4. 组件介绍
4.1. 组件总览
沐曦 GPU 方案包含多个核心组件,覆盖从 GPU 资源管理、驱动配置、运行时支持到任务调度的全生命周期。
4.1.1. 模式说明
常规模式:默认安装完整组件,包含驱动管理、运行时支持、拓扑发现等全功能模块,适用于需要自动化管理 GPU 驱动、资源调度的生产环境
MinimalMode:仅安装最小运行组件,不包含驱动和私有运行时,需手动准备内核驱动和 MXMACA® SDK,适用于特定业务场景,如驱动已提前部署的集群
4.1.2. 组件清单与功能
下表列出了沐曦GPU方案的核心组件及其在不同部署模式下的包含情况。每个组件都承担着特定的功能职责,共同构建完整的GPU资源管理和调度体系。
组件 |
常规模式 |
MinimalMode |
|---|---|---|
gpu-label |
必选 |
必选 |
gpu-device |
必选 |
必选 |
container-runtime |
必选 |
不包含 |
driver |
必选 |
不包含 |
maca |
必选 |
不包含 |
mx-exporter |
可选 |
可选 |
topoDiscovery |
可选 |
可选 |
gpu-scheduler |
可选 |
可选 |
4.2. 通用配置
4.2.1. podTemplateSpec
4.2.1.1. 简介
每个组件 CR 均提供 podTemplateSpec 字段,可直接覆盖对应工作负载的 Pod 模板, 例如 DaemonSet 和 Deployment。
该字段与 Kubernetes 原生 PodSpec 完全兼容,支持 nodeSelector、affinity、tolerations 及全部其他子字段,无需关注 Operator 内部实现细节。
4.2.1.2. 配置说明
详细描述参见 表 3.22 Custom Pod Template Spec Options。
配置规则:
组件级 ﹥ 全局级:组件单独配置时忽略全局模板
基础类型:直接替换,如字符串、布尔值
集合类型:数组追加,Map 合并(冲突键覆盖)
4.2.1.3. 功能介绍 ( tolerations 为例)
安装时配置
系统支持三种配置方式:
优先级为:
--set-file﹥--set﹥ 编辑 values.yaml。编辑 values.yaml
# 全局配置 podTemplateSpec: spec: tolerations: - key: "node-type" operator: "Equal" value: "general" effect: "NoSchedule" # 组件级配置(maca) maca: podTemplateSpec: spec: tolerations: - key: "node-type" operator: "Equal" value: "gpu" effect: "NoSchedule"
通过
--set传入配置helm install <metax-operator-chart> --generate-name \ --set maca.podTemplateSpec.spec.tolerations[0].key="node-type" \ --set maca.podTemplateSpec.spec.tolerations[0].operator="Equal" \ --set maca.podTemplateSpec.spec.tolerations[0].value="gpu" \ --set maca.podTemplateSpec.spec.tolerations[0].effect="NoSchedule"
通过
--set-file传入配置# maca-podTemplateSpec-config.yaml spec: tolerations: - key: "node-type" operator: "Equal" value: "gpu" effect: "NoScheudle"
准备好如上所示配置文件后,可通过
--set-file方式将配置导入:helm install <metax-operator-chart> --generate-name \ --set-file maca.podTemplateSpecFile=maca-podTemplateSpec-config.yaml
注意
--set-file方式指定的字段为podTemplateSpecFile。
运行时动态调整
通过
kubectl更新配置:# 编辑集群 Operator CR kubectl edit clusteroperators.gpu.metax-tech.com cluster-operator # 修改后保存生效
4.2.1.4. 配置示例
全局级配置
# 全局 podTemplateSpec spec: podTemplateSpec: spec: nodeSelector: kubernetes.io/os: linux tolerations: - key: "node-type" operator: "Equal" value: "general" effect: "NoSchedule"
组件级配置,以 maca 为例
# 组件级 podTemplateSpec maca: podTemplateSpec: spec: nodeSelector: metax-tech.com/component: maca tolerations: - key: "node-type" operator: "Equal" value: "gpu" # 覆盖全局的 "general" 配置 effect: "NoSchedule"
4.2.1.5. 配置验证
查看组件 Pod 配置
# 查看 maca 组件 DaemonSet 的 tolerations kubectl get ds -n metax-operator metax-maca -o jsonpath='{.spec.template.spec.tolerations}'
预期输出(组件级优先)
- key: "node-role" # 默认模板字段 operator: "Equal" value: "maca" effect: "NoSchedule" - key: "node-type" # 组件级覆盖字段 operator: "Equal" value: "gpu" effect: "NoSchedule"
全局配置验证(未被组件覆盖的组件)
# 查看 driver 组件 DaemonSet 的 tolerations kubectl get ds -n metax-operator metax-driver -o jsonpath='{.spec.template.spec.tolerations}'
- key: "node-role" # 默认模板字段 operator: "Equal" value: "driver" effect: "NoExecute" - key: "node-type" # 全局配置字段 operator: "Equal" value: "general" effect: "NoSchedule"
4.2.1.6. 注意事项
字段兼容性:需严格遵循 Kubernetes PodSpec 规范,避免无效配置,如错误的亲和性规则
离线环境适配:若节点存在污点,如 GPU 节点独占,需通过 tolerations 显式声明允许调度
配置冲突排查:通过
kubectl describe命令查看 Pod/ DaemonSet 的实际配置,确认优先级规则是否正确应用
4.3. gpu-label
4.3.1. 简介
自动为节点添加或更新标签,辅助 Kubernetes 调度系统识别 GPU 资源。
4.3.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.gpuLabel,完整字段说明参见 表 3.3 gpu-label Options。
4.3.3. 组件功能
4.3.3.1. 节点标签生成
gpu-label会扫描节点上GPU状态,在节点上生成对应的标签,组件管理的标签参考如下:
标签 |
类型 |
描述 |
|---|---|---|
gpu.installed |
bool |
若节点配置了沐曦GPU,值为 |
driver.ready |
bool |
若节点已安装内核驱动,值为 |
gpu.driver.major |
integer |
内核驱动程序的主版本号 |
gpu.driver.minor |
integer |
内核驱动程序的次版本号 |
gpu.driver.mode |
enum |
驱动管理模式, |
gpu.driver.patch |
integer |
内核驱动程序的补丁版本号 |
gpu.family |
string |
显卡系列 |
gpu.memory |
string |
显卡内存大小 |
gpu.product |
string |
显卡型号 |
gpu.sriov |
string |
SR-IOV状态,可能为 |
gpu.vfnum |
integer |
显卡虚拟化配置 |
4.4. gpu-device
4.4.1. 简介
负责 GPU 设备的全生命周期管理,包括设备发现、健康状态监测及资源暴露。
负责 GPU 设备的全生命周期管理,包括设备发现、健康状态监测及资源暴露
GPU拓扑最优分配
周期性执行 GPU 健康检查,实时监控设备状态
向 Kubernetes 集群注册 GPU 设备,确保 Pod 可识别和调度 GPU 资源
4.4.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.gpuDevice,完整字段说明见 表 3.2 gpu-device Options。
4.4.3. 组件功能
4.4.3.1. 健康检查
gpu-device以一定间隔周期性检查节点上的每个GPU设备,对发现故障的GPU资源进行状态上报。 Kubernetes根据上报信息将相关资源从 Allocatable 资源中移除,从而避免故障资源影响后续作业。
4.4.3.2. GPU拓扑最优分配
在单台服务器上配置多张GPU时,GPU卡间根据双方是否连接在相同的 PCIe Switch 或 MetaXLink 下,存在近远(带宽高低)关系。服务器上所有卡间据此形成一张拓扑,如下图所示:

图 4.1 典型拓扑示意图
用户作业请求一定数量的 metax-tech.com/gpu 资源,Kubernetes选择剩余资源数量满足要求的节点,并将 Pod 调度到相应节点。
gpu-device进一步处理资源节点上剩余资源的分配逻辑,并按照以下优先级逻辑为作业容器分配GPU设备:
MetaXLink优先级高于PCIe Switch,包含两层含义:两卡之间同时存在
MetaXLink连接以及PCIe Switch连接时,认定为MetaXLink连接服务器剩余GPU资源中
MetaXLink互联资源与PCIe Switch互联资源均能满足作业请求时,分配MetaXLink互联资源
分配GPU资源尽可能位于相同
MetaXLink或PCIe Switch下: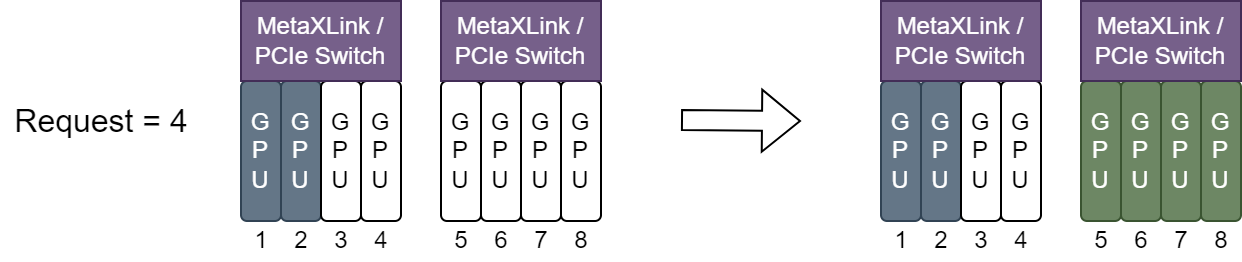
图 4.2 GPU资源分配示例1
如上图所示,GPU
1,2已被分配,新分配 4 张GPU时,只有GPU5,6,7,8满足本条规则,因此是唯一分配方案。分配GPU资源后,剩余资源尽可能完整:

图 4.3 GPU资源分配示例2
如上图所示,GPU
1,2已被分配,新分配 2 张GPU时,分配GPU3,4可使剩余资源全部位于同一MetaXLink或PCIe Switch下,因此是遵循本条规则的唯一分配方案。
备注
尽管gpu-device在拓扑最优以及避免碎片上做了最大的努力,实际使用过程中并不能完全杜绝碎片的产生。
因此建议在集群使用时尽量以 1, 2, 4, 8 这样的粒度来分配GPU,最大限度地降低碎片的可能。
4.4.3.3. GPU拓扑信息
拓扑信息由Kubernetes节点标签 metax-tech.com/gpu.topology.losses 和 metax-tech.com/gpu.topology.scores 标识。例如下表中的集群节点信息:
节点 |
标签 |
|---|---|
node1 |
|
node1 |
|
node2 |
|
node2 |
|
例如node1的两个标签:
metax-tech.com/gpu.topology.scores中"2":110,代表在当前节点上申请2张显卡时,它们的通信拓扑分数是 110。通信拓扑分数越大,通信效率越高。metax-tech.com/gpu.topology.losses中"1":220,代表在当前节点上申请2张显卡时,通信拓扑损失分数是 220。拓扑损失分数越大,剩余卡的通信效率越低。
4.4.3.4. vfio-gpu资源申请
gpu-device会将绑定了 vfio-pci 驱动的沐曦GPU注册为 metax-tech.com/vfio-gpu 资源,用户可以在 KubeVirt 上申请该资源。
在
KubeVirtCR中的featureGates添加HostDevices, GPU选项,并将沐曦GPU相应的设备信息配置到permittedHostDevices中。1apiVersion: kubevirt.io/v1 2kind: KubeVirt 3metadata: 4 name: kubevirt 5 namespace: kubevirt 6spec: 7 certificateRotateStrategy: {} 8 configuration: 9 developerConfiguration: 10 featureGates: ["HostDevices", "GPU"] 11 permittedHostDevices: 12 pciHostDevices: 13 - pciVendorSelector: "9999:4000" 14 resourceName: "metax-tech.com/vfio-gpu" 15 externalResourceProvider: true 16 - pciVendorSelector: "9999:4018" 17 resourceName: "metax-tech.com/vfio-gpu" 18 externalResourceProvider: true 19 customizeComponents: {} 20 imagePullPolicy: IfNotPresent 21 workloadUpdateStrategy: {}
在虚拟机配置的
hostDevices中添加metax-tech.com/vfio-gpu设备。1apiVersion: kubevirt.io/v1 2kind: VirtualMachine 3metadata: 4 labels: 5 kubevirt.io/vm: testvm 6 name: testvm 7spec: 8 running: false 9 template: 10 metadata: 11 labels: 12 kubevirt.io/vm: testvm 13 spec: 14 domain: 15 devices: 16 disks: 17 - disk: 18 bus: virtio 19 name: containerdisk 20 - disk: 21 bus: virtio 22 name: cloudinitdisk 23 interfaces: 24 - name: default 25 masquerade: {} 26 hostDevices: 27 - deviceName: metax-tech.com/vfio-gpu 28 name: gpu 29 resources: 30 requests: 31 memory: 4096Mi 32 terminationGracePeriodSeconds: 0 33 networks: 34 - name: default 35 pod: {} 36 volumes: 37 - containerDisk: 38 image: registry:5000/kubevirt/cirros-container-disk-demo:devel 39 name: containerdisk 40 - cloudInitNoCloud: 41 userData: | 42 #!/bin/sh 43 44 echo 'printed from cloud-init userdata' 45 name: cloudinitdisk
虚拟机启动成功后,可以通过
lspci命令看到对应的设备。user@testvm:~$ lspci | grep 9999 0a:00.0 Display controller: Device 9999:4000 (rev 01)
4.4.3.5. 配置sGPU
sGPU是软件实现的算力切分方案,可以基于物理GPU创建最多16个虚拟GPU实例,主要面向基于容器的云端推理和小模型训练场景。
当gpu-device以sGPU模式运行时,对应节点上的沐曦GPU会启用GPU共享功能,并注册为 metax-tech.com/sgpu 资源。
如果集群内所有沐曦GPU都需要启用GPU共享功能,可以在安装时启用 sGPUHybridMode 参数,参见表 3.2 gpu-device Options。
如果集群内存在 metax-tech.com/gpu 和 metax-tech.com/sgpu 资源混合部署的场景,可以按照以下方式配置。目前仅支持在未开启 sGPUHybridMode 选项时设置。
注意配置模式前,需要确保节点上没有业务运行。
设置gpu-device运行模式
通过修改名为
metax-device-config的ConfigMap,可以配置集群级别和节点级别的gpu-device的运行模式。节点级别的配置优先级更高,即同时存在集群级别和节点级别的配置,最终生效的是节点的配置。如果节点配置不存在,会使用集群配置。如果上述配置都不存在,将会使用默认配置。
假设集群存在
sample-node1和sample-node2两个节点,sample-node1节点需要以sGPU模式运行,sample-node2节点需要以Native模式运行。 可以新建名为 metax-device-config.yaml 的配置文件,写入如下内容:apiVersion: v1 kind: ConfigMap metadata: name: metax-device-config data: version: v1 cluster-config: | mode: "native" nodes-config: | - nodeName: "sample-node1" mode: "sgpu"
通过以下命令使配置生效。配置文件的更新将在几分钟内在相关节点上生效。
kubectl apply -f metax-device-config.yaml -n metax-operator
生效后观察
sample-node1节点的可用metax-tech.com/sgpu资源。kubectl get node sample-node1 -o json | jq '.status.allocatable | with_entries(select(.key | startswith("metax-tech.com/sgpu")))'
示例输出:
{ "metax-tech.com/sgpu": "16" }
生效后观察
sample-node2节点的可用metax-tech.com/gpu资源。kubectl get node sample-node2 -o json | jq '.status.allocatable | with_entries(select(.key | startswith("metax-tech.com/gpu")))'
示例输出:
{ "metax-tech.com/gpu": "1" }
配置参数参见下表。
表 4.4 device config 选项
类型
描述
cluster-config
map
集群级别gpu-device的配置
cluster-config.mode
enum
集群级别gpu-device的运行模式,默认为
native,可选sgpu、sharedcluster-config.shareNums
int32
在
shared模式下集群级别的实例超额分配数量,默认为4,最大为64。若配置值超过64,系统将自动截断为64。其他模式并无含义nodes-config
list
节点配置列表
nodes-config[].nodeName
string
节点名称
nodes-config[].mode
enum
节点级别gpu-device的运行模式,默认为
native,可选sgpu、sharednodes-config[].shareNums
int32
在
shared模式下节点级别的实例超额分配数量,默认为4,最大为64。若配置值超过64,系统将自动截断为64。其他模式并无含义
备注
该功能需要依赖container-runtime组件,请确认安装时已部署相应组件。
该功能需要配合HAMi调度器使用,请确认使用前已安装HAMi。
4.5. container-runtime
4.5.1. 简介
作为 GPU 资源与容器化应用的桥梁,负责在 Kubernetes 集群中实现 GPU 设备与容器的高效绑定, 支持私有环境下的容器运行时配置,确保 Pod 能够透明、安全地访问物理 GPU 或虚拟化 GPU 资源。
4.5.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.runtime,完整字段说明见 表 3.7 Container Runtime Options。
4.5.3. 组件功能
4.5.3.1. GPU基础资源自动注入
当调度 GPU 任务时,容器运行时会自动将 MXMACA® SDK 注入容器并配置相应环境变量,实现 GPU 资源与容器的无缝对接。
用户可在容器内的指定目录获取相关资源,典型路径如下:
MXMACA® SDK:部署路径为 /opt/maca-$version,同时提供
/opt/maca符号链接以简化访问;mxdriver 资源包:存放于 /opt/mxdriver,默认集成
mx-smi等工具。
重要
若要启用私有运行时环境,运行时Pod会自动修改宿主机上的高级容器运行时配置。请确保这些配置项处于正常状态,避免影响运行时功能。
4.6. driver
4.6.1. 简介
提供 GPU 内核驱动与固件的全生命周期管理,支持安装、升级、卸载、灰度发布及固件升级,保障驱动与集群环境的兼容性和稳定性。
支持多驱动部署策略:PreferCloud、PreferHost等,参见 表 3.5 Driver Deploy Policy Options
内置灰度升级控制器,通过 upgradePolicy 配置分批次升级
支持驱动固件升级策略与虚拟化固件配置
兼容多种 GPU 资源形态,支持 Native GPU 和 sGPU,适配 VFIO-PCI 驱动模式
4.6.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.driver,完整字段说明见 表 3.4 Kernel Module Control Options。
4.6.3. 组件功能
4.6.3.1. 内核驱动配置
MetaX GPU支持开启虚拟化,开启虚拟化需确保环境已完成如下配置:
BIOS 开启 SRIOV
操作系统开启 IOMMU
安装带
-VF后缀的VBIOS固件
通过 ConfigMap 资源控制工作节点的 GPU 虚拟化行为,包括 SR-IOV 虚拟化 和 VFIO-PCI 驱动绑定。
driver config v1
GPU Operator 使用 driver-config 和 metax-vfio-config 两个 ConfigMap 来控制驱动参数配置。
driver-config用于控制GPU虚拟化配置,如 VF 数量、内核参数metax-vfio-config控制 VFIO-PCI 驱动绑定的 GPU 设备
driver-config 的配置说明
参数 |
类型 |
描述 |
|---|---|---|
|
integer |
全局内核参数:xcore 页大小配置 |
|
integer |
节点级内核参数:目标节点 xcore 页大小( |
|
string |
目标节点名( |
|
integer |
节点上每张 GPU 的 VF 实例数量 |
metax-vfio-config 的配置说明
参数 |
类型 |
描述 |
|---|---|---|
|
string |
目标节点名(支持正则表达式) |
|
string |
GPU 序号列表(支持逗号分隔、 |
示例: 配置driver-config
kind: ConfigMap
metadata:
name: driver-config
data:
module-params: |
xcore_page_size: 10 # 集群级配置:所有节点 xcore 页大小设为 10
node-module-params: |
sample-node1:
xcore_page_size: 12 # 节点级配置:sample-node1 页大小设为 12
node-vfnums: |
nodes:
sample-node: # sample-node 每张 GPU 虚拟为 4 个 VF
vfnum: 4
sample-node2: # sample-node2 每张 GPU 虚拟为 2 个 VF
vfnum: 2
配置生效后,节点资源将动态调整:
metax-tech.com/gpu资源总数 = \(N_\mathrm(gpu) \times M_\mathrm(vfnum)\)节点内核参数
/sys/module/metax/parameters/xcore_page_size按配置生效
期间,以
metax-gpu-device开头的 Pod 将自动重建,属于正常现象
示例: 配置metax-vfio-config
kind: ConfigMap
metadata:
name: metax-vfio-config
data:
vfio: |
- nodeName: sample-node0 # 节点 sample-node0 的前 3 个 GPU 绑定 VFIO-PCI
gpus: "0,1,2"
- nodeName: worker-node\d+ # 正则匹配节点:前缀为 worker-node 的节点,前 3 个 GPU 绑定 VFIO-PCI
gpus: "0,1,2"
若配置无效 GPU 序号,系统将自动忽略
metax-tech.com/vfio-gpu资源数等于绑定的 GPU 数量
备注
内核参数优先级:节点级参数(
node-module-params)会覆盖集群级参数(module-params)vfio-manager 变更:从
0.11.0版本起,vfio-manager组件弃用,相关配置迁移至driver.vfioConfig
[推荐] driver config v2
GPU Operator 0.11.0 版本引入 driver config v2,支持 单 GPU 粒度的虚拟化与驱动绑定配置,相比 v1 具备更细粒度的控制能力
driver-config 的配置说明
选项 |
类型 |
描述 |
|---|---|---|
|
map |
集群级内核参数(当前仅支持 |
|
list |
节点配置列表 |
|
string |
节点名(支持逗号分隔或正则表达式) |
|
integer |
单 GPU 虚拟化实例数(开启虚拟化时生效) |
|
string |
开启虚拟化的 GPU 列表(支持序号、BDF 号、 |
|
string |
绑定至 VFIO-PCI 驱动的 GPU 列表(支持序号、BDF 号、 |
|
map |
节点级内核参数(覆盖集群级配置) |
备注
virtGPUs需与vfNum配合使用,未指定时默认对所有 GPU 生效GPU 序号按 BDF 字典序排序,支持使用
-指定范围。例如0-2无效配置(如不存在的节点/GPU)将被自动忽略
gpu_model参数配置时,不能和gpu-device组件的mode配置冲突,0.11.2版本后不推荐设置该参数
初始化与配置方式
集群初始化
优先级:
--set-file﹥ 修改 values.yaml通过
--set-file配置,仅当 v1 配置为空时 v2 生效:# 使用 --set-file 方式 helm install metax-operator --generate-name --set-file driver.driverConfigFile=driver_config_v2.yaml
修改 values.yaml:
# values.yaml 配置示例 driver: driverConfig: nodesConfig: - nodeName: ubuntu-node-1 vfNum: 2 vfioGPUs: "all" moduleParams: gpu_model: 1
运行时修改
kubectl edit cm driver-config
在
data.nodes-config中直接修改配置,并确保data.version: v2v1 到 v2 切换
初始化时:通过
--set清空 v1 配置(如driver.vfnumsConfig=null)运行时:手动修改
data.version为v2,并迁移 v1 配置至nodes-config
4.6.3.2. 内核驱动灰度发布
GPU Operator 提供分批次灰度升级机制,支持灵活控制升级节奏与回滚策略。管理员可按照如下示例学习如何配置驱动灰度发布:
配置灰度策略
配置
enableRollout为true,设置每批次升级参数。upgradeSteps用于设置每批次升级参数。replicas表示该升级批次完成后Pod为新版本的副本数量,在使用百分号时,系统会确保至少有一个Pod会被升级。假定集群有10个工作节点,系统按照如下配置驱动灰度发布:
第一次升级副本数量为2,最大并行升级参数为50%,实际最大并行升级节点数量为
1=max(1,ROUNDUP(50%*2)),系统将会经历两次循环,每次升级一个节点,升级完成后系统进入暂停状态,管理员需要手动触发下一批次升级。第二次和第三次升级副本数量均为3,最大并行升级参数为50%,实际最大并行升级节点数量为
2=max(1,ROUNDUP(50%*3)),系统将会经历两次循环,第一次会升级两个节点,第二次升级一个节点,升级完成后系统会自动超时等待10s,在此期间管理员可以检查升级情况,可以设置升级暂停,若没有任何操作,系统将会在10s后自行进入下一批次升级。第四次升级
replicas设置为 100%,确保所有的Pod均升级到新版本,实际升级的副本数量为2,升级完成后系统进入暂停状态,管理员需要手动确认本次升级完成。
# 编辑cr kubectl edit clusteroperators.gpu.metax-tech.com cluster-operator # 编辑灰度发布策略 driver: upgradePolicy: enableRollout: true upgradeSteps: - replicas: 2 pauseDuration: - replicas: 5 pauseDuration: 10000 - replicas: 8 pauseDuration: 10000 - replicas: 100% pauseDuration: pause: false maxParallel: 50% maxUnavailable: 0 maxFailureThreshold: 3 fallback: pause
动态调整策略
仅支持修改“灰度发布策略开关”和“暂停状态”:
# 强制回滚 kubectl patch clusteroperators.gpu.metax-tech.com clusteroperator type=json -p '[{"op": "replace","path":"/driver/upgradePolicy/enableRollout","value": "false"}]' # 暂停升级 kubectl patch clusteroperators.gpu.metax-tech.com clusteroperator type=json -p '[{"op": "replace", "path": "/driver/upgradePolicy/pause","value": "false"}]' # 恢复升级 kubectl patch clusteroperators.gpu.metax-tech.com clusteroperator type=json -p '[{"op": "replace","path": "/driver/upgradePolicy/pause","value": "true"}]'
查看升级状态
kubectl get clusteroperators.gpu.metax-tech.com cluster-operator -o jsonpath={.status.upgradeStatus}
status: upgradeStatus: lastAppliedSpec: lastCoDriverSpec: upgrading: condition: - type: status: lastTransitionTime: reason: message: phase: message: status: lastPodSpecRevision: upgradingPodSpecRevision: currentStepIndex: currentUpgradeReplicas: currentUpgradeReadyReplicas: currentFailureRetry: currentStepState: totalUpgradeReplicas: totalUpgradeReadyReplicas: lastUpdateTime: message: recheckTime:
灰度升级状态参数介绍,参见下表:
表 4.5 Driver Upgrade Status 选项
类型
描述
lastAppliedSpec
string
升级前
metax-driverDaemonSet配置lastCoDriverSpec
string
升级前
metax-driverClusterOperator中的spec.driver配置upgrading
bool
标识KMD灰度升级是否运行
condition[].type
enum
升级状况的类型,可选
Progressing,Succeed,Failed,Terminatingcondition[].status
string
升级状况是否适用,可选
True,False,Unknowncondition[].lastTransitionTime
time
灰度发布上次从一种状态切换到另一种状态的时间戳
condition[].reason
string
机器可读的,驼峰编码的(UpperCamelCase)的文字,表述上次状况变化的原因
condition[].message
string
人类可读的消息,给出上次状态(包括灰度发布升级阶段和批次升级)转换的详细信息
phase
enum
灰度发布升级阶段,可选
Idling,Progressing,Terminating,Disabled,Disablingmessage
string
人类可读的消息,给出上次灰度发布升级状态转换的详细信息
status.lastPodSpecRevision
string
升级前Pod的Spec版本号
status.upgradingPodSpecRevision
string
升级后Pod的Spec版本号
status.currentStepIndex
integer
当前批次升级索引,表明当前为第几次升级
status.currentUpgradeReplicas
integer
当前批次升级副本数量
status.currentUpgradeReadyReplicas
integer
当前批次升级成功的副本数量
status.currentFailureRetry
integer
当前批次升级失败次数
status.currentStepState
enum
当前批次状态,,可选
StepUpgradeInit,StepUpgrade,StepPaused,StepReady,Completedstatus.message
string
人类可读的消息,给出升级批次转换的详细信息
status.totalUpgradeReplicas
integer
本次升级总副本数量
status.totalUpgradeReadyReplicas
integer
本次升级成功的副本数量
status.lastUpdateTime
time
状态更新的时间戳
status.recheckTime
time
系统自动进入下一升级阶段的时间戳
备注
提交灰度升级策略并且开启
enableRollout时,系统会通过validating-admission-webhook校验参数,参数异常时会返回失败。执行灰度升级时,集群必须处于离线状态,无运行中的任务。
4.6.3.3. 固件升级
用户可以通过配置固件升级参数来升级GPU设备上的固件。
配置固件升级策略
管理员可配置
driver.fwUpgradePolicy为PreferCloud以使用payload镜像中的固件来升级。目前支持以下参数配置:
表 4.6 Driver Firmware Upgrade Options 选项
描述
PreferCloud
使用payload镜像中的固件升级
Never
禁用固件升级
表 4.7 Driver Firmware Virt Options 选项
描述
true
使用虚拟化版本固件
false
使用非虚拟化版本固件
升级流程
配置生效后,driver-manager 会自动执行固件升级
升级完成后,节点上报
NodeNeedReboot事件,需重启服务器使固件生效:$ kubectl get event LAST SEEN TYPE reason OBJECT message 9s Normal NodeNeedReboot node/sample-node1 firmware upgrade done, need reboot machine to take effect
重启后通过
mx-smi验证固件版本
关闭固件升级
管理员可配置 driver.fwUpgradePolicy 为 Never 来关闭固件升级功能。
备注
固件升级功能只支持在物理机环境上运行,且只支持PF的固件升级
使用固件升级功能要求当前服务器上所有GPU设备的VBIOS版本不跨1.12.0.0版本,即都小于1.12.0.0版本或者都大于等于1.12.0.0版本。建议当前所有GPU设备版本不小于1.12.0.0版本
不支持在固件升级过程中修改固件升级参数
目前固件升级不支持多机互联场景
目前不支持从非虚拟化版本固件升级到虚拟化版本固件,原因是虚拟化版本固件对服务器有较高要求,需要用户手动确认当前服务器型号能否支持虚拟化固件
4.7. maca
4.7.1. 简介
提供对 MXMACA® SDK 的全生命周期管理能力。
支持多版本 MXMACA® SDK 管理,实现资源版本灵活切换与共存
4.7.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.maca,完整字段说明见 表 3.6 MXMACA Control Options。
4.7.3. 组件功能
4.7.3.1. MXMACA® 资源管理
系统通过 Custom Resource (CR) 中的 maca.payload.images 字段,定义需在节点上部署的 MXMACA® 资源版本。
kubectl edit clusteroperators.gpu.metax-tech.com cluster-operator
# CR
spec:
maca:
payload:
images:
- maca-native:3.2.1.4-ubuntu20.04-amd64
- maca-c500:2.33.0.6-ubuntu20.04-amd64
自动更新机制:配置保存后,maca Pod 将自动重启并开始部署指定版本 MXMACA® SDK
版本优先级:节点默认挂载最新版本 MXMACA® SDK
就绪状态:资源部署完成后,节点将自动添加标签
metax-tech.com/maca.ready: true,标志 MXMACA® SDK 可用
4.7.3.2. GPU运行任务指定 MXMACA® SDK 版本
GPU Operator 提供了运行GPU任务配置自定义 MXMACA® SDK 版本的能力。
配置方法:在任务 YAML 的容器参数中添加环境变量 METAX_MACA_VERSION,示例如下:
apiVersion: v1
kind: Pod
metadata:
name: gpu-task-pod
spec:
containers:
- name: container-1
image: ubuntu:20.04
command: ["bash", "-c", "sleep infinity"]
env:
- name: METAX_MACA_VERSION
value: "maca-2.31.0.4" # 指定低版本
resources:
limits:
metax-tech.com/gpu: 1 # 申请 GPU 资源
版本校验:若节点未提前部署指定版本资源,Pod 将因依赖缺失而启动失败并报错
4.8. mx-exporter
4.8.1. 简介
采集 GPU 设备的关键指标(如利用率、温度、固件版本等),并通过标准化接口将指标数据对外暴露,支持与 Prometheus 等监控系统集成,为集群资源管理与故障诊断提供数据支撑。
兼容 Prometheus 协议,提供 /metrics 接口供监控系统周期性拉取指标数据
支持自定义服务配置,包括服务类型(如 NodePort、LoadBalancer)和端口号(默认端口为 8000)
支持动态扩展指标采集范围,适配不同型号 GPU 设备的硬件特性
4.8.2. 配置介绍
组件配置可通过修改 Helm 安装参数或自定义资源清单实现,具体配置项参见 表 3.11 Data Exporter Options。
4.8.3. 组件功能
4.8.3.1. 监控指标
以下是当前支持的核心监控指标,完整列表参见《曦云系列通用GPU mx-exporter使用手册》,文档获取方法参见 5.1.1 文档获取。
指标名称 |
所属类别 |
指标说明 |
|---|---|---|
mx_chip_hotspot_temp |
Temperature |
芯片内部最高温度,单位为摄氏度(°C) |
mx_board_core_temp |
Temperature |
板卡核心温度,单位为摄氏度(°C) |
mx_optical_module_temp |
Temperature |
光模块温度(仅部分设备如 C500X 支持),单位为摄氏度(°C) |
mx_vpue_usage |
Usage |
编码器利用率,反映视频编码单元的负载情况 |
mx_vpud_usage |
Usage |
解码器利用率,反映视频解码单元的负载情况 |
mx_memory_usage |
Usage |
HBM 及系统内存利用率,通过标签 type 区分:vram 代表 HBM,xtt 代表系统内存 |
mx_memory_total |
Usage |
HBM 及系统内存总量,单位为 KB,标签 type 含义同上 |
mx_memory_used |
Usage |
HBM 及系统内存已使用量,单位为 KB,标签 type 含义同上 |
mx_memory_free |
Usage |
HBM 及系统内存剩余量,单位为 KB,标签 type 含义同上(原始表格未列出,根据上下文补充) |
mx_gpu_usage |
Usage |
GPU 核心利用率,反映计算单元的整体负载 |
mx_board_power |
Power |
板卡功耗,单位为毫瓦(mW) |
mx_vpue_clock |
Clock |
编码器时钟频率,单位为 MHz |
mx_vpud_clock |
Clock |
解码器时钟频率,单位为 MHz |
mx_mem_clock |
Clock |
HBM 时钟频率,单位为 MHz |
mx_gpu_clock |
Clock |
GPU 核心时钟频率,单位为 MHz |
mx_pcie_bw |
PCIE |
PCIe 接口的 Tx(发送)和 Rx(接收)吞吐量,单位为 MB/s |
mx_pcie_speed |
PCIE |
设备每条 lane 上的 PCIe 传输速率,单位为 GT/s |
mx_pcie_width |
PCIE |
设备支持的 PCIe lanes 数量,反映接口带宽能力 |
mx_pcie_bridge_speed |
PCIE |
PCIe bridge 传输速率,单位为 GT/s(用于多 GPU 节点的桥接通信) |
mx_pcie_bridge_width |
PCIE |
PCIe bridge 支持的 lanes 数量,单位为条 |
mx_mxlk_bw |
MetaXLink |
MetaXLink 接口的 Tx 和 Rx 吞吐量,单位为 MB/s(用于 GPU 间高速互联) |
mx_mxlk_speed |
MetaXLink |
MetaXLink 实时传输速率,单位为 GT/s |
mx_mxlk_width |
MetaXLink |
MetaXLink 接口的 lanes 数量,反映互联带宽能力 |
mx_xcore_dpm_level |
DPM |
当前动态电源管理(DPM)等级,影响 GPU 功耗与性能平衡 |
mx_kernel_error |
Log |
Kernel 日志中级别为 Error 的信息计数,用于故障定位 |
mx_gpu_state |
Status |
设备状态: |
mx_clk_thr |
Clocks Throttle Reasons |
当前降频原因(二进制编码),例如 |
mx_sgpu_compute_quota |
SGPU Usage |
分给子设备的算力配额(占父设备百分比,%),仅当开启 sGPU 且配置文件启用该指标时收集 |
mx_sgpu_usage |
SGPU Usage |
子设备的实际使用率(%),同上条件 |
mx_sgpu_total_memory |
SGPU Usage |
分给子设备的 HBM 总量(KB),同上条件 |
mx_sgpu_used_memory |
SGPU Usage |
子设备已使用的 HBM 量(KB),同上条件 |
mx_sgpu_free_memory |
SGPU Usage |
子设备剩余的 HBM 量(KB),同上条件 |
mx_mxlk_aer_count |
MetaXLink |
MetaXLink AER 错误计数,区分 UE(不可恢复错误)和 CE(可纠正错误) |
mx_mxlk_traffic_total_bytes |
MetaXLink |
MetaXLink 累计传输数据量,单位为 Byte |
mx_server_info |
UUID |
服务器 UUID, |
4.8.3.2. 对外服务
系统通过 Kubernetes 的 Service 资源对外提供服务,默认创建名为 metax-data-exporter 的 Service,其中:
默认端口:
8000(指标数据通过metric端口暴露)配置调整:如需修改端口,可通过以下步骤操作:
编辑 Service 资源:
kubectl edit service metax-data-exporter -n metax-operator修改
spec.ports下name: metric对应的targetPort和port字段,保存后生效
通过以上配置,用户可根据集群网络架构(如节点端口映射、负载均衡器)访问 /metrics 接口,实现 GPU 指标的实时监控与分析。
4.9. topoDiscovery
4.9.1. 简介
topoDiscovery 组件用于自动发现 Kubernetes 集群内节点的拓扑关系(如 Dragonfly/Switchbox 架构), 并通过节点标签动态呈现拓扑分组信息,为 GPU 任务调度提供拓扑感知能力,优化多节点通信效率。
多架构支持:兼容三种拓扑发现模式(config/dragonfly/switchbox),适配不同硬件架构
动态标签生成:根据拓扑结构自动为节点添加层级标签(如 metax-tech.com/topology.nodegroup-*)
配置优先级管理:支持通过 ConfigMap 手动配置拓扑(优先级高于自动发现)
4.9.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.topoDiscovery,完整字段说明参见 表 3.13 Topo Discovery Options。
安装参数:
通过
--set topoDiscovery.enabled=true启用组件,需同时指定模式(如--set topoDiscovery.mode=config)ConfigMap 配置:
手动配置拓扑时,修改名为 metax-topo-master-config 的 ConfigMap,支持多层级分组定义
4.9.3. 组件功能
4.9.3.1. config模式
config模式适用于集群拓扑无法自动发现的场景。
配置方法
# 通过 Helm 开启 config 模式
helm install ... --set topoDiscovery.mode=config
拓扑组件部署到集群上后,会生成一个名为 topo-master-config 的 ConfigMap。该 ConfigMap 支持多层级的拓扑配置。
用户可以通过修改其内容控制集群节点的拓扑分组信息。配置时需要注意以下事项:
同层级节点的
kind需要一致且child下的节点数量需要相同,name需要非空且唯一最底层节点的
kind必须是node类型,且节点需在集群中存在
1{ 2 "nodegroup": " 3 group: 4 - name: switchbox-1 5 kind: switchbox 6 child: 7 - name: dragonfly-1 8 kind: dragonfly 9 child: 10 - name: sample-node1 11 kind: node 12 - name: sample-node2 13 kind: node 14 - name: dragonfly-2 15 kind: dragonfly 16 child: 17 - name: sample-node3 18 kind: node 19 - name: sample-node4 20 kind: node 21 - name: switchbox-2 22 kind: switchbox 23 child: 24 - name: dragonfly-3 25 kind: dragonfly 26 child: 27 - name: sample-node5 28 kind: node 29 - name: sample-node6 30 kind: node 31 - name: dragonfly-4 32 kind: dragonfly 33 child: 34 - name: sample-node7 35 kind: node 36 - name: sample-node8 37 kind: node 38 " 39}
以上示例中 [line 3-37] 所示内容为节点分组配置。
根据 ConfigMap 传递到工作节点所需的时间不同,管理员可在几分钟内观测到节点分组标签如下表所示。
节点 |
标签 |
|---|---|
sample-node1 |
|
sample-node2 |
|
sample-node3 |
|
sample-node4 |
|
sample-node5 |
|
sample-node6 |
|
sample-node7 |
|
sample-node8 |
|
4.9.3.2. dragonfly模式
dragonfly模式用于dragonfly架构下的拓扑发现。在安装GPU Extensions时通过配置 --set topoDiscovery.mode=dragonfly 开启。
若开启了拓扑发现功能,可以通过以下接口验证拓扑识别状态是否正常。
TOPO_MASTER_IP=`kubectl get pod -n metax-gpu -owide | grep topo-master | awk {'print $6'}`
curl $TOPO_MASTER_IP:9001/cluster_status
例如在两节点为一组的拓扑集群中,则可看到以下内容:
{
"status": "ready",
"total_node": 2,
"gpu_node": 2,
"ready_node": 2,
"node_group_number": 2
}
参数含义,参见下表:
选项 |
类型 |
描述 |
|---|---|---|
status |
string |
表示集群拓扑发现状态, |
total_node |
integer |
集群中所有节点的数量 |
gpu_node |
integer |
集群中GPU节点的数量 |
ready_node |
integer |
已完成拓扑发现的节点数量 |
node_group_number |
integer |
一个节点组中节点的数量 |
备注
集群内的所有GPU节点必须都满足dragonfly拓扑,否则 gpu_node 的数量可能和 ready_node 不相等,导致 status 的值一直为 training。
dragonfly模式下同时也支持通过 ConfigMap 方式配置集群拓扑,通过 ConfigMap 配置的集群拓扑具有更高的优先级。配置方式参见 6.1.6.1 config模式。
4.9.3.3. switchbox模式
switchbox模式用于switchbox架构下的拓扑发现。在安装GPU Extensions时通过配置 --set topoDiscovery.mode=switchbox 开启。
注意安装时需要配置cluster manager的地址和用户密码,否则拓扑组件无法正常工作。
可以通过以下接口查询拓扑的分组信息是否和物理拓扑一致。
TOPO_MASTER_IP=`kubectl get pod -n metax-gpu -owide | grep topo-master | awk {'print $6'}`
curl $TOPO_MASTER_IP:9001/node_group
例如在拓扑为两节点组成一个dragonfly组,两个dragonfly节点组成一个switchbox组的集群中,则可看到以下内容。
[
{
"name": "switchbox-sample1",
"kind": "switchbox",
"child": [
{
"name": "dragonfly-sample1",
"kind": "dragonfly",
"child": [
{
"name": "node-sample1",
"kind": "node",
"status": "Ready"
},
{
"name": "node-sample2",
"kind": "node",
"status": "Ready"
}
],
"status": "Ready"
},
{
"name": "dragonfly-sample2",
"kind": "dragonfly",
"child": [
{
"name": "node-sample3",
"kind": "node",
"status": "Ready"
},
{
"name": "node-sample4",
"kind": "node",
"status": "Ready"
}
],
"status": "Ready"
}
],
"status": "Ready"
}
]
参数含义,参见下表
选项 |
类型 |
描述 |
|---|---|---|
name |
string |
节点组的名称 |
kind |
string |
节点组的类型 |
child |
array |
子节点组的信息 |
status |
string |
节点组状态, |
备注
当拓扑组件检测到cluster manager组件上报告警后,拓扑组件会在集群中上报
SuperNodeAbnormal事件在switchbox重启或异常时,cluster manager组件会上报告警。当拓扑组件检测到告警时,会把对应的switchbox节点组设置为
NotReady状态,当告警消失时switchbox节点组恢复为Ready状态在GPU服务器异常或者GPU链路出现异常时,cluster manager组件会上报告警。当拓扑组件检测到告警时,会把对应的节点设置为
NotReady状态,当告警消失且链路状态恢复正常后节点恢复为Ready状态
4.10. gpu-scheduler
4.10.1. 简介
gpu-scheduler 是为 Kubernetes 集群设计的 GPU 资源调度解决方案。
基于原生 kube-scheduler 扩展,通过 Extender 模式插件(gpu-aware) 实现 GPU 资源的精细化调度,解决GPU资源无法参与调度的问题,确保 GPU 任务高效、均衡地部署到集群节点。
基于 Extender 模式扩展原生调度器,提供标准 HTTP 接口(默认端口 8080)
支持 GPU 资源过滤与优先级排序,适配 MetaX GPU 型号、虚拟化实例及固件版本
提供多维度调度权重配置:通信效率权重(weight.score)与资源碎片化权重(weight.loss)
支持通过 ConfigMap 动态更新调度策略,配置变更分钟级生效
需集群 Admin 权限独立部署,与 GPU Operator 核心组件解耦
4.10.2. 配置介绍
配置项位于 ClusterOperator CR 中的 spec.gpuScheduler,完整字段说明见 表 3.18 GPU Scheduler Options。
Helm 部署参数
关键参数:
gpuScheduler.deploy=true(启用调度器)组件配置:仅允许通过 Helm 修改
kube-scheduler.image和gpu-aware.image版本,其他配置需直接修改 Chart 模板
ConfigMap 配置
主配置文件:
metax-gpu-scheduler-config,包含原生调度器配置(如leaderElection、profiles)和 Extender 插件参数(如 URL、TLS 配置)权重参数:
weight.score:通信分数权重(数值越大,越倾向通信高效节点)weight.loss:资源损失权重(数值越大,越规避碎片化节点)
4.10.3. 组件功能
4.10.3.1. 资源调度
由 kube-scheduler(原生调度器) 和 gpu-aware(GPU 扩展插件) 双组件协同实现 GPU 资源调度全流程:
kube-scheduler(原生调度器)
作为底层调度引擎,负责执行 Kubernetes 原生调度逻辑(如节点亲和性、资源配额、Pod 反亲和),并通过 Extender 接口将 GPU 资源的专属调度逻辑委托给 gpu-aware 插件。
核心职责:
接收 Pod 调度请求,执行原生过滤规则(如节点资源充足性、标签选择器)
调用 gpu-aware 插件完成 GPU 资源过滤与优先级计算
最终绑定 Pod 到目标节点
gpu-aware(GPU 扩展插件)
作为 GPU 资源调度的 “大脑”,通过标准 HTTP 接口与 kube-scheduler 交互,提供 GPU 专属调度逻辑:
资源过滤(Filter):
根据任务需求及节点 GPU 属性,筛选出符合条件的候选节点
优先级排序(Prioritize):
基于 ConfigMap 中配置的权重参数(weight.score 和 weight.loss),计算节点分数:
通信效率分数:评估任务与节点间的网络延迟,分数越高越优先(weight.score 越大,该因素权重越高)
资源碎片化分数:评估节点 GPU 资源分配后的碎片程度,分数越高越优先(weight.loss 越大,越规避碎片化)
最终返回节点优先级列表,供 kube-scheduler 决策
4.10.3.2. 安装与使用说明
安装(与其他组件的差异点)
权限要求:需集群 Admin 权限(Operator 因权限不足无法管理),确保调度器能访问集群所有节点与资源
部署方式:作为 GPU Operator 组件之一,通过 Helm 一键部署,仅需启用
gpuScheduler.deploy=true参数:helm install oci://DOMAIN/PROJECT/metax-operator \ --create-namespace -n metax-operator \ --generate-name \ --wait \ --set registry=DOMAIN/PROJECT \ --set gpuScheduler.deploy=true # 启用 gpu-scheduler
使用流程
任务提交
用户提交 GPU 任务(如训练作业、推理服务),需在 Pod 中声明 metax-tech.com/gpu 资源。
原生调度过滤
kube-scheduler 执行原生规则(如节点标签、资源配额),筛选候选节点。
GPU 资源过滤
kube-scheduler 调用 gpu-aware 插件,根据任务 GPU 需求(如版本、数量)及节点 GPU 状态(如可用 VF 数、固件版本)进一步过滤节点。
优先级排序
gpu-aware 插件计算节点分数(通信效率 + 资源碎片化),返回优先级列表。
完成调度
kube-scheduler 根据优先级绑定 Pod 到目标节点,任务启动并使用对应 GPU 资源。
4.10.3.3. 对外服务能力
标准 Extender 接口:提供 filter 和 prioritize 接口(默认 8080 端口),支持与其他调度器(如自定义调度器)集成,扩展集群调度能力。
资源管理声明:显式管理 metax-tech.com/gpu 资源,避免与其他资源调度逻辑冲突。
备注
配置更新:
修改 metax-gpu-scheduler-configConfigMap 后,配置将在 5-10 分钟内自动同步至所有节点,无需重启组件卸载方式:仅支持通过卸载 GPU Operator 整体移除,确保调度策略与集群状态一致
兼容性:需提前部署 GPU Operator 的驱动管理(driver)和资源管理(maca)组件,确保 GPU 资源状态可被正确识别