6. MacaRT-LLM
6.1. MacaRT-LLM介绍
MacaRT-LLM是在曦云系列GPU上进行大模型部署和执行的推理引擎,是在MXMACA后端适配了OpenPPL-LLM。使用MacaRT-LLM在曦云系列GPU上进行大模型推理,其方法和功能与OpenPPL-LLM完全兼容。
OpenPPL-LLM进行大模型推理的整体流程,如图 6.1 所示,可以分为以下部分:
LLM模型转换,使用MacaPMX将LLM原始模型转换成OpenPPL-LLM支持的ONNX模型。
在PPL.NN.LLM上对模型图进行处理,包括图优化、图拆分、图编译等。
适配PPL.LLM Serving,支持LLM云端服务。
PPL.LLM Kernel Library通过MXMACA Driver在曦云系列GPU上执行模型。
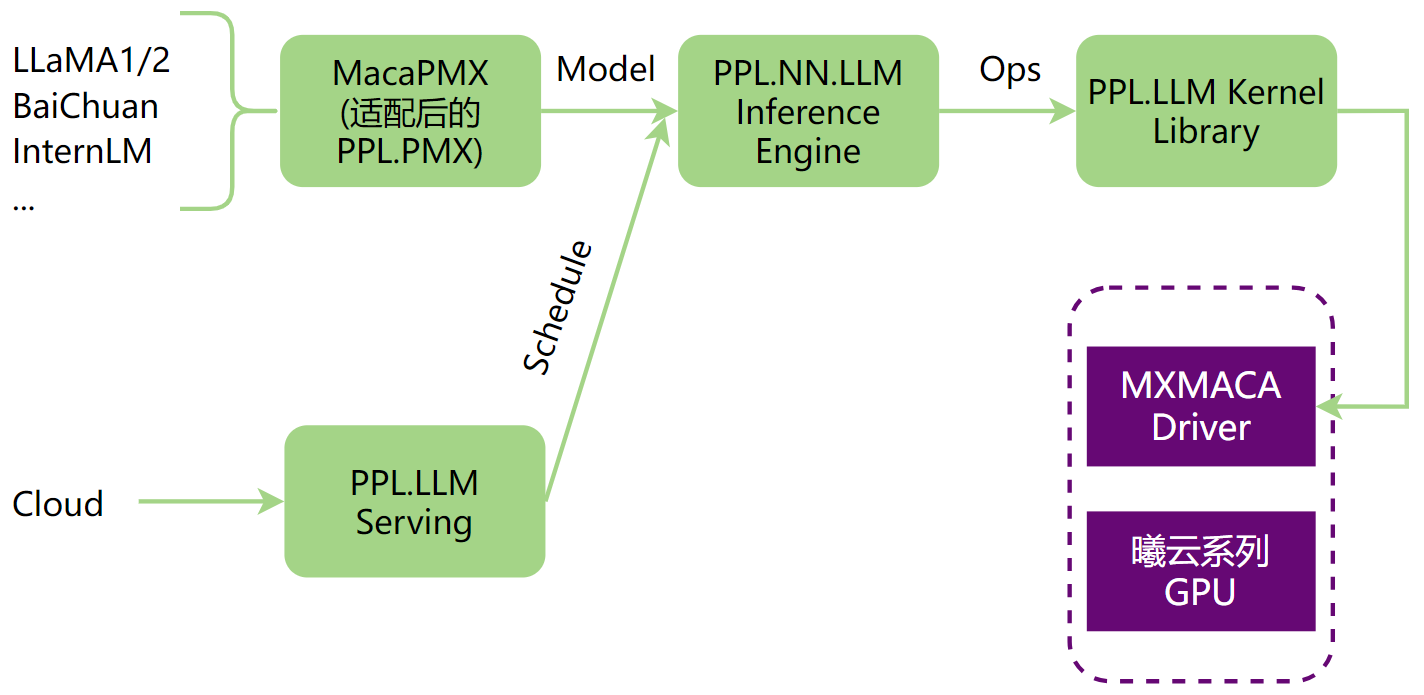
图 6.1 OpenPPL-LLM大模型推理流程图
6.2. MacaRT-LLM功能
MacaRT-LLM完全适配了OpenPPL-LLM,包含了以下功能和特性:
完全适配PPL.PMX,提供MacaPMX支持多种主流大模型进行模型转换。
完全适配PPL.NN.LLM,支持多个主流大模型的推理和模型切分多卡并行推理。
完全适配PPL.LLM.Serving,支持大模型服务化部署。
6.3. MacaRT-LLM使用流程
本章节介绍MacaRT-LLM的使用步骤,主要分为模型转换、本地模型部署验证及服务化部署三个部分。
6.3.1. 模型转换
使用MacaPMX进行模型转换,MacaPMX与PPL.PMX完全适配,为每个OP提供了一组标准的操作符规范文档和相应的函数Python API,使用户可以轻松地在Python中使用PMX自定义的OP构建需要的模型。
目前,MacaPMX主要负责LLM模型结构的表达。 除了PPL.PMX提供的开箱即用的LLM model zoo,用户还可使用MacaPMX提供的模型转换工具(从不同社区的模型到PMX模型)、Tensor并行分割工具和PMX模型合并工具。
6.3.1.1. 安装
MacaPMX以wheel安装包的形式对外发布,建议在Conda环境中安装(建议Python版本3.8)。
操作步骤
下载解压相应发行版的ppl.llm.serving发布包(例如:mxc500-ppl.llm.serving-2.17.3-1-ubuntu18.04-x86_64.tar.xz)后,在解压路径/wheel下找到MacaPMX对应的Python安装包。
执行以下命令,安装MacaPMX。
conda create -n maca_test python=3.8 source activate maca_test pip install macaPMX-*-py3-none-any.whl
wheel包的依赖库主要有:
onnx
torch
fire
sentencepiece
safetensors
其中,torch应为安装相应的曦云系列GPU软件发布包后得到的版本,其余依赖库会在安装MacaPMX时自动安装。
6.3.1.2. 转换为PMX模型
操作步骤(以llama-7b为例)
解压ppl.llm.serving发布包后,在解压路径/ai_deb中可以看到适配后的ppl.llm.serving安装包(ppl.llm.serving_*.deb),执行以下命令进行安装。
sudo dpkg -i ppl.llm.serving_*.deb
安装完成后,在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型转换示例脚本ConvertWeightToPmx.py。
根据需要,修改第4行导入相应模型的转换函数。当前支持的模型及对应导入代码参见表 6.1。
表 6.1 MacaPMX支持的大模型及对应转换函数 LLM Model
ConvertWeightToPmx.py导入代码
Llama全系/其它类Llama大模型
from macaPMX.model_zoo.llama.huggingface import write_pmx_model
chatglm2_6B/chatglm3_6B
from macaPMX.model_zoo.chatglm2.huggingface import write_pmx_model
internlm_7B
from macaPMX.model_zoo.internlm.huggingface import write_pmx_model
BaiChuan2_7B
from macaPMX.model_zoo.baichuan.huggingface import write_pmx_model
Mixtral8x7B
from macaPMX.model_zoo.mixtral.huggingface import write_pmx_model
QWen系列模型
from macaPMX.model_zoo.qwen.huggingface import write_pmx_model
备注
Llama系列对应的PMX转换函数,支持的参数与其它模型不同,支持转换
safetensors格式的原始权重,若使用use_safetensors参数,需要取消示例代码中16-21行及26行的注释。 该参数仅在Llama系列模型上生效,其余模型不能设置该参数,否则程序会执行失败。执行以下命令,将LLM原始权重转换为PMX模型。
python ConvertWeightToPmx.py --input_dir <hf_model_dir> --output_dir <pmx_model_dir> --use_safetensors True
参数说明:
input_dir:LLM原始权重模型路径(文件夹)output_dir:输出PMX模型目标路径(文件夹)use_safetensors:原始权重文件格式是否为safetensors,仅Llama系列支持该参数
6.3.1.3. 模型切分
当模型需要在多卡环境上进行并行推理时,需要将生成的PMX模型进行切分,以适应多卡并行推理。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型切分示例脚本Split.py。
根据需要,修改第2行导入相应模型的切分函数。当前支持的模型及对应导入代码参见表 6.2。
表 6.2 MacaPMX支持的大模型及对应PMX切分函数 LLM Model
Split.py导入代码
Llama/Qwen/其它类Llama大模型
import macaPMX.model_zoo.llama.modeling.SplitModel as SplitModel
Mixtral8x7B
import macaPMX.model_zoo.mixtral.modeling.SplitModel as SplitModel
执行以下命令,进行模型拆分。
python Split.py --input_dir <input_directory_path> --num_shards <number_of_shards> --output_dir <output_directory_path>
参数说明:
input_dir:待切分PMX模型路径(文件夹)num_shards:PMX模型切分份数output_dir:切分后PMX模型目标路径(文件夹)
6.3.1.4. 模型合并(可选)
该操作与模型切分相反,将多个切分后的PMX模型合并成一个。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型合并示例脚本Merge.py。
根据需要,修改第2行导入相应模型的合并函数。当前支持的模型及对应导入代码参见表 6.3。
表 6.3 MacaPMX支持的大模型及对应PMX合并函数 LLM Model
Merge.py导入代码
Llama/Qwen/其它类Llama大模型
import macaPMX.model_zoo.llama.modeling.MergeModel as MergeModel
Mixtral8x7B
import macaPMX.model_zoo.mixtral.modeling.MergeModel as MergeModel
执行以下命令,对切分后PMX模型进行合并。
python merge.py --input_dir <input_directory_path> --num_shards <number_of_shards> --output_dir <output_directory_path>
参数说明:
input_dir:待合并PMX模型路径(文件夹)num_shards:PMX子模型的份数output_dir:合并后PMX模型目标路径(文件夹)
6.3.1.5. PMX模型测试
当生成PMX模型后,使用torch加载PMX模型并执行LLM推理,根据输出结果验证PMX模型转换的正确性。 同时,若设置相应dump参数,可以将模型对应step的输入、输出保存下来,作为后续本地部署精度验证的输入及输出参考值。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取PMX模型测试示例脚本Demo.py。
根据需要,修改第2行导入相应模型的PMX运行函数。当前支持的模型及对应导入代码参见表 6.4。
表 6.4 MacaPMX支持的大模型及对应PMX模型运行函数 LLM Model
Demo.py导入代码
Llama全系/其它类Llama大模型
from macaPMX.model_zoo.llama.huggingface import run_demo
chatglm2_6B/chatglm3_6B
from macaPMX.model_zoo.chatglm2.huggingface import run_demo
internlm_7B
from macaPMX.model_zoo.internlm.huggingface import run_demo
BaiChuan2_7B
from macaPMX.model_zoo.baichuan.huggingface import run_7B
Mixtral8x7B
from macaPMX.model_zoo.mixtral.huggingface import run_demo
QWen系列模型
from macaPMX.model_zoo.qwen.huggingface import run_demo
备注
BaiChuan2_7B对应的PMX运行函数与其余模型不同,需要同步修改第5行中的函数名。
执行以下命令,验证PMX模型精度。
OMP_NUM_THREADS=1 torchrun --nproc_per_node $num_gpu Demo.py --ckpt_dir <llama_dir> --tokenizer_path <llama_tokenizer_dir>/tokenizer.model --fused_qkv 1 --fused_kvcache 1 --auto_causal 1 --quantized_cache 1 --dynamic_batching 1 --seqlen_scale_up 1 --max_gen_len 256 --dump_steps 0,1,255 --dump_tensor_path <dump_dir> --batch 1 --cache_layout 3
参数说明:
num_gpu:模型推理需要的GPU数量ckpt_dir:PMX模型路径tokenizer_path:tokenizer模型路径当需要保存测试数据时,设置以下参数:
seqlen_scale_up:输入字节大小的比例因子(序列长度按8放大)max_gen_len:指定生成的最大输出长度(以字节为单位)dump_steps:保存测试数据的step,可以指定多个step,以“,”分隔。若只保存单个step,必须用“,”结尾,否则会执行失败。dump_tensor_path:保存测试数据的路径batch:指定数据处理的批大小cache_layout:cacheAttention中cache存储layout,当前仅支持0和3。0:layout为[MaxT, L, 2, H, Dh];3:layout为[L, 2, H, MaxT, Dh]。建议设置为3,性能更佳。其余参数与命令中保持一致即可。
备注
cache_layout的设置需要与 6.3.1.6 导出为ONNX模型 中的设置一致,否则 6.3.2 本地模型部署精度验证 会失败。
6.3.1.6. 导出为ONNX模型
在验证PMX模型精度无误后,可以执行最终步骤:将PMX导出至ONNX模型。
操作步骤
在/opt/maca-ai/ppl.llm.serving/samples/samples/model_converter/路径下获取ONNX模型导出示例脚本Export.py。
根据需要,修改第2行导入相应模型的ONNX导出函数。当前支持的模型及对应导入代码参见表 6.5。
表 6.5 MacaPMX支持的大模型及对应ONNX导出函数 LLM Model
Export.py导入代码
Llama全系/其它类Llama 大模型
from macaPMX.model_zoo.llama.huggingface import run_export
chatglm2_6B/chatglm3_6B
from macaPMX.model_zoo.chatglm2.huggingface import run_export
internlm_7B
from macaPMX.model_zoo.internlm.huggingface import run_export
BaiChuan2_7B
from macaPMX.model_zoo.baichuan.huggingface import export_7B
Mixtral8x7B
from macaPMX.model_zoo.mixtral.huggingface import run_export
QWen系列模型
from macaPMX.model_zoo.qwen.huggingface import run_export
备注
BaiChuan2_7B对应的ONNX导出函数与其余模型不同,需要同步修改第5行中的函数名。
执行以下命令,将PMX模型导出为ONNX模型。
OMP_NUM_THREADS=1 torchrun --nproc_per_node $num_gpu Export.py --ckpt_dir <llama_dir> --tokenizer_path <llama_tokenizer_dir>/tokenizer.model --fused_qkv 1 --fused_kvcache 1 --auto_causal 1 --quantized_cache 1 --dynamic_batching 1 --export_path <export_dir> --cache_layout 3
参数说明:
num_gpu:模型推理需要的GPU数量ckpt_dir:PMX模型路径tokenizer_path:tokenizer模型路径;chatglm系列模型不支持此参数,无需设置。export_path:导出ONNX模型目标路径cache_layout:cacheAttention中cache存储layout,当前仅支持0和3。0:layout为[MaxT, L, 2, H, Dh];3:layout为[L, 2, H, MaxT, Dh]。建议设置为3,性能更佳。其余参数与命令中保持一致即可。
6.3.2. 本地模型部署精度验证
大多数情况下,大模型会依托服务端部署提供服务端接口供客户端调用,但在服务化部署前,需要依托本地模型部署进行推理验证,以确认模型精度是否符合预期。 本章节介绍模型本地部署及精度验证的方法。
本地部署精度验证依赖工具如下:
pplnn_llm:本地部署可执行文件,安装ppl.llm.serving_*_amd64.deb后在/opt/maca-ai/ppl.llm.serving/bin/下获取。
操作步骤
创建一个测试bash脚本benchmark.sh,内容如下:
if [ -n "$MPI_LOCALRANKID" ]; then MPI_LOCALRANKID=$MPI_LOCALRANKID elif [ -n "$OMPI_COMM_WORLD_RANK" ]; then MPI_LOCALRANKID=$OMPI_COMM_WORLD_RANK elif [ -n "$PMI_RANK" ]; then MPI_LOCALRANKID=$PMI_RANK else echo "[WARNING] MPI_LOCALRANKID not found, set to 0" MPI_LOCALRANKID=0 fi DEVICE_ID=$MPI_LOCALRANKID STEP=$1 if [ ! -n "$STEP" ]; then STEP=0 fi MODEL_PATH="/path/to/exported/model/model_slice_${MPI_LOCALRANKID}/model.onnx" OUTPUT_DIR="/path/to/output_dir/rank_${MPI_LOCALRANKID}" # we should make the rank_* directories first TEST_DATA_DIR="/path/to/dumped/tensor/data/rank_${MPI_LOCALRANKID}" # we should rearrange the input tensors if the model exporting parameters has been changed. TOKEN_IDS=`ls ${TEST_DATA_DIR}/step${STEP}_token_ids-*` ATTN_MASK=`ls ${TEST_DATA_DIR}/step${STEP}_attn_mask-*` SEQSTARTS=`ls ${TEST_DATA_DIR}/step${STEP}_seqstarts-*` KVSTARTS=`ls ${TEST_DATA_DIR}/step${STEP}_kvstarts-*` CACHESTARTS=`ls ${TEST_DATA_DIR}/step${STEP}_cachestarts-*` DECODING_BATCHES=`ls ${TEST_DATA_DIR}/step${STEP}_decoding_batches-*` START_POS=`ls ${TEST_DATA_DIR}/step${STEP}_start_pos-*` AX_SEQLEN=`ls ${TEST_DATA_DIR}/step${STEP}_max_seqlen-*` MAX_KVLEN=`ls ${TEST_DATA_DIR}/step${STEP}_max_kvlen-*` KV_CAHCE=`ls ${TEST_DATA_DIR}/step${STEP}_kv_cache-*` KV_SCALE=`ls ${TEST_DATA_DIR}/step${STEP}_kv_scale-*` TEST_INPUTS="$TOKEN_IDS,$ATTN_MASK,$SEQSTARTS,$KVSTARTS,$CACHESTARTS,$DECODING_BATCHES,$START_POS,$MAX_SEQLEN,$MAX_KVLEN,$KV_CAHCE,$KV_SCALE" INPUT_DEVICES="device,device,device,device,device,host,device,host,host,device,device" CMD="/opt/maca-ai/ppl.llm.serving/bin/pplnn_llm --use-llm-cuda \ --onnx-model $MODEL_PATH \ --shaped-input-files $TEST_INPUTS \ --save-outputs \ --device-id $DEVICE_ID \ --save-data-dir $OUTPUT_DIR \ --in-devices $INPUT_DEVICES \ --enable-profiling \ --min-profiling-seconds 3 \ --warmup-iterations 10" echo "RUN RANK${MPI_LOCALRANKID} STEP${STEP} -> $CMD" eval "$CMD"
参数说明:
MODEL_PATH: 6.3.1.6 导出为ONNX模型中导出的ONNX模型路径OUTPUT_DIR:模型输出文件保存路径TEST_DATA_DIR:模型输入文件保存路径,模型输入数据的操作步骤参见 6.3.1.5 PMX模型测试备注
需要将CMD中对应
pplnn_llm设置为安装后放置的路径或者自定义路径,这里默认设置为安装路径。设置环境变量并运行测试脚本生成输出数据。
export MACA_PATH=your_maca_path export PATH=${MACA_PATH}/bin:${PATH} export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${MACA_PATH}/ompi/lib:${LD_LIBRARY_PATH} export USE_GEMM_NN=true benchmark.sh <STEP> #单卡推理测试命令 mpirun -np 4 benchmark.sh <STEP> #四卡推理测试命令,-np参数设置与推理卡数一致
执行完上述命令后,会在设置的OUTPUT_DIR保存对应step的输出数据。后续可以根据需求与 6.3.1.5 PMX模型测试中保存的输出参考数据进行比对。 输出数据格式为float32,使用np.fromfile(data_path, np.float32)即可加载。
6.3.3. 本地模型部署性能测试
为了探测特定大模型的极限性能,可以在本地进行性能测试,为后续服务端部署性能做一个参照,进而优化服务端部署参数设置,最大限度发挥出曦云系列GPU的硬件性能。
本地部署性能测试依赖工具如下:
benchmark_llama:性能测试可执行文件,安装ppl.llm.serving_*_amd64.deb后在/opt/maca-ai/ppl.llm.serving/bin/下获取。当前仅支持llama系列及类llama模型的测试。
操作步骤(以llama-7b为例)
创建一个测试bash脚本benchmark_7b.sh,内容如下:
#!/bin/bash MODEL_TYPE="llama" MODEL_DIR="/mnt/hpc/shengyunrui/model_card/llama_7b_ppl" MODEL_PARAM_PATH="/mnt/hpc/shengyunrui/model_card/llama_7b_ppl/params.json" TENSOR_PARALLEL_SIZE=1 TOP_P=0.0 TOP_K=1 TEMPERATURE=1.0 WARMUP_LOOPS=2 BENCHMARK_LOOPS=2 INPUT_FILE_BASE="tokens_input" INPUT_LEN=8 GENERATION_LEN=256 BATCH_SIZE_LIST=(1 2 4 8 16 32 64 128 256) for BATCH_SIZE in ${BATCH_SIZE_LIST[@]}; do INPUT_FILE=${INPUT_FILE_BASE}_${INPUT_LEN} your_path_of_benchmark_llama \ --model-type $MODEL_TYPE \ --model-dir $MODEL_DIR \ --model-param-path $MODEL_PARAM_PATH \ --tensor-parallel-size $TENSOR_PARALLEL_SIZE \ --top-p $TOP_P \ --top-k $TOP_K \ --temperature $TEMPERATURE \ --warmup-loops $WARMUP_LOOPS \ --generation-len $GENERATION_LEN \ --benchmark-loops $BENCHMARK_LOOPS \ --input-file $INPUT_FILE \ --batch-size $BATCH_SIZE done
参数说明:
MODEL_TYPE:LLM模型类型,当前仅支持LlamaMODEL_DIR: 6.3.1.6 导出为ONNX模型中导出的ONNX模型路径MODEL_PARAM_PATH: 6.3.1.6 导出为ONNX模型中导出ONNX模型的params.json文件路径TENSOR_PARALLEL_SIZE:Tensor并行大小,需要与 6.3.1.3 模型切分中模型切分数量保持一致,即导出模型为2卡并行,此处设置为2;4卡并行则设置为4WARMUP_LOOPS:warmup执行次数,在正式测试前执行该次数的warmupBENCHMARK_LOOPS:性能测试执行次数INPUT_FILE_BASE:模型输入文件基础文件名,默认为tokens_input,测试输入的文件名称为${INPUT_FILE_BASE}_${INPUT_LEN},即通过基础文件名和输入长度拼接。 例如,输入长度为8的输入文件名称为tokens_input_8INPUT_LEN:模型输入token长度GENERATION_LEN:模型生成token长度BATCH_SIZE_LIST:性能测试batchsize列表,测试会遍历该列表中所有设置输入文件为文本文件,每一行代表一条输入token,各token之间用空格分隔,
以INPUT_LEN=8为例,该文件的构成如下。篇幅限制,这里只展示前8条输入token。 该文件的行数(lines_of_token)必须大于等于测试设置的最大batchsize,否则该batchsize设置无效,测试程序只能执行最大batchsize = lines_of_token的测试,详细可参考相关文件。1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338 1, 306, 4658, 278, 6593, 310, 2834, 338
设置环境变量并运行测试脚本生成输出数据。
export MACA_PATH=your_maca_path export PATH=${MACA_PATH}/bin:${PATH} export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH} export USE_GEMM_NN=true benchmark_7b.sh
执行完上述命令后,会输出对应设置下的性能测试数据,如下所示:
CSV format header:prefill(ms),decode(ms),avg(ms),tps(ms),mem(gib) CSV format output:40.16,14.2576,14.4599,69.1567,14.3461
分别对应prefill耗时、平均decode延迟、平均step延迟、tokens吞吐(tokens per second)以及显存使用。
备注
执行测试脚本前,需要激活测试环境变量,否则会测试失败。
6.3.4. 服务化部署
大模型服务化部署是一种将大模型应用于实际场景的有效方式。它具有以下优势:
提供更高的性能和更准确的结果。由于大模型具备更深层次的理解和更复杂的参数配置,其在各种任务上表现更出色。 通过将大模型部署为服务,可以利用其强大的计算能力和学习能力,为用户提供更高质量的预测、推荐和决策。
可以实现灵活的扩展性和定制化需求。采用服务化架构,可以将模型与其他组件解耦,使得系统更易于扩展和维护。 同时,根据不同业务需求,可以对大模型进行个性化的调整和优化,以满足特定任务的要求。
提升数据安全和隐私保护。通过将模型部署在云端或私有环境中,可以有效保护敏感数据的安全性,避免将数据传输到公共网络或设备中。 这种集中化的方式可以通过严格的权限控制和加密技术来保护用户数据的隐私。
总的来说,大模型服务化部署具有性能优越、灵活扩展和安全保护等诸多优势,可为各行各业提供更高水平的智能服务。
本节将从服务端部署、C++客户端部署、Python客户端部署三个部分介绍服务化部署。
6.3.4.1. 服务端部署
服务端部署依赖文件如下:
ppl_llm_server:服务端部署可执行文件,安装ppl.llm.serving_*_amd64.deb后在/opt/maca-ai/ppl.llm.serving/bin/下获取。
xxx_config.json:特定大模型配置文件,ppl_llm_server通过解析该配置文件加载并运行对应的模型。 安装 ppl.llm.serving_*_amd64.deb 后,在 /opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/model_config/ 路径下,可找到当前所有已支持模型的配置示例。
操作步骤(以llama-7b为例)
创建llama_7b_config.json,主要内容如下:
{ "model_type": "llama", "model_dir": "/path/to/model/dir", "model_param_path": "/path/to/model/dir/params.json", "tokenizer_path": "/path/to/tokenizer/tokenizer.model", "tensor_parallel_size": 1, "top_p": 0.0, "top_k": 1, "quant_method": "none", "max_tokens_scale": 0.6, "max_tokens_per_request": 4096, "max_running_batch": 1024, "max_tokens_per_step": 8192, "host": "0.0.0.0", "port": 23333 }
参数说明:
model_type:LLM模型类型,可参考 /opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/model_config 中已支持模型的配置示例进行配置model_dir: 6.3.1.6 导出为ONNX模型中导出的ONNX模型路径model_param_path: 6.3.1.6 导出为ONNX模型中导出ONNX模型的params.json文件路径tokenizer_path:tokenizer模型路径tensor_parallel_size:Tensor并行大小,需要与 6.3.1.3 模型切分中模型切分数量保持一致,即导出模型为2卡并行,此处设置为2;4卡并行则设置为4max_tokens_scale:设置范围[0.1, 0.9],该参数会影响服务端对显存的使用。 简单地说,代表模型加载完成后,额外占用剩余显存的比例,受制于当前显存碎片化管理不够完善,随着请求次数增加,显存会出现溢出,建议设置一个较小的值。 若测试大batchsize,建议设置大一些(0.9),否则由于预分配显存不够,无法按照设定的batchsize执行大模型推理,但此时请求的次数要比较少,否则也会出现显存溢出max_tokens_per_request:单次请求的最大token数,建议设置4096max_running_batch:执行推理最大batchsizemax_tokens_per_step:单个step处理最大token数设置环境变量并运行服务端程序,启动llama_7b服务。
export MACA_PATH=your_maca_path export PATH=${MACA_PATH}/bin:${PATH} export LD_LIBRARY_PATH=${MACA_PATH}/lib:${MACA_PATH}/mxgpu_llvm/lib:${LD_LIBRARY_PATH} export USE_GEMM_NN=true export SHOW_PREFILL=true #若需要输出prefill性能统计数据,设置该环境变量 ./ppl_llm_server llama_7b_config.json
当输出下列日志时,表示llama_7b服务启动完成:
[INFO][2023-12-07 16:05:29.304][llama_worker.cc:962] waiting for request ...
6.3.4.2. C++客户端部署
安装ppl.llm.serving_*_amd64.deb后,可在/opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/cpp_client/路径下获取C++代码示例。 安装路径中有该代码示例已编译生成的可执行文件:/opt/maca-ai/ppl.llm.serving/bin/cpp_client。工程文件目录如图 6.2 所示:
cmake:文件夹,包含三方依赖库cmake配置。
CMakeLists.txt:CMake配置文件。
proto:文件夹,包含与服务端交互时grpc依赖的proto文件。
src:文件夹,包含client_sample.cc,是C++客户端的简单使用示例程序。
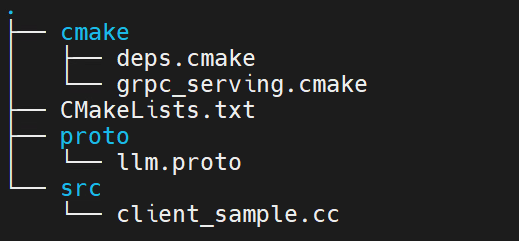
图 6.2 C++客户端目录结构图
参考client_sample.cc示例代码,根据业务需求定制相应的C++客户端即可。
编译时需要将cmake/deps.cmake中37-39行、41-43行中grpc、absl依赖库地址修改为:
hpcc_declare_git_dep(grpc
https://github.com/grpc/grpc.git
v1.56.2)
hpcc_declare_git_dep(absl
https://github.com/abseil/abseil-cpp.git
lts_2023_01_25)
6.3.4.3. Python客户端部署
安装ppl.llm.serving_*_amd64.deb后,可在/opt/maca-ai/ppl.llm.serving/samples/samples/ppl_server_client/python_client/路径下获取Python代码示例。 工程文件目录如图 6.3 所示:
llm_pb2.py:与服务端交互时grpc依赖的proto定义文件。
llm_pb2_grpc.py:与服务端交互时grpc依赖的proto定义文件。
client.py:Python客户端示例脚本。

图 6.3 Python客户端目录结构图
参考client.py示例代码,根据业务需求定制相应的Python客户端即可。
Python客户端依赖grpc,使用时需安装grpcio、grpcio-tools两个依赖项。
pip install grpcio
pip install grpcio-tools
6.3.4.4. 服务端输出性能数据解析
服务端完成部署,客户端成功发送请求,服务端完成请求的处理并将结果发送至客户端后,服务端会输出当前部署大模型的性能数据。示例如图 6.4 所示:
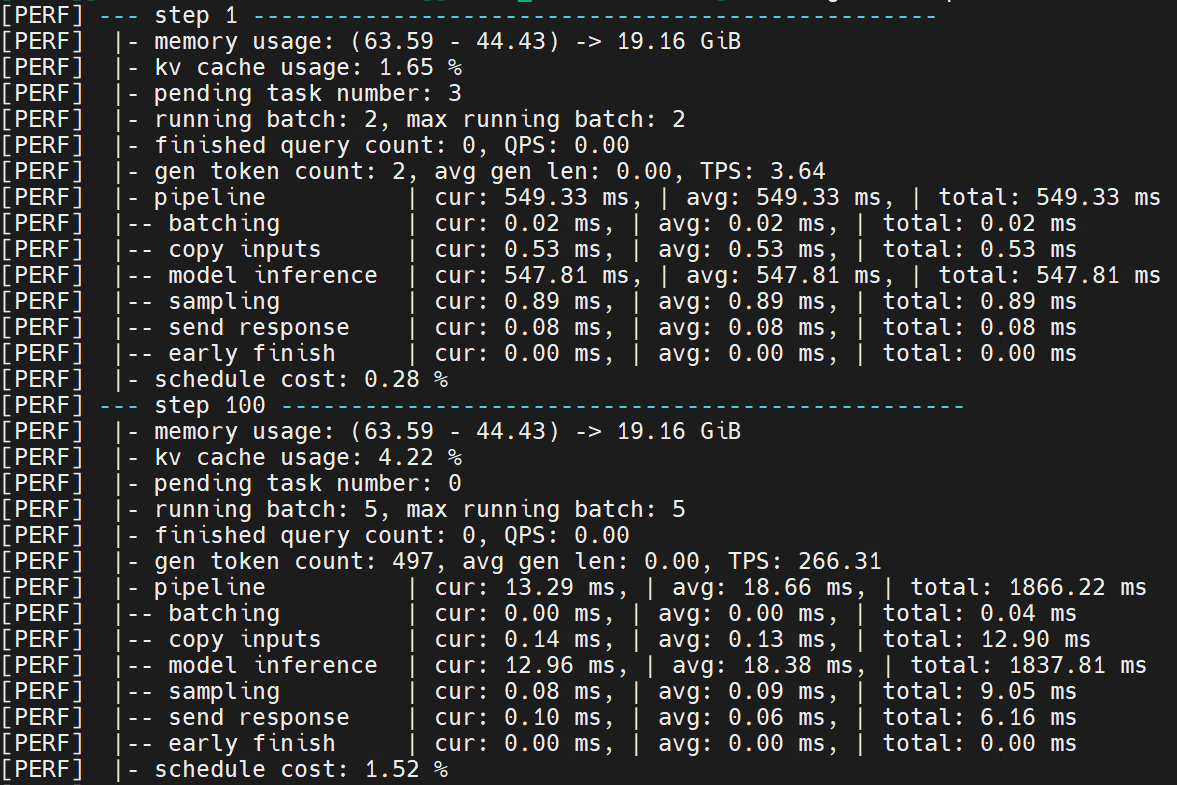
图 6.4 服务端输出性能数据示例(llama-7b)
若在启动服务前设置 SHOW_PREFILL 环境变量,服务端会输出prefill阶段的性能数据,即图 6.4 中step1的性能数据;若不设置,则输出100整数倍及最后一个step的性能数据。
重点性能参数包括:
memory usage :当前step显存使用情况
running batch :当前step正在推理的batchsize
max running batch :从当前step回溯的历史最大推理batchsize
finished query count :当前step已经结束生成的请求数量
pipeline :整体流程耗时,包含当前step耗时,平均耗时及总耗时
model inference :大模型推理的耗时,包含当前step耗时,平均耗时及总耗时