3. MacaRT C++ API
3.1. 部署ONNX模型
MacaRT支持使用C++ API将ONNX模型部署到曦云系列GPU上,并完成推理。
3.1.1. 创建Session
操作步骤
配置日志对象
Ort::Env。#include <onnxruntime_cxx_api.h> std::string ep_name = "MacaEP"; Ort::Env env(OrtLoggingLevel::ORT_LOGGING_LEVEL_INFO, ep_name.c_str());
在
SessionOption中添加MacaEP的信息。OrtMACAProviderOptions maca_options; maca_options.device_id=0; Ort::SessionOptions sessionOptions; sessionOptions.AppendExecutionProvider_MACA(maca_options);
备注
SessionOption用于在创建Session时,指定MacaRT所使用的EP信息。SessionOption的详细信息,可参考ONNX Runtime相关文档。
创建Session对象。
Ort::Session session(env, your_onnx_model_path, sessionOptions);
3.1.2. 获取模型图的输入输出信息
操作步骤
执行以下命令,获取模型图的输入输出信息。
Ort::AllocatorWithDefaultOptions allocator; std::vector<const char*> inputNames, outputNames; for ( size_t i=0; i< session.GetInputCount(); i++){ inputNames.push_back(session.GetInputName(i , allocator)); } for ( size_t i=0; i< session.GetOutputCount(); i++){ outputNames.push_back(session.GetOutputName(i , allocator)); }
3.1.3. 构建模型输入Tensors
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,并且输入数据处于可分页内存上。
void* input_data[inputNames.size()]; // input data ptr size_t input_data_len[inputNames.size()]; // input data len
创建
MemoryInfo,用于标识输入数据所在的设备信息。Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator,OrtMemType::OrtMemTypeDefault);
创建输入Tensors。假设模型的输入形状是固定的。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i],input_data_len[i],inputDims.data(),inputDims.size(),inputType)); }
3.1.4. 获取模型输出Tensors
操作步骤
执行以下命令,通过同步执行的方式,获取模型的输出Tensors。在不指定设备信息的情况下,输出Tensors中的数据默认位于可分页内存上。
auto ouput = session.Run(Ort::RunOptions{nullptr},inputNames.data(), inputTensors.data(),inputNames.size(), ouputNames.data(), outputNames.size()); mcStreamSynchronize(stream);
3.2. 绑定输入输出设备
有多个模型且模型间存在数据拷贝时,绑定输入输出内存信息,可帮助减少模型之间不必要的输入输出数据拷贝。MacaRT支持将模型的输入或输出绑定到:
两种Host端的内存页面:可分页内存(Pageable Memory)和固页内存(Pinned Memory)
一种Device端的内存信息:曦云系列GPU显存(Video Memory)
推荐使用固页内存存储模型输入输出数据,可以提高数据传输效率。
3.2.1. 绑定输入输出数据到可分页内存上
3.2.2. 绑定输入输出数据到固页内存上
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,并且输入数据处于固页内存上。
void* input_data[inputNames.size()]; // input data ptr size_t input_data_len[inputNames.size()]; // input data len
创建
MemoryInfo,用于标识输入数据所在的设备信息。constexpr const char* MACA_PINNED_STR= "MacaPinned"; Ort:MemoryInfo memoryInfo = Ort::MemoryInfo(MACA_PINNED_STR, OrtAllocatorType::OrtDeviceAllocator,0, OrtMemType::OrtMemTypeCPUOutput);
创建输入Tensors。假设模型的输入形状是固定的。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i],input_data_len[i],inputDims.data(),inputDims.size(),inputType)); }
执行以下命令,使用IOBinding来获取模型输出。
Ort::IoBinding ioBinding(session); for(size_t i=0; i< inputNames.size(), i++){ ioBinding.BindInput(inputNames[i],inputTensors[i]); } for(size_t i=0; i< outputNames.size(), i++){ ioBinding.BindOutput(outputNames[i],memoryInfo); } session.Run(Ort::RunOptions{nullptr},ioBinding); auto outputs=ioBinding.GetOutputValues();
3.2.3. 绑定输入输出数据到显存上
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,并且输入数据处于曦云系列GPU显存上。
void* input_batch_data[inputNames.size()]; // input data ptr size_t input_batch_data_len[inputNames.size()]; // input data len
创建MemoryInfo,用于标识输入数据所在的内存信息。
constexpr const char* MACA_STR= "Maca"; Ort:MemoryInfo memoryInfo = Ort::MemoryInfo(MACA_STR, OrtAllocatorType::OrtDeviceAllocator, gpu_id, OrtMemType::OrtMemTypeDefault);
创建输入Tensors。假设模型的输入形状是固定的。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i], input_data_len[i], inputDims.data(), inputDims.size(),inputType)); }
执行以下命令,使用IOBinding来获取模型输出。
Ort::IoBinding ioBinding(session); for(size_t i=0; i< inputNames.size(), i++){ ioBinding.BindInput(inputNames[i],inputTensors[i]); } for(size_t i=0; i< outputNames.size(), i++){ ioBinding.BindOutput(outputNames[i],memoryInfo); } session.Run(Ort::RunOptions{nullptr},ioBinding); auto outputs=ioBinding.GetOutputValues();
3.3. 动态Batch推理
MacaRT支持ONNX Runtime的动态Batch推理功能,在指定推理后端为MacaEP时,使用 BatchSize 值为-1的模型。
推理原理
推理原理如图 3.1 所示,其中input_i_j代表第i组Batch数据,模型的第j个输入,M为模型结构需要的输入个数,N为输入的Batch数目,K为模型结构的输出个数。 input_i包含了input_0_i到input_N_i的所有输入数据。
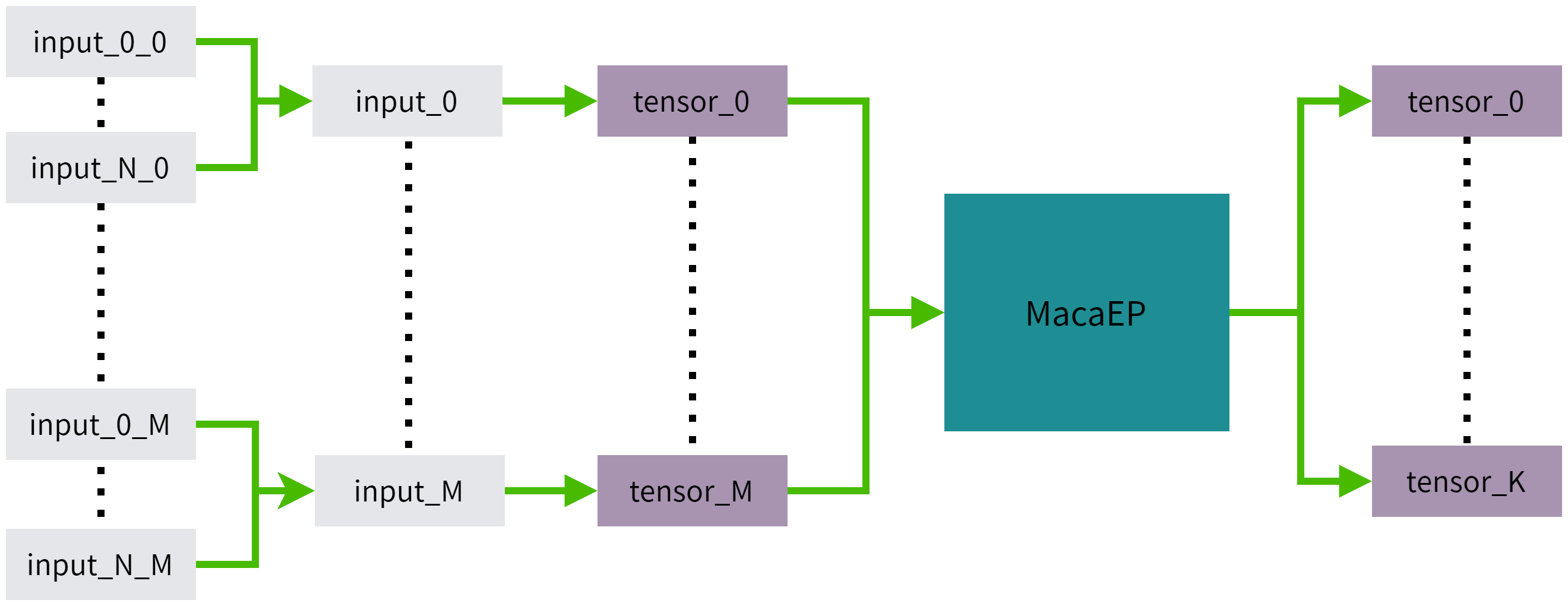
图 3.1 动态Batch推理原理图
操作步骤
准备输入数据。假设提供的模型输入数据和数据长度是通过以下变量名称提供,input_data包含了Batch为N的输入数据,且输入数据位于可分页内存上。
void* input_data[inputNames.size()]; size_t input_data_len[inputNames.size()];
创建MemoryInfo,用于标识输入数据所在的设备信息。
Ort::MemoryInfo memoryInfo =Ort::MemoryInfo::CreateCpu( OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
创建输入Tensors。
std::vector<Ort::Value> inputTensors; for(size_t i=0; i<inputNames.size(); i++){ // get input node data type Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(i); auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo(); ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType(); // get input node data length std::vector<int64_t> inputDims=inputTensorInfo.GetShape(); inputDims[0]=N; inputTensors.push_back(Ort::Value::CreateTensor(memoryInfo,input_data[i], input_data_len[i], inputDims.data(), inputDims.size(),inputType)); }
支持使用以下两种方式获取模型输出。
// session run auto ouput = session.Run(Ort::RunOptions{nullptr},inputNames.data(), inputTensors.data(),inputNames.size(), ouputNames.data(),outputNames.size());
或
// iobinding Ort::IoBinding ioBinding(session); for(size_t i=0; i< inputNames.size(), i++){ ioBinding.BindInput(inputNames[i],inputTensors[i]); } for(size_t i=0; i< outputNames.size(), i++){ ioBinding.BindOutput(outputNames[i],memoryInfo); } session.Run(Ort::RunOptions{nullptr},ioBinding); auto outputs = ioBinding.GetOutputValues();
3.4. 提升曦云系列GPU推理性能
使用MacaRT将ONNX模型部署到曦云系列GPU上时,MacaEP配置信息 OrtMACAProviderOptions 会直接影响MacaRT的推理速度。
OrtMACAProviderOptions 支持的配置选项参见表 3.1。
选项 |
说明 |
|---|---|
device_id |
配置所使用的设备号 |
gpu_mem_limit |
MacaRT使用的最大显存量 |
arena_extend_strategy |
显存增长策略 |
default_memory_arena_cfg |
内存管理配置 |
3.4.1. 设备ID
当有多个 GPU 时,需通过配置 gpu_id 来管理。通过在 OrtMACAProviderOptions 中配置 device_id,可以指定所使用的 gpu_id,默认为0。
OrtMACAProviderOptions maca_options;
maca_options.device_id = your_gpu_id;
3.4.2. MacaRT显存管理
MacaRT提供BFCarena显存管理策略,可以有效地使用显存,避免显存重复申请和显存碎片。有关BFCarena的更多信息,可参考ONNX Runtime相关文档。
有以下两种方法可以配置MacaEP显存管理策略:
直接使用
OrtMACAProviderOptions配置。OrtMACAProviderOptions maca_options; maca_options.gpu_mem_limit=SIZE_MAX; maca_options.arena_extend_strategy=0;
创建一个
OrtArenaCfg对象。auto cfg = Ort::ArenaCfg(SIZE_MAX,0,-1,-1); OrtMACAProviderOptions maca_options; maca_options.default_memory_arena_cfg=cfg.release();
3.5. 自定义算子
MacaRT支持用户定义非官方的ONNX算子进行推理。
操作步骤
使用C++的API构建自定义算子库。
通过使用C++ API或Python API将自定义算子库注册到
SessionOptions对应的MacaEP。加载包含自定义算子的模型进行推理。
上述步骤的具体实现细节,可以参考ONNX Runtime官方文档中关于Cuda EP自定义算子的实现步骤,MacaEP保持基本一致。 也在 /opt/maca-ai/onnxruntime-maca/custom_op_test中提供了完整的实现样例。
以下介绍MacaEP自定义算子的不同之处。
3.5.1. Domain的定义
将自定义算子注册到MacaEP的后端时, Domain 必须设置为 custom.op,即:
static const char* c_OpDomain="custom.op";
3.5.2. Kernel输入输出的数据排布
在构建自定义算子库时,在MacaRT中新增接口用于指定Kernel需要的输入输出数据排布。
OrtDataLayout GetInputDataLayout(size_t index); //指定输入的数据排布
OrtDataLayout GetOutputDataLayout(size_t index); //指定输出的数据排布
当前MacaEP的自定义算子支持以下三种数据排布:
typedef enum OrtDataLayout{
NCHW,
NHWC8,
NHWC16,
}OrtDataLayout;
需要注意的是:
在默认情况下,所有自定义算子Kernel的输入输出都是NCHW格式。
模型的输入数据排布必须是NCHW格式,MacaEP会根据Kernel需求自动进行数据排布的转换。
模型的输出会被MacaEP自动转换为NCHW格式的排布。