PMX模型测试备注
需要将CMD中对应
pplnn_llm设置为安装后放置的路径或者自定义路径,这里默认设置为安装路径。设置环境变量并运行测试脚本生成输出数据。
export MACA_PATH=your_maca_path export PATH=${MACA_PATH}/bin:${PATH} export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${MACA_PATH}/ompi/lib:${LD_LIBRARY_PATH} export USE_GEMM_NN=true benchmark.sh <STEP> #单卡推理测试命令 mpirun -np 4 benchmark.sh <STEP> #四卡推理测试命令,-np参数设置与推理卡数一致
执行完上述命令后,会在设置的OUTPUT_DIR保存对应step的输出数据。后续可以根据需求与 6.3.1.5 PMX模型测试 中保存的输出参考数据进行比对。 输出数据格式为float32,使用np.fromfile(data_path, np.float32)即可加载。
6.3.3. 本地模型部署性能测试
为了探测特定大模型的极限性能,可以在本地进行性能测试,为后续服务端部署性能做一个参照,进而优化服务端部署参数设置,最大限度发挥出曦云系列GPU的硬件性能。
本地部署性能测试依赖工具如下:
benchmark_llama:性能测试可执行文件,安装ppl.llm.serving_*_amd64.deb后在/opt/maca-ai/ppl.llm.serving/bin/下获取。当前仅支持llama系列及类llama模型的测试。
操作步骤(以llama-7b为例)
创建一个测试bash脚本benchmark_7b.sh,内容如下:
#!/bin/bash MODEL_TYPE="llama" MODEL_DIR="/mnt/hpc/shengyunrui/model_card/llama_7b_ppl" MODEL_PARAM_PATH="/mnt/hpc/shengyunrui/model_card/llama_7b_ppl/params.json" TENSOR_PARALLEL_SIZE=1 TOP_P=0.0 TOP_K=1 TEMPERATURE=1.0 WARMUP_LOOPS=2 BENCHMARK_LOOPS=2 INPUT_FILE_BASE="tokens_input" INPUT_LEN=8 GENERATION_LEN=256 BATCH_SIZE_LIST=(1 2 4 8 16 32 64 128 256) for BATCH_SIZE in ${BATCH_SIZE_LIST[@]}; do INPUT_FILE=${INPUT_FILE_BASE}_${INPUT_LEN} your_path_of_benchmark_llama \ --model-type $MODEL_TYPE \ --model-dir $MODEL_DIR \ --model-param-path $MODEL_PARAM_PATH \ --tensor-parallel-size $TENSOR_PARALLEL_SIZE \ --top-p $TOP_P \ --top-k $TOP_K \ --temperature $TEMPERATURE \ --warmup-loops $WARMUP_LOOPS \ --generation-len $GENERATION_LEN \ --benchmark-loops $BENCHMARK_LOOPS \ --input-file $INPUT_FILE \ --batch-size $BATCH_SIZE done
参数说明:
MODEL_TYPE:LLM模型类型,当前仅支持LlamaMODEL_DIR: 6.3.1.6 导出为ONNX模型 中导出的ONNX模型路径MODEL_PARAM_PATH: 6.3.1.6 导出为ONNX模型 中导出ONNX模型的params.json文件路径TENSOR_PARALLEL_SIZE:Tensor并行大小,需要与 6.3.1.3 模型切分 中模型切分数量保持一致,即导出模型为2卡并行,此处设置为2;4卡并行则设置为4WARMUP_LOOPS:warmup执行次数,在正式测试前执行该次数的warmupBENCHMARK_LOOPS:性能测试执行次数INPUT_FILE_BASE:模型输入文件基础文件名,默认为tokens_input,测试输入的文件名称为${INPUT_FILE_BASE}_${INPUT_LEN},即通过基础文件名和输入长度拼接。 例如,输入长度为8的输入文件名称为tokens_input_8INPUT_LEN:模型输入token长度GENERATION_LEN:模型生成token长度BATCH_SIZE_LIST:性能测试batchsize列表,测试会遍历该列表中所有设置输入文件为文本文件,每一行代表一条输入token,各token之间用空格分隔,
以INPUT_LEN=8为例,该文件的构成如下。篇幅限制,这里只展示前8条输入token。 该文件的行数(lines_of_token)必须大于等于测试设置的最大batchsize,否则该batchsize设置无效,测试程序只能执行最大batchsize = lines_of_token的测试,详细可参考相关文件。1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338
设置环境变量并运行测试脚本生成输出数据。
export MACA_PATH=your_maca_path export PATH=${MACA_PATH}/bin:${PATH} export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH} export USE_GEMM_NN=true benchmark_7b.sh
执行完上述命令后,会输出对应设置下的性能测试数据,如下所示:
CSV format header:prefill(ms),decode(ms),avg(ms),tps(ms),mem(gib) CSV format output:40.16,14.2576,14.4599,69.1567,14.3461
分别对应prefill耗时、平均decode延迟、平均step延迟、tokens吞吐(tokens per second)以及显存使用。
备注
执行测试脚本前,需要激活测试环境变量,否则会测试失败。
6.3.4. 服务化部署
大模型服务化部署是一种将大模型应用于实际场景的有效方式。它具有以下优势:
提供更高的性能和更准确的结果。由于大模型具备更深层次的理解和更复杂的参数配置,其在各种任务上表现更出色。 通过将大模型部署为服务,可以利用其强大的计算能力和学习能力,为用户提供更高质量的预测、推荐和决策。
可以实现灵活的扩展性和定制化需求。采用服务化架构,可以将模型与其他组件解耦,使得系统更易于扩展和维护。 同时,根据不同业务需求,可以对大模型进行个性化的调整和优化,以满足特定任务的要求。
提升数据安全和隐私保护。通过将模型部署在云端或私有环境中,可以有效保护敏感数据的安全性,避免将数据传输到公共网络或设备中。 这种集中化的方式可以通过严格的权限控制和加密技术来保护用户数据的隐私。
总的来说,大模型服务化部署具有性能优越、灵活扩展和安全保护等诸多优势,可为各行各业提供更高水平的智能服务。
本节将从服务端部署、C++客户端部署、Python客户端部署三个部分介绍服务化部署。
6.3.4.1. 服务端部署
服务端部署依赖文件如下:
ppl_llm_server:服务端部署可执行文件,安装ppl.llm.serving_*_amd64.deb后在/opt/maca-ai/ppl.llm.serving/bin/下获取。
xxx_config.json:特定大模型配置文件,ppl_llm_server通过解析该配置文件加载并运行对应的模型。 安装 ppl.llm.serving_*_amd64.deb 后,在 /opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/model_config/ 路径下,可找到当前所有已支持模型的配置示例。
操作步骤(以llama-7b为例)
创建llama_7b_config.json,主要内容如下:
{ "model_type": "llama", "model_dir": "/path/to/model/dir", "model_param_path": "/path/to/model/dir/params.json", "tokenizer_path": "/path/to/tokenizer/tokenizer.model", "tensor_parallel_size": 1, "top_p": 0.0, "top_k": 1, "quant_method": "none", "max_tokens_scale": 0.6, "max_tokens_per_request": 4096, "max_running_batch": 1024, "max_tokens_per_step": 8192, "host": "0.0.0.0", "port": 23333 }
参数说明:
model_type:LLM模型类型,可参考 /opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/model_config 中已支持模型的配置示例进行配置model_dir: 6.3.1.6 导出为ONNX模型 中导出的ONNX模型路径model_param_path: 6.3.1.6 导出为ONNX模型 中导出ONNX模型的params.json文件路径tokenizer_path:tokenizer模型路径tensor_parallel_size:Tensor并行大小,需要与 6.3.1.3 模型切分 中模型切分数量保持一致,即导出模型为2卡并行,此处设置为2;4卡并行则设置为4max_tokens_scale:设置范围[0.1, 0.9],该参数会影响服务端对显存的使用。 简单地说,代表模型加载完成后,额外占用剩余显存的比例,受制于当前显存碎片化管理不够完善,随着请求次数增加,显存会出现溢出,建议设置一个较小的值。 若测试大batchsize,建议设置大一些(0.9),否则由于预分配显存不够,无法按照设定的batchsize执行大模型推理,但此时请求的次数要比较少,否则也会出现显存溢出max_tokens_per_request:单次请求的最大token数,建议设置4096max_running_batch:执行推理最大batchsizemax_tokens_per_step:单个step处理最大token数设置环境变量并运行服务端程序,启动llama_7b服务。
export MACA_PATH=your_maca_path export PATH=${MACA_PATH}/bin:${PATH} export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH} export USE_GEMM_NN=true export SHOW_PREFILL=true #若需要输出prefill性能统计数据,设置该环境变量 ./ppl_llm_server llama_7b_config.json
当输出下列日志时,表示llama_7b服务启动完成:
[INFO][2023-12-07 16:05:29.304][llama_worker.cc:962] waiting for request ...
6.3.4.2. C++客户端部署
安装ppl.llm.serving_*_amd64.deb后,可在/opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/cpp_client/路径下获取C++代码示例。 安装路径中有该代码示例已编译生成的可执行文件:/opt/maca-ai/ppl.llm.serving/bin/cpp_client。工程文件目录如图 6.2 所示:
cmake:文件夹,包含三方依赖库cmake配置。
CMakeLists.txt:CMake配置文件。
proto:文件夹,包含与服务端交互时grpc依赖的proto文件。
src:文件夹,包含client_sample.cc,是C++客户端的简单使用示例程序。
图 6.2 C++客户端目录结构图
参考client_sample.cc示例代码,根据业务需求定制相应的C++客户端即可。
编译时需要将cmake/deps.cmake中37-39行、41-43行中grpc、absl依赖库地址修改为:
hpcc_declare_git_dep(grpc
https://github.com/grpc/grpc.git
v1.56.2)
hpcc_declare_git_dep(absl
https://github.com/abseil/abseil-cpp.git
lts_2023_01_25)
6.3.4.3. Python客户端部署
安装ppl.llm.serving_*_amd64.deb后,可在/opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/python_client/路径下获取Python代码示例。 工程文件目录如图 6.3 所示:
llm_pb2.py:与服务端交互时grpc依赖的proto定义文件。
llm_pb2_grpc.py:与服务端交互时grpc依赖的proto定义文件。
client.py:Python客户端示例脚本。

图 6.3 Python客户端目录结构图
参考client.py示例代码,根据业务需求定制相应的Python客户端即可。
Python客户端依赖grpc,使用时需安装grpcio、grpcio-tools两个依赖项。
pip install grpcio
pip install grpcio-tools
6.3.4.4. 服务端输出性能数据解析
服务端完成部署,客户端成功发送请求,服务端完成请求的处理并将结果发送至客户端后,服务端会输出当前部署大模型的性能数据。示例如图 6.4 所示:
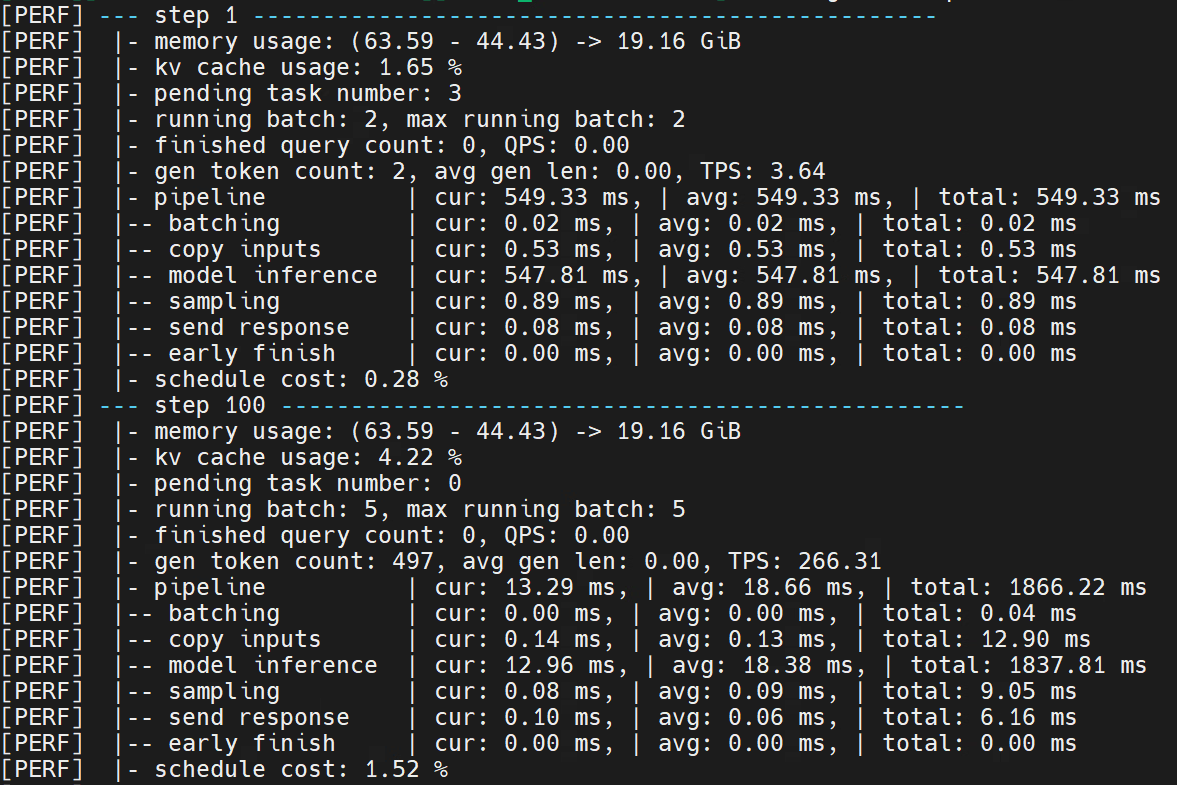
图 6.4 服务端输出性能数据示例(llama-7b)
若在启动服务前设置 SHOW_PREFILL 环境变量,服务端会输出prefill阶段的性能数据,即图 6.4 中step1的性能数据;若不设置,则输出100整数倍及最后一个step的性能数据。
重点性能参数包括:
memory usage :当前step显存使用情况
running batch :当前step正在推理的batchsize
max running batch :从当前step回溯的历史最大推理batchsize
finished query count :当前step已经结束生成的请求数量
pipeline :整体流程耗时,包含当前step耗时,平均耗时及总耗时
model inference :大模型推理的耗时,包含当前step耗时,平均耗时及总耗时
7. MacaRT-vLLM
7.1. MacaRT-vLLM介绍
MacaRT-vLLM是在曦云系列GPU上适配官方vLLM的推理工具,基于MXMACA后端对vLLM方法进行了兼容适配和Kernel优化。 使用MacaRT-vLLM在曦云系列GPU上进行大模型推理,其方法和功能与官方vLLM兼容。当前兼容版本为vLLM-0.8.2。
vLLM版本与PyTorch版本的兼容适配关系,参见表 7.1。
vLLM |
PyTorch |
|---|---|
0.6.2 |
2.1 |
0.6.6 |
2.1 |
0.7.2 |
2.4 |
0.8.2 |
2.4 |
7.2. MacaRT-vLLM功能与局限性
MacaRT-vLLM兼容适配了vLLM-0.8.2,包含了以下功能和特性,以及局限性:
功能和特性:
兼容vLLM-0.8.2支持的所有模型BFLOAT16推理和部分模型FLOAT16推理,支持官方多模态模型
兼容原生LLM、Engine、Kernel的API接口
兼容原生server和OpenAI server接口
支持Lora特性
支持GPTQ和AWQ量化方式
支持ray和mp方式启动单机多卡推理;设置
--distributed-executor-backend可以指定不同后端进行多卡推理,默认使用ray支持prefix_cache方式
支持
enforce_eager=False方式。需通过显式配置,默认为True。另外,需要额外设置MACA环境变量来获取加速效果:export MACA_GRAPH_LAUNCH_MODE=1
局限性:
不支持FP8类型KV Cache和相关FP8模型
包含Ubuntu 20、Ubuntu 22、kylin2309a系统版本,后续完善支持其他系统
7.3. MacaRT-vLLM使用流程
本章节介绍MacaRT-vLLM的使用步骤,主要分为离线推理、吞吐测试和Sever服务。
7.3.1. 环境准备
使用MacaRT-vLLM进行推理需要准备好环境。目前提供两种方式:镜像和wheel包。
7.3.1.1. 使用vLLM镜像
从发布的软件包中获取vLLM镜像并启动,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
7.3.1.2. 安装wheel包
操作步骤
预先安装沐曦平台的torch、flash attn、xformer(可选)环境。
获取MacaRT-vLLM压缩包mxc500-vllm-py310-xxx-${OS_Version}.tar.xz并解压。
pip安装以下wheel包:
vllm-0.8.2+xxx.whl
flash_attn+xxx.whl(适配vLLM新加速whl包)
ray-2.43.0-cp310-cp310_${OS_Version}.whl
除了上述wheel包,其他依赖环境可以通过外部镜像源进行安装。安装过程中有其他依赖,需要提前配置好Python的pip源。
7.3.1.3. 配置环境变量
export MACA_PATH=your_maca_path
export PATH=${MACA_PATH}/bin:${MACA_PATH}/mxgpu_llvm/bin:${PATH}
export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/ompi/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH}
7.3.2. 离线推理
离线推理代码示例如下:
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="facebook/opt-125m", tensor_parallel_size=1, dtype="float16", max_model_len=2048)
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
其中主要配置为:
LLM初始化类:指定模型路径(可配置为本地路径,如果不是本地路径,会根据网络下载外网模型)、tensor切分数量、模型数据类型(可不配置,如果没指定,将通过model config读取)、模型最大处理长度(可不配置,如果没设置,将从model config读取)
SamplingParams:设置采样算法方式。参数配置可参照官方vLLM-0.8.2版本进行配置。
7.3.3. 吞吐测试
吞吐测试代码可参考官方vLLm-0.8.2 benchmark_throughput.py。
吞吐测试代码的运行方式示例1:
python benchmark_throughput.py --model XXX --tensor-parallel-size 1 --num-prompts 8 --trust-remote-code --input-len 1024 --output-len 512
模型为XXX,tensor并行为1,8条请求数量,信任模型路径的tokenizer方式,每条输入长度为1024个token,输出为512个token。
吞吐测试代码的运行方式示例2:
python benchmark_throughput.py --model XXX --tensor-parallel-size 1 --num-prompts 8 --trust-remote-code --dataset XXX.json
模型为XXX,tensor并行为1,8条请求数量,信任模型路径的tokenizer方式,通过从dataset选取语料进行真实模拟。 json格式可参考ShareGPT_V3_unfiltered_cleaned_split.json。
运行程序后,结果打印如下:
Throughout: XXX request/s, XXXX token/s
打印结果指示每秒能接受多少请求,以及每秒处理的token数量(包括输入token)。
7.3.4. Server服务
Server请求服务参数设置可参考官方vLLM-0.8.2版本:
API server参数配置可参考api_server.py。
OpenAI server参数配置可参考api_server.py。
参考示例如下:
python -m vllm.entrypoints.api_server --model XXX #普通server方式
python -m vllm.entrypoints.openai.api_server --model XXX --host localhost --chat-template XXX.jinja ## openai 方式的请求
vllm server --model XXX
8. MacaRT-ModelZoo
8.1. MacaRT-ModelZoo介绍
MacaRT-ModelZoo方便用户在曦云系列GPU上快速部署验证深度学习模型,提供多种常见模型在曦云系列GPU上的部署方案,应用于图片分类、物体检测、语义分割、超分辨率、行为识别、关键点检测、字符识别、语音识别、推荐系统、多模态、自然语言处理、图生成等场景。具有如下特性:
丰富的应用场景,涵盖大部分主流网络模型,可使用现有或增加同类模型快速部署验证
易用的运行环境,提供的Docker镜像具有完备的MacaRT-ModelZoo模型部署软件栈
完整的数据链路,包含数据预处理、模型推理、后处理及结果指标评估等模块的实现
便捷的模型评估,通过命令参数可评估不同模型在多种精度下的模型精度和性能
统一的参数配置,从规范化的配置文件中获取模型部署量化、预处理与后处理等参数
8.2. 模型评测条件
MacaRT-ModelZoo上快速实现模型部署的依赖条件如下所示:
安装有曦云系列GPU板卡及完整运行时软件栈的主机
modelzoo.cnn.inference的Release Docker镜像软件包
ONNX格式的模型文件和带有标注信息的数据集
8.3. 代码目录结构及说明
MacaRT-ModelZoo的目录结构和说明如下(以classification类别中Resnet18模型评测展开):
├── _base(模型评测基类代码)
├── classification(图像分类类)
├── code(模型评测代码)
├── data(模型评测数据集,软链接到实际数据集目录)
├── models(模型配置集合)
├── ox_resnet18_224x224(模型配置目录)
├── config.yaml(模型评测配置参数)
└── performance.json(模型标准的精度和性能指标)
└── readme.md(模型评测说明,注意每个模型类别的此文件,可能有特殊说明)
├── action2(行为识别类)
├── Autoregressive(语音处理类)
├── CTR(推荐系统类)
├── detection(物体检测类)
├── face_recognition(人脸识别类)
├── landmark(关键点检测类)
├── multimodal(多模态类)
├── NLP_Transformer(自然语言处理类)
├── OCR(字符识别类)
├── segmentation(语义分割类)
├── stable_diffusion(图生成类)
└── video_enhancement(超分辨率类)
8.4. 源码、模型和数据集
8.4.1. 源码镜像获取
可通过沐曦软件中心获取MacaRT-ModelZoo源代码的镜像和模型。
操作步骤
进入软件中心,点击Docker的子页面。
选择曦云系列GPU的型号、发布版本号。
点击AI查看MACARTAI相关的Docker镜像。
软件包类型选择modelzoo.cnn.inference,架构类型选择amd64或arm64,操作系统类型选择CentOS或Ubuntu等。
通过上述操作选择MacaRT-ModelZoo源代码的镜像,点击docker命令复制,获取此Docker镜像的拉取命令,可通过此命令在沐曦软件中心服务器上拉取此镜像。
进入容器,可在/workspace/modelzoo/C500目录查看MacaRT-ModelZoo源代码,此容器除了包含MacaRT-ModelZoo源码,还包含完整的MacaRT-ModelZoo运行时软件栈,可大大减少用户在搭建运行环境所耗费的时间。容器镜像的使用,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
8.4.2. 模型获取
MacaRT-ModelZoo可评测的模型会陆续更新到沐曦软件中心,进入软件中心后点击Model的子页面,可根据模型类别和模型名称,点击下载得到模型。
用户也可以使用公开模型或私有模型进行评测,如果被测评的模型预处理、后处理和指标评估与这一类别中其他的不一致,则需要修改MacaRT-ModelZoo代码和配置文件对其支持。 此外,模型评测的成功与否还取决于MacaRT对模型的支持能力,遇到不支持的算子可以联系沐曦技术支持工程师在MacaRT上增加算子,也可以添加MacaRT自定义算子,操作步骤参见 3.5 自定义算子。
8.4.3. 数据集获取
MacaRT-ModelZoo中模型的量化和结果指标评估需要数据集,有以下三种获取方式:
联系沐曦技术支持工程师,获取数据集,无需修改直接使用
下载公开数据集,可能需要调整
自己制作数据集,可能需要调整
需要调整的原因是:可能存在数据集的数据存放目录结构和标注信息与MacaRT-ModelZoo中要求的数据集有所差异。
8.5. 模型评测步骤
8.5.1. 启动容器镜像
从发布的软件包中获取modelzoo.cnn.inference容器镜像并启动,此容器镜像包含MacaRT-ModelZoo模型评测所需的运行时软件栈。 容器镜像的使用,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。容器镜像启动时需要挂载用户的ONNX模型目录和数据集目录。
8.5.2. 建立数据集的关联
参见 8.4.3 数据集获取,准备好数据集后,切换到模型大类目录下建立软链接。例如,测试Resnet18可执行以下命令:
cd $MODELZOO_PATH/classification
ln -s $CLASSIFICATION_DATA_SET_PATH data
8.5.3. 执行模型评测
MacaRT-ModelZoo中评测模型性能或精度,需要先切换到模型大类目录,然后统一使用以下命令:
python ./code/OnnxRT_v2/start.py $modelpath $batchsize $precision $task $modelfile $ep $num_thr
通过参数可以配置测试任务为性能测试任务、精度测试任务或两者兼有,也可以配置测试精度为 int8、fp16 或 fp32,具体参数说明参见表 8.1:
参数名称 |
说明 |
|---|---|
modelpath |
模型配置目录,运行resnet18则是models/ox_resnet18_224x224 |
batchsize |
推理batchsize |
precision |
推理精度类型,目前支持 |
task |
测试任务, |
modelfile |
模型路径,若为./,会默认读取config配置的模型路径 |
ep |
推理运行的后端平台,默认为 |
num_thr |
测试的线程数,建议数值为1或者8的倍数 |
9. MacaRT-LMDeploy
9.1. MacaRT-LMDeploy介绍
MacaRT-LMDeploy是在曦云系列GPU上适配官方LMDeploy的推理工具,基于MXMACA后端对LMDeploy方法进行了兼容适配和Kernel优化。 使用MacaRT-LMDeploy在曦云系列GPU上进行大模型推理,其方法和功能与官方LMDeploy兼容。
9.2. MacaRT-LMDeploy功能与局限性
MacaRT-LMDeploy兼容适配了最新LMDeploy,除以下局限性以外,兼容其他所有LMDeploy原有功能,包括离线批处理、在线推理、控制台命令行交互等,可参考LMDeploy官方文档。
局限性:
支持PyTorch推理后端,不支持TurboMind引擎
支持FLOAT16和BFLOAT16推理,暂不支持量化模型部署
当前只对Qwen2.5,InternLM等部分模型进行了功能验证和性能优化
处于性能考虑,block_size只支持8、16、32,建议16
当前仅包含Ubuntu 20和Ubuntu 22系统版本,后续完善支持其他系统
9.3. MacaRT-LMDeploy使用流程
本章节介绍MacaRT-LMDeploy的使用步骤,主要分为离线推理、静态推理性能测试和Server服务动态推理性能测试。
9.3.1. 环境准备
使用MacaRT-LMDeploy进行推理需要以下准备:
获取vLLM镜像
安装dlinfer
安装lmdeploy
备注
完成上述步骤后,LMDeploy本身的依赖已经完整,但是在运行具体模型时,某些模型可能有它自己独有的依赖,请按照相关提示进行安装,提前配置好Python的pip源。
9.3.1.1. 获取vLLM镜像
从发布的软件包中获取vLLM镜像并启动,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
9.3.1.2. 安装dlinfer
dlinfer编译需要CUDA toolkit,建议使用CUDA 11.6。 可以在启动容器时通过
/usr/local:/usr/local -v挂载宿主机的 /usr/local/cuda路径到容器。设置MACA环境变量:
DEFAULT_DIR="/opt/maca" export MACA_PATH=${1:-$DEFAULT_DIR} export CUDA_PATH=/usr/local/cuda export CUCC_PATH=${MACA_PATH}/tools/cu-bridge export PATH=${CUDA_PATH}/bin:${MACA_PATH}/mxgpu_llvm/bin:${MACA_PATH}/bin:${CUCC_PATH}/tools:${CUCC_PATH}/bin:$PATH export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/ompi/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH}
源码安装:
git clone https://github.com/DeepLink-org/dlinfer.git cd dlinfer # 建议使用以下commit,已经过测试 git checkout dbb1feb71b0983d8b5b166771a7bb99e00461b36 rm -rf _skbuild pip3 install -r requirements/maca/full.txt DEVICE=maca python3 setup.py develop
9.3.1.3. 安装LMDeploy
源码安装:
git clone https://github.com/InternLM/lmdeploy.git
cd lmdeploy
# 建议使用以下commit,已经过测试
git checkout 832bfc45b4497e8d16e08ecfd663671e634aae40
LMDEPLOY_TARGET_DEVICE=maca python setup.py develop
9.3.2. 离线推理
离线推理代码示例如下:
import lmdeploy
from lmdeploy import PytorchEngineConfig
if __name__ == "__main__":
pipe = lmdeploy.pipeline("internlm/internlm2-chat-7b",
backend_config = PytorchEngineConfig(tp=1,
cache_max_entry_count=0.8, device_type="maca", block_size=16))
question = ["Shanghai is", "Please introduce China", "How are you?"]
response = pipe(question, request_output_len=256, do_preprocess=False)
for idx, r in enumerate(response):
print(f"Q: {question[idx]}")
print(f"A: {r.text}")
print()
API基本用法请参考官方文档。
9.3.3. 静态推理性能测试
因为profile_generation.py目前不支持传入 device_type,需要手动修改代码如下:
--- a/benchmark/profile_generation.py
+++ b/benchmark/profile_generation.py
@@ -430,6 +430,7 @@ def main():
eager_mode=args.eager_mode,
enable_prefix_caching=args.enable_prefix_caching,
dtype=args.dtype,
+ device_type='maca',
)
测试代码:
python profile_generation.py /models/llm/Internlm2-chat-7b --backend pytorch -c 1 -pt 256 -ct 128 --tp 1 --cache-block-seq-len 16 --dtype float16
python profile_generation.py:脚本在lmdeploy/benchmark。/models/llm/Internlm2-chat-7b:模型文件路径。--backend pytorch:指定使用的后端为PyTorch。-c 1:并发数为1。-pt 256:输入长度为256。-ct 128:输出长度为128。--tp 1:设置张量并行的大小为1。--cache-block-seq-len 16:设置block size为16。--dtype float16:指定数据类型为float16。
运行程序后,结果打印如下:
-------------------------------------
total time: 5.51s
concurrency: 1, test_round: 3
input_tokens: 256, output_tokens: 128
first_token latency(min, max, ave): 0.045s, 0.047s, 0.046s
total_token latency(min, max, ave): 1.833s, 1.846s, 1.839s
token_latency percentiles(50%,75%,95%,99%)(s):[0.014, 0.014, 0.02, 0.021]
throughput(output): 69.68 token/s
throughput(total): 209.04 token/s
--------------------------------------
打印结果指示首字延迟、输出吞吐和全部吞吐(包括首个token)。
9.3.4. Server服务动态推理性能测试
详细信息可参考官方文档请求吞吐量性能测试和api_server性能测试。
启动服务
启动服务代码示例:
lmdeploy serve api_server --server-port 23333 --tp 1 --backend pytorch --max-batch-size 256 /models/llm/Internlm2-chat-7b --dtype float16 --device maca --cache-block-seq-len 16
输出如下:
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Started server process[1384373]
HINT: Waiting for application startup.
HINT: Application startup complete.
HINT: Uvicorn running on http://0.0.0.0:23333 (Press CTRL+C to quit)
发起吞吐测试请求
profile_restful_api.py偶发NaN异常,为了暂时规避该问题,请手动修改代码如下:
--- a/benchmark/profile_restful_api.py +++ b/benchmark/profile_restful_api.py @@ -153,7 +153,7 @@ async def async_request_openai_completions( payload = { 'model': request_func_input.model, 'prompt': prompt, - 'temperature': 0.0, + 'temperature': 1.0, 'best_of': 1, 'max_tokens': request_func_input.output_len, 'stream': not args.disable_stream,
下载ShareGPT_V3_unfiltered_cleaned_split.json:
python profile_restful_api.py --port 23333 --backend lmdeploy --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json
输出如下:
Backend: lmdeploy
Traffic request rate: inf
Successful requests: 1000
Benchmark duration(s): 96.23
Total input tokens: 228316
Total generated tokens: 195534
Total generated tokens (retokimized): 181775
Request throughput (req/s): 10.39
Input token throughput (tok/s): 2372.62
Output token throughput (tok/s): 2031.95
End-to-End Latency
Mean E2E Latency (ms): 43531.86
Median E2E Latency (ms): 42845.51
Mean TTFT (ms): 26513.87
Median TTFT (ms): 24519.39
P99 TTFT (ms): 62724.06
Time per Output Token (excl. 1st token)
Mean TPOT (ms): 110.65
Median TPOT (ms): 95.38
P99 TPOT (ms): 535.69
Inter-token Latency
Mean ITL (ms): 91.67
Median ITL (ms): 61.98
P99 ITL (ms): 724.82
10. Diffusers
曦云系列GPU完全支持官方Diffusers推理工具,直接通过 pip install diffusers==0.31.0 安装即可,具体使用方法请参考官方使用文档。
11. Transformers
曦云系列GPU完全支持官方Transformers推理工具,直接通过 pip install transformers==4.46.3 安装即可,具体使用方法请参考官方使用文档。
12. MacaRT-SGLang
12.1. MacaRT-SGLang介绍
MacaRT-SGLang是在曦云系列GPU上适配官方SGLang的推理工具,基于MXMACA后端对SGLang方法进行了兼容适配和Kernel优化。 使用MacaRT-SGLang在曦云系列GPU上进行大模型推理,其方法和功能与官方SGLang兼容。当前兼容版本为SGLang 0.4.3,PyTorch 要求为2.4。
12.2. MacaRT-SGLang功能
支持的模型包括:DeepSeek-R1-BF16、DeepSeek-R1-W8A8和DeepSeek-R1-Distill-Qwen-1.5B。DeepSeek-R1-W8A8模型是采用 compress-tensor 的 W8A8-INT8 量化方式量化而来。
12.3. MacaRT-SGLang使用流程
本章节介绍MacaRT-SGLang的使用步骤,主要分为在线推理、吞吐测试和精度测试。
12.3.1. 环境准备
使用MacaRT-SGLang进行推理需要准备好环境。目前仅提供镜像方式。
12.3.1.1. 使用SGLang镜像
从发布的软件包中获取SGLang镜像并启动,参见《曦云® 系列通用计算GPU用户指南》中“容器相关场景支持”章节。
12.3.1.2. 设置环境变量
单机场景下,仅需在一台机器的容器内执行操作;多机场景时,需在所有容器中分别执行一次。
export MACA_SMALL_PAGESIZE_ENABLE=1
多机场景下,还需设置以下环境变量:
export GLOO_SOCKET_IFNAME=网口名
对于 GLOO_SOCKET_IFNAME 环境变量,需在宿主机上执行 ifconfig-a 指令获取与该宿主机IP地址对应的网口。
12.3.1.3. 启动Server
对于DeepSeek-R1-BF16全量模型,以4机32卡为例:
当前运行建议按照张量并行(tp)方式切分为32份。
python3 -m sglang.launch_server --model-path XXX --tp 32 --dist-init-addr 100.79.153.153:5000 --nnodes 4 --node-rank 0 --disable-cuda-graph
--tp 32表示tp并行的切分数量为32--model-path XXX指定模型存放路径--dist-init-addr 100.79.153.153:5000指定主节点的IP和端口号(可默认为5000),其他三个节点和主节点保持一致--nnodes 4表示节点数量--node-rank 0表示当前机器所属的节点索引0。需要注意的是必须先启动主节点,然后才能启动其他节点
对于DeepSeek-R1-W8A8量化模型,使用16卡即可运行。以2机16卡为例:
该模型需要根据沐曦发布的文档自行量化,可参考相关推理部署手册中“W8A8模型转换”章节。
当前运行建议按照tp方式切分为16份。
python3 -m sglang.launch_server --model-path XXX --tp 16 --dist-init-addr 100.79.153.153:5000 --nnodes 2 --node-rank 0 --disable-cuda-graph
对于DeepSeek-R1-Distil-Qwen-1.5B模型,使用单卡即可运行。以单卡为例:
python3 -m sglang.launch_server --model-path ${Model_path} --tp 1 --trust-remote-code --disable-cuda-graph
12.3.2. 在线推理
待端口顺利启动后,向 Sever 发送请求即可(另起终端)。以下示例简单验证推理服务。
import requests
url = "http://localhost:30000/generate"
data = {"text": "What is the capital of France?"}
response = requests.post(url, json=data)
print(response.json())
12.3.3. 吞吐测试
python3 -m sglang.bench_serving --backend sglang --dataset-name random m --random-input-len ${input-len} --random-output-len ${output-len} --random-range-ratio 1.0 --dataset-path ./dataset/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompt ${batch_size}
${input-len}表示输入长度${output-len}表示输出长度${batch_size}指定输入批次数量
12.3.4. 精度测试
12.3.4.1. MMLU精度测试
如果使用MMLU数据集进行精度测试,需要准备data数据。下载 data.tar 文件,解压并拷贝至 dataset 路径。
此外,如果机器无法访问外网,还需要下载 cl100k_base.tiktoken 文件,放入容器内任意位置。
安装依赖。
pip install blobfile export TIKTOKEN_CACHE_DIR=${path}${path}表示 cl100k_base.tiktoken 文件所在的路径,不需要包含文件名。执行 bench_sglang.py 进行精度测试,使用的测试命令行如下:
python code/bench_sglang.py --nsub 10 --data_dir ./dataset/data
--nsub指定测试问题的数量,最多为60。如不指定,默认是60。
12.3.4.2. C-Eval精度测试
安装依赖。
pip install eval-type-backport
执行 run_ceval_client.py 进行精度测试,使用的测试命令行如下:
python code/run_ceval_client.py --model ${Model_path} --test_jsonl ./dataset/ceval_val_cmcc.jsonl --batch_size 64-model ${Model_path}为model所在的路径。--test_jsonl ./dataset/ceval_val_cmcc.json1为C-Eval数据集的路径。
该脚本对接的 Server 端口号为 8000,所以需要在启动 SGLang Server 时加上 --port 8000,示例如下:
python -m sglang.launch_server --model ${Model_path} --tp 32 --dist-init-addr 100.79.153.153:5000 --nnodes 4 --node-rank 0 --trust-remote-code --isable-cuda-graph --port 8000
13. 附录
13.1. 术语/缩略语
术语/缩略语 |
全称 |
说明 |
|---|---|---|
Batch |
全部样本里的一批数据 |
|
BFC |
Best-Fit with Coalescing |
一种内存管理策略 |
CpuEP |
CPU Execution Provider |
以CPU作为ONNX Runtime的后端进行模型推理 |
LLM |
Large Language Model |
大语言模型 |
MacaConverter |
沐曦研发,将训练的模型转换为ONNX模型的工具 |
|
MacaEP |
MXMACA Execution Provider |
以曦云系列GPU作为ONNX Runtime的后端进行模型推理 |
MacaPrecision |
沐曦研发,精度对比工具 |
|
MacaQuantizer |
沐曦研发,模型量化工具 |
|
MacaRT |
MXMACA Runtime |
沐曦研发,曦云系列GPU的推理引擎 |
ModelZoo |
模型库 |
|
ONNX |
Open Neural Network Exchange |
开放神经网络交换,表示深度学习模型的开放格式,可将训练好的模型存储为此格式 |
ONNX Runtime |
一个开源的跨平台推理框架 |
|
OpenPPL-LLM |
OpenPPL推出的大语言模型(LLM)推理引擎 |
|
PMX |
PPL Model Exchage |
OpenPPL模型转换工具 |
Tensor |
张量,是一种特殊的数据结构 |