6. 附录:GPU Extensions
GPU Extensions 是沐曦提供的基础云上GPU管理方案。 GPU Operator 提供了MinimalMode,该模式实现了 GPU Extensions 功能。
推荐使用 GPU Operator 的 MinimalMode,参见 3.3 MinimalMode
重要
在Kubernetes集群上配置 GPU Extensions 前,应确认环境满足如下条件:
Kubernetes版本 ≥ 1.23 。
管理节点以及工作节点应允许创建特权容器 [1] 。
工作节点已正确安装 MXMACA® 内核态驱动。安装步骤参见《曦云系列通用GPU用户指南》相关章节。
6.1. 部署参考
GPU Extensions 提供Helm Chart形式的安装包,关于Helm Chart安装包使用前的准备工作,参见 3.1.3 安装步骤。
6.1.1. 安装 GPU Extensions
在Kubernetes管理节点执行以下命令,即可完成 GPU Extensions 的安装:
helm install oci://DOMAIN/PROJECT/metax-gpu-extensions \
--create-namespace -n metax-gpu \
--generate-name \
--wait \
--set registry=DOMAIN/PROJECT
6.1.2. 设置Chart选项
GPU Extensions Chart安装时可通过 --set option=value 的方式改变选项默认设置。
对于结构体类型选项,配置其成员选项时使用 . 字符连接。
例如,指定 --set gpuLabel.log.format=text 参数,设置gpu-label组件使用 text 日志格式。
更多选项,参见下方表格。
选项 |
类型 |
描述 |
|---|---|---|
registry |
string |
组件容器镜像仓库,默认为 |
pullPolicy |
enum |
镜像拉取策略,默认为 |
deployExtenderGPUAware |
bool |
是否部署基于SchedulerExtender为GPU调度场景设计的调度拓展,默认为 |
log |
struct |
日志选项,参见表 6.8 |
gpuDevice |
struct |
gpu-device 组件选项,参见表 6.2 |
gpuLabel |
struct |
gpu-label 组件选项,参见表 6.3 |
gpuAware |
struct |
gpu-aware 组件选项,参见表 6.4 |
topoDiscovery |
struct |
topoDiscovery 组件选项,参见表 6.5 |
选项 |
类型 |
描述 |
|---|---|---|
healthyInterval |
integer |
GPU健康检查间隔的秒数,>0 时启用功能,=0 时禁用功能,默认值为5 |
connectDetectPeriod |
string |
和Kubelet组件的连接探测周期,>0s 时启用功能,=0s 时禁用功能,默认值为 0s。配置格式为时间周期,例如 10s 表示10秒,20m 表示20分钟。 |
log |
struct |
日志选项,参见表 6.8 |
选项 |
类型 |
描述 |
|---|---|---|
log |
struct |
日志选项,参见表 6.8 |
选项 |
类型 |
描述 |
|---|---|---|
scoreWeight |
string |
通信分数权重,该数值越大,任务调度倾向于通信效率高的节点 |
lossWeight |
string |
损失分数权重,该数值越大,任务调度倾向于对集群造成GPU资源碎片化更小的节点 |
选项 |
类型 |
描述 |
|---|---|---|
enabled |
bool |
是否启用拓扑发现组件,默认为 |
mode |
string |
拓扑组件的运行模式,默认为 |
dragonfly |
struct |
dragonfly模式选项,参见表 6.6 |
switchbox |
struct |
switchbox模式选项,参见表 6.7 |
选项 |
类型 |
描述 |
|---|---|---|
nodeNumber |
integer |
一个节点组中节点的数量,默认为 |
enableTraining |
bool |
是否开启节点自动Training功能,默认为 |
选项 |
类型 |
描述 |
|---|---|---|
clusterManagerAddress |
string |
cluster manager服务的地址,必填项 |
clusterManagerUser |
string |
登录cluster manager服务的用户名,需要使用base64编码,必填项 |
clusterManagerPassword |
string |
登录cluster manager服务的密码,需要使用base64编码,必填项 |
clusterManagerPollTopoPeriod |
int |
轮询cluster manager拓扑信息的时间间隔,单位为秒,默认为30秒 |
clusterManagerPollEventPeriod |
int |
轮询cluster manager告警事件的时间间隔,单位为秒,默认为10秒 |
选项 |
类型 |
描述 |
|---|---|---|
dir |
string |
日志文件存储目录,默认为 |
level |
enum |
日志级别,默认为 |
format |
enum |
日志格式,默认为 |
rotationTime |
string |
日志轮替时间,默认为 1w,可选单位为 |
maxAge |
string |
日志保存的最长时间,默认为 26w,可选单位为 |
6.1.3. 验证部署
在运行 helm install 命令并等待其正确退出后,可通过如下方式确认节点状态正确:
GPU资源数量正确
执行
kubectl describe node <NODE>检查工作节点上的metax-tech.com/gpu资源数量。1$ kubectl describe node <NODE> 2... 3Capacity: 4 cpu: 16 5 ephemeral-storage: 143245508Ki 6 hugepages-1Gi: 0 7 hugepages-2Mi: 0 8 memory: 16398052Ki 9 metax-tech.com/gpu: 4 10 pods: 110 11Allocatable: 12 cpu: 16 13 ephemeral-storage: 132015059955 14 hugepages-1Gi: 0 15 hugepages-2Mi: 0 16 memory: 16398052Ki 17 metax-tech.com/gpu: 4 18 pods: 110 19... 20Allocated resources: 21 (Total limits may be over 100 percent, i.e., overcommitted.) 22 Resource Requests Limits 23 -------- -------- ------ 24 cpu 100m (2%) 100m (2%) 25 memory 50Mi (0%) 50Mi (0%) 26 ephemeral-storage 0 (0%) 0 (0%) 27 hugepages-1Gi 0 (0%) 0 (0%) 28 hugepages-2Mi 0 (0%) 0 (0%) 29 metax-tech.com/gpu 0 0 30...
metax-tech.com/gpu资源数量有三处呈现,分别代表不同的涵义:Capacity为节点上沐曦GPU设备数量。未开启虚拟化时与GPU物理设备数量相等;节点开启虚拟化后,预期资源数量为 \(N_\mathrm(gpu) \times M_\mathrm(vfnum)\) 。
Allocatable为节点上健康资源数量。节点状态正常时与 Capacity 保持一致;当GPU发生故障时,故障GPU所对应的资源数量会在此字段做相应减除,而 Capacity 中仍然保持不变。
Allocated resources为当前已分配资源数量。
标签状态正确
执行
kubectl describe node <NODE>检查工作节点上metax-tech.com域下的标签状态。1$kubectl describe node <NODE> 2... 3Labels: beta.kubernetes.io/arch=amd64 4 ... 5 metax-tech.com/driver.ready=true 6 metax-tech.com/gpu.driver.major=2 7 metax-tech.com/gpu.driver.minor=0 8 metax-tech.com/gpu.driver.mode=native 9 metax-tech.com/gpu.driver.patch=0 10 metax-tech.com/gpu.family=MXC 11 metax-tech.com/gpu.installed=true 12 metax-tech.com/gpu.memory=64GB 13 metax-tech.com/gpu.product=C550 14 metax-tech.com/gpu.vfnum=0 15 ...
重点确认以下标签状态是否与实际情况相符:
metax-tech.com/gpu.installed=true表明节点上配置了沐曦GPU,若为false,则metax-tech.com域下其余标签状态可忽略。metax-tech.com/gpu.product表明节点上配置的沐曦GPU产品型号。metax-tech.com/gpu.vfnum表明节点上的虚拟化配置。未开启虚拟化时,值为 0;开启虚拟化后,根据不同产品的能力,可能为 1, 2, 4, 8 。
6.1.4. 卸载 GPU Extensions
如需卸载 GPU Extensions,可先通过 helm list -n metax-gpu 命令查询已安装的Chart,再执行 helm uninstall <CHART> -n metax-gpu --wait 命令进行卸载。
备注
-n 指定的参数为 namespace,应与安装时所指定的值保持一致。
也可直接运行以下脚本自动检查已安装的 GPU Extensions 并进行卸载。
chart=$(helm list -q -f "metax" -n metax-gpu)
if [[ -n $chart ]]; then
helm uninstall $chart -n metax-gpu --wait
fi
6.1.5. 启用 gpu-aware (可选)
如需启用 gpu-aware,应在安装GPU Extensions时手动添加配置 --set deployExtenderGPUAware=true。
建议安装前先阅读 6.2.5 gpu-aware。
6.1.5.1. 检查 gpu-aware 是否需要和三方调度器集成
使用以下命令检查调度器配置文件,根据启动参数中是否含有调度模板文件,判断是否需要和三方调度器集成,从而选择不同的安装方案。
1sudo cat /etc/kubernetes/manifests/kube-scheduler.yaml | grep -e "--config="
当返回值为空,不存在调度模板文件,操作步骤参见 6.1.5.2 启用gpu-aware组件,6.1.5.3 停用gpu-aware组件。
当返回值不为空,存在调度模板文件,操作步骤参见 6.1.5.4 gpu-aware与三方调度器集成,6.1.5.5 停止gpu-aware与三方调度器集成。
6.1.5.2. 启用gpu-aware组件
gpu-aware组件在初始化阶段,会收集集群版本、服务地址等信息,在每个管理节点生成带有自身配置信息的 调度模板文件 /etc/metax/extender.yaml 。
修改所有管理节点KubernetesScheduler的配置文件
/etc/kubernetes/manifests/kube-scheduler.yaml。将
调度模板文件通过KubernetesScheduler配置文件挂载到调度器容器内,并设为调度器启动参数,如以下高亮部分所示:1... 2spec: 3containers: 4 - command: 5 - kube-scheduler 6 - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf 7 - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf 8 - --config=/etc/metax/extender.yaml 9... 10 volumeMounts: 11 - mountPath: /etc/kubernetes/scheduler.conf 12 name: kubeconfig 13 readOnly: true 14 - mountPath: /etc/metax/extender.yaml 15 name: extenderconfig 16 readOnly: true 17 ... 18 volumes: 19 - hostPath: 20 path: /etc/kubernetes/scheduler.conf 21 type: FileOrCreate 22 name: kubeconfig 23 - hostPath: 24 path: /etc/metax/extender.yaml 25 type: File 26 name: extenderconfig
Kubelet 会感知到KubernetesScheduler配置文件内容的变化,重启KubernetesScheduler。配置生效,启用gpu-aware。
6.1.5.3. 停用gpu-aware组件
删除所有管理节点KubernetesScheduler配置文件
/etc/kubernetes/manifests/kube-scheduler.yaml中有关SchedulerExtender的内容,如以下高亮部分所示:1... 2spec: 3 containers: 4 - command: 5 - kube-scheduler 6 - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf 7 - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf 8 - --config=/etc/metax/extender.yaml 9... 10 volumeMounts: 11 - mountPath: /etc/kubernetes/scheduler.conf 12 name: kubeconfig 13 readOnly: true 14 - mountPath: /etc/metax/extender.yaml 15 name: extenderconfig 16 readOnly: true 17 ... 18 volumes: 19 - hostPath: 20 path: /etc/kubernetes/scheduler.conf 21 type: FileOrCreate 22 name: kubeconfig 23 - hostPath: 24 path: /etc/metax/extender.yaml 25 type: File 26 name: extenderconfig
删除操作完成后,配置文件
/etc/kubernetes/manifests/kube-scheduler.yaml如下所示。1... 2spec: 3 containers: 4 - command: 5 - kube-scheduler 6 - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf 7 - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf 8... 9 volumeMounts: 10 - mountPath: /etc/kubernetes/scheduler.conf 11 name: kubeconfig 12 readOnly: true 13 ... 14 volumes: 15 - hostPath: 16 path: /etc/kubernetes/scheduler.conf 17 type: FileOrCreate 18 name: kubeconfig
将所有管理节点的
/etc/kubernetes/manifests/kube-scheduler.yaml移出/etc/kubernetes/manifests,再移动回原位。Kubelet检测到
/etc/kubernetes/manifests/kube-scheduler.yaml文件缺失,会自动停止KubernetesScheduler任务。 再将文件移动至原位,Kubelet检测到/etc/kubernetes/manifests/kube-scheduler.yaml文件,会重载配置,启动KubernetesScheduler,停用gpu-aware成功。sudo mv /etc/kubernetes/manifests/kube-scheduler.yaml ./ sudo mv ./kube-scheduler.yaml /etc/kubernetes/manifests/
6.1.5.4. gpu-aware与三方调度器集成
在与其他三方调度器集成时,所有管理节点上的 调度模板文件 中,会记录已启动的三方调度拓展的配置信息。通过将gpu-aware配置信息加入调度模板文件,重启调度器,即可集成gpu-aware和三方调度器。
在 gpu-aware 组件生成的
调度模板文件中,获取gpu-aware调度拓展服务的配置信息,如以下高亮部分所示:1tail -n +5 /etc/metax/extender.yaml 2extenders: 3- urlPrefix: "http://<IP:PORT>" 4 enableHTTPS: false 5 filterVerb: "filter" 6 prioritizeVerb: "prioritize" 7 nodeCacheCapable: false 8 ignorable: false 9 weight: 500
配置信息如下表所示。
表 6.9 extenders Options 选项
类型
描述
extenders
array
需要调度模板文件,extender配置信息列表
urlPrefix
string
extender服务的URL信息
enableHTTPS
bool
是否采用HTTPS和extender服务通信
filterVerb
string
urlPrefix + filterVerb表示extender服务实现节点过滤功能的URL,如果不支持可以删除此条目
prioritizeVerb
string
urlPrefix + prioritizeVerb表示extender服务实现节点评分功能的URL,如果不支持可以删除此条目
nodeCacheCapable
bool
extender服务是否使用调度器缓存的节点状态信息
ignorable
bool
如果extender服务不可用,是否忽略
weight
int
extender服务的权重,用来与ScorePlugin计算出最终的分数
在所有管理节点找出三方调度器
调度模板文件的路径。sudo cat /etc/kubernetes/manifests/kube-scheduler.yaml | grep -e "--config=" | sed 's/^[^=]*=//'
通过在
/etc/kubernetes/manifests/kube-scheduler.yaml中查找上述文件的挂载信息,找到实际调度模板文件在宿主机的路径。在所有
调度模板文件extender配置区域添加 gpu-aware 组件的配置信息。在与三方调度拓展集成中,
节点评分=组件权重*组件节点评分+调度器节点评分,任务最终会被调度到分数最高的节点上。 从上述公式可以推导出,组件权重越大的调度拓展服务,对节点评分的影响越大,对调度结果影响越大。1apiVersion: kubescheduler.config.k8s.io/v1beta3 2kind: KubeSchedulerConfiguration 3clientConnection: 4 kubeconfig: "/etc/kubernetes/scheduler.conf" 5extenders: 6- urlPrefix: "http://<IP:PORT>" 7 enableHTTPS: false 8 filterVerb: "filter" 9 prioritizeVerb: "prioritize" 10 nodeCacheCapable: false 11 ignorable: false 12 weight: 500 13- urlPrefix: "http://<IP:PORT>" 14 enableHTTPS: false 15 filterVerb: "filter" 16 prioritizeVerb: "prioritize" 17 nodeCacheCapable: false 18 ignorable: false 19 weight: 500
将所有管理节点的
/etc/kubernetes/manifests/kube-scheduler.yaml移出/etc/kubernetes/manifests,再移动回原位。Kubelet检测到
/etc/kubernetes/manifests/kube-scheduler.yaml文件缺失,会自动停止KubernetesScheduler任务。 再将文件移动至原位,Kubelet检测到/etc/kubernetes/manifests/kube-scheduler.yaml文件,会重载配置,启动KubernetesScheduler,启用gpu-aware成功。sudo mv /etc/kubernetes/manifests/kube-scheduler.yaml ./ sudo mv ./kube-scheduler.yaml /etc/kubernetes/manifests/
6.1.5.5. 停止gpu-aware与三方调度器集成
在集群中存在 调度模板文件 的情况下,通过将gpu-aware配置信息自调度模板文件中移除,重启调度器加载配置,停用gpu-aware。
在管理节点收集 gpu-aware 组件的配置信息,如以下高亮部分所示:
1tail -n +5 /etc/metax/extender.yaml 2extenders: 3- urlPrefix: "http://<IP:PORT>" 4 enableHTTPS: false 5 filterVerb: "filter" 6 prioritizeVerb: "prioritize" 7 nodeCacheCapable: false 8 ignorable: false 9 weight: 500
配置信息含义,参见表 6.9。
在所有管理节点找出
调度模板文件的路径。sudo cat /etc/kubernetes/manifests/kube-scheduler.yaml | grep -e "--config=" | sed 's/^[^=]*=//'
通过在
/etc/kubernetes/manifests/kube-scheduler.yaml中查找上述文件的挂载信息,找到实际调度模板文件在宿主机的路径。在所有
调度模板文件extender配置区域删除 gpu-aware 组件的配置信息,如以下高亮部分所示:1apiVersion: kubescheduler.config.k8s.io/v1beta3 2kind: KubeSchedulerConfiguration 3clientConnection: 4 kubeconfig: "/etc/kubernetes/scheduler.conf" 5extenders: 6- urlPrefix: "http://<IP:PORT>" 7 enableHTTPS: false 8 filterVerb: "filter" 9 prioritizeVerb: "prioritize" 10 nodeCacheCapable: false 11 ignorable: false 12 weight: 500 13- urlPrefix: "http://<IP:PORT>" 14 enableHTTPS: false 15 filterVerb: "filter" 16 prioritizeVerb: "prioritize" 17 nodeCacheCapable: false 18 ignorable: false 19 weight: 500
删除操作完成后,
调度模板文件如下所示:1apiVersion: kubescheduler.config.k8s.io/v1beta3 2kind: KubeSchedulerConfiguration 3clientConnection: 4 kubeconfig: "/etc/kubernetes/scheduler.conf" 5extenders: 6- urlPrefix: "http://<IP:PORT>" 7 enableHTTPS: false 8 filterVerb: "filter" 9 prioritizeVerb: "prioritize" 10 nodeCacheCapable: false 11 ignorable: false 12 weight: 500
将所有管理节点的
/etc/kubernetes/manifests/kube-scheduler.yaml移出/etc/kubernetes/manifests,再移动回原位。Kubelet检测到
/etc/kubernetes/manifests/kube-scheduler.yaml文件缺失,会自动停止KubernetesScheduler任务。 再将文件移动至原位,Kubelet检测到/etc/kubernetes/manifests/kube-scheduler.yaml文件,会重载配置,启动KubernetesScheduler,停用gpu-aware成功。sudo mv /etc/kubernetes/manifests/kube-scheduler.yaml ./ sudo mv ./kube-scheduler.yaml /etc/kubernetes/manifests/
6.1.5.6. 修改调度策略
在gpu-aware组件中,调度策略由通信分数权重和损失分数权重决定。
权重控制着 gpu-aware 对调度节点的打分规则,通过权重影响节点评分,最终影响调度结果。用户可在管理节点执行以下命令修改调度策略:
组件内控制调度策略的权重,参见 6.2.5.2 gpu-aware权重。
kubectl edit configmap -n metax-gpu gpu-aware-weight
集群中控制组件和其他 extender 服务评分,参见表 6.9 extenders Options。
组件权重越大的调度拓展服务,对节点评分的影响越大,对调度结果影响越大。可以在
调度模板文件中修改,修改完成后需要重启KubeScheduler。
6.1.6. 启用topoDiscovery(可选)
如需使用topoDiscovery,应在安装GPU Extensions时手动添加配置 --set topoDiscovery.enabled=true,详情参见 6.1 部署参考。
topoDiscovery组件用于发现集群的拓扑关系,并以节点标签的方式在集群内呈现。有互联关系的一组节点均具有以 metax-tech.com/topology.nodegroup- 为前缀的标签。
topoDiscovery目前支持以下三种运行模式。
6.1.6.1. config模式
config模式适用于集群拓扑无法自动发现的场景,在安装GPU Extensions时通过配置 --set topoDiscovery.mode=config 开启。
拓扑组件部署到集群上后,会生成一个名为 topo-master-config 的 ConfigMap。该 ConfigMap 支持多层级的拓扑配置。
用户可以通过修改其内容控制集群节点的拓扑分组信息。配置时需要注意以下事项:
同层级节点的
kind需要一致且child下的节点数量需要相同,name需要非空且唯一。最底层节点的
kind必须是node类型,且节点需在集群中存在。
1{ 2 "nodegroup": " 3 group: 4 - name: switchbox-1 5 kind: switchbox 6 child: 7 - name: dragonfly-1 8 kind: dragonfly 9 child: 10 - name: sample-node1 11 kind: node 12 - name: sample-node2 13 kind: node 14 - name: dragonfly-2 15 kind: dragonfly 16 child: 17 - name: sample-node3 18 kind: node 19 - name: sample-node4 20 kind: node 21 - name: switchbox-2 22 kind: switchbox 23 child: 24 - name: dragonfly-3 25 kind: dragonfly 26 child: 27 - name: sample-node5 28 kind: node 29 - name: sample-node6 30 kind: node 31 - name: dragonfly-4 32 kind: dragonfly 33 child: 34 - name: sample-node7 35 kind: node 36 - name: sample-node8 37 kind: node 38 " 39}
以上示例中 [line 3-37] 所示内容为节点分组配置。
根据 ConfigMap 传递到工作节点所需的时间不同,管理员可在几分钟内观测到节点分组标签如下表所示。
节点 |
标签 |
|---|---|
sample-node1 |
|
sample-node2 |
|
sample-node3 |
|
sample-node4 |
|
sample-node5 |
|
sample-node6 |
|
sample-node7 |
|
sample-node8 |
|
6.1.6.2. dragonfly模式
dragonfly模式用于dragonfly架构下的拓扑发现。在安装GPU Extensions时通过配置 --set topoDiscovery.mode=dragonfly 开启。
若开启了拓扑发现功能,可以通过以下接口验证拓扑识别状态是否正常。
TOPO_MASTER_IP=`kubectl get pod -n metax-gpu -owide | grep topo-master | awk {'print $6'}`
curl $TOPO_MASTER_IP:9001/cluster_status
例如在两节点为一组的拓扑集群中,则可看到以下内容。
{
"status": "ready",
"total_node": 2,
"gpu_node": 2,
"ready_node": 2,
"node_group_number": 2
}
参数含义,参见下表。
选项 |
类型 |
描述 |
|---|---|---|
status |
string |
表示集群拓扑发现状态, |
total_node |
integer |
集群中所有节点的数量 |
gpu_node |
integer |
集群中GPU节点的数量 |
ready_node |
integer |
已完成拓扑发现的节点数量 |
node_group_number |
integer |
一个节点组中节点的数量 |
备注
集群内的所有GPU节点必须都满足dragonfly拓扑,否则gpu_node的数量可能和ready_node不相等,导致status的值一直为 training。
dragonfly模式下同时也支持通过 ConfigMap 方式配置集群拓扑,通过 ConfigMap 配置的集群拓扑具有更高的优先级。配置方式参见 6.1.6.1 config模式。
6.1.6.3. switchbox模式
switchbox模式用于switchbox架构下的拓扑发现。在安装GPU Extensions时通过配置 --set topoDiscovery.mode=switchbox 开启。
注意安装时需要配置cluster manager的地址和用户密码,否则拓扑组件无法正常工作。
可以通过以下接口查询拓扑的分组信息是否和物理拓扑一致。
TOPO_MASTER_IP=`kubectl get pod -n metax-gpu -owide | grep topo-master | awk {'print $6'}`
curl $TOPO_MASTER_IP:9001/node_group
例如在拓扑为两节点组成一个dragonfly组,两个dragonfly节点组成一个switchbox组的集群中,则可看到以下内容。
[
{
"name": "switchbox-sample1",
"kind": "switchbox",
"child": [
{
"name": "dragonfly-sample1",
"kind": "dragonfly",
"child": [
{
"name": "node-sample1",
"kind": "node",
"status": "Ready"
},
{
"name": "node-sample2",
"kind": "node",
"status": "Ready"
}
],
"status": "Ready"
},
{
"name": "dragonfly-sample2",
"kind": "dragonfly",
"child": [
{
"name": "node-sample3",
"kind": "node",
"status": "Ready"
},
{
"name": "node-sample4",
"kind": "node",
"status": "Ready"
}
],
"status": "Ready"
}
],
"status": "Ready"
}
]
参数含义,参见下表。
选项 |
类型 |
描述 |
|---|---|---|
name |
string |
节点组的名称 |
kind |
string |
节点组的类型 |
child |
array |
子节点组的信息 |
status |
string |
节点组状态, |
备注
当拓扑组件检测到cluster manager组件上报告警后,拓扑组件会在集群中上报
SuperNodeAbnormal事件。在switchbox重启或异常时,cluster manager组件会上报告警。当拓扑组件检测到告警时,会把对应的switchbox节点组设置为
NotReady状态,当告警消失时switchbox节点组恢复为Ready状态。在GPU服务器异常或者GPU链路出现异常时,cluster manager组件会上报告警。当拓扑组件检测到告警时,会把对应的节点设置为
NotReady状态,当告警消失且链路状态恢复正常后节点恢复为Ready状态。
6.2. 组件功能
6.2.1. gpu-device
gpu-device是沐曦基于 Kubernetes Device Plugin Framework [2] 的实现,以容器形式发布并以 DaemonSet 的形式部署在Kubernetes集群上。
该组件除了具备将沐曦GPU设备注册为 metax-tech.com/gpu 资源这一 Device Plugin 常见功能外,还实现了如下功能:
健康检查
gpu-device以一定间隔 [3] 周期性检查节点上的每个GPU设备,对发现故障的GPU资源进行状态上报。 Kubernetes根据上报信息将相关资源从 Allocatable 资源中移除,从而避免故障资源影响后续作业。
GPU拓扑最优分配
在单台服务器上配置多张GPU时,GPU卡间根据双方是否连接在相同的 PCIe Switch 或 MetaXLink 下,存在近远(带宽高低)关系。服务器上所有卡间据此形成一张拓扑,如下图所示。

图 6.1 典型拓扑示意图
用户作业请求一定数量的
metax-tech.com/gpu资源,Kubernetes选择剩余资源数量满足要求的节点,并将 Pod 调度到相应节点。 gpu-device进一步处理资源节点上剩余资源的分配逻辑,并按照以下优先级逻辑为作业容器分配GPU设备:MetaXLink 优先级高于 PCIe Switch,包含两层含义:
两卡之间同时存在 MetaXLink 连接以及 PCIe Switch 连接时,认定为 MetaXLink 连接。
服务器剩余GPU资源中 MetaXLink 互联资源与 PCIe Switch 互联资源均能满足作业请求时,分配 MetaXLink 互联资源。
分配GPU资源尽可能位于相同 MetaXLink 或 PCIe Switch 下。
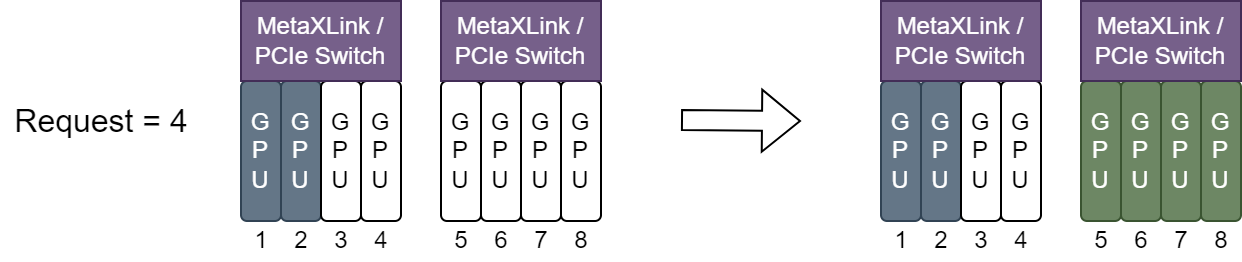
图 6.2 GPU资源分配示例1
如上图所示,GPU 1,2 已被分配,新分配 4 张GPU时,只有GPU 5,6,7,8 满足本条规则,因此是唯一分配方案。
分配GPU资源后,剩余资源尽可能完整。

图 6.3 GPU资源分配示例2
如上图所示,GPU 1,2 已被分配,新分配 2 张GPU时,分配GPU 3,4 可使剩余资源全部位于同一 MetaXLink 或 PCIe Switch 下,因此是遵循本条规则的唯一分配方案。
备注
尽管gpu-device在拓扑最优以及避免碎片上做了最大的努力,实际使用过程中并不能完全杜绝碎片的产生。 因此建议在集群使用时尽量以 1, 2, 4, 8 这样的粒度来分配GPU,最大限度地降低碎片的可能。
vfio-gpu资源申请
gpu-device会将绑定了
vfio-pci驱动的沐曦GPU注册为metax-tech.com/vfio-gpu资源,用户可以在KubeVirt上申请该资源。在 KubeVirt CR中的
featureGates添加HostDevices, GPU选项,并将沐曦GPU相应的设备信息配置到permittedHostDevices中。1apiVersion: kubevirt.io/v1 2kind: KubeVirt 3metadata: 4 name: kubevirt 5 namespace: kubevirt 6spec: 7 certificateRotateStrategy: {} 8 configuration: 9 developerConfiguration: 10 featureGates: ["HostDevices", "GPU"] 11 permittedHostDevices: 12 pciHostDevices: 13 - pciVendorSelector: "9999:4000" 14 resourceName: "metax-tech.com/vfio-gpu" 15 externalResourceProvider: true 16 - pciVendorSelector: "9999:4018" 17 resourceName: "metax-tech.com/vfio-gpu" 18 externalResourceProvider: true 19 customizeComponents: {} 20 imagePullPolicy: IfNotPresent 21 workloadUpdateStrategy: {}
在虚拟机配置的
hostDevices中添加metax-tech.com/vfio-gpu设备。1apiVersion: kubevirt.io/v1 2kind: VirtualMachine 3metadata: 4 labels: 5 kubevirt.io/vm: testvm 6 name: testvm 7spec: 8 running: false 9 template: 10 metadata: 11 labels: 12 kubevirt.io/vm: testvm 13 spec: 14 domain: 15 devices: 16 disks: 17 - disk: 18 bus: virtio 19 name: containerdisk 20 - disk: 21 bus: virtio 22 name: cloudinitdisk 23 interfaces: 24 - name: default 25 masquerade: {} 26 hostDevices: 27 - deviceName: metax-tech.com/vfio-gpu 28 name: gpu 29 resources: 30 requests: 31 memory: 4096Mi 32 terminationGracePeriodSeconds: 0 33 networks: 34 - name: default 35 pod: {} 36 volumes: 37 - containerDisk: 38 image: registry:5000/kubevirt/cirros-container-disk-demo:devel 39 name: containerdisk 40 - cloudInitNoCloud: 41 userData: | 42 #!/bin/sh 43 44 echo 'printed from cloud-init userdata' 45 name: cloudinitdisk
虚拟机启动成功后,可以通过
lspci命令看到对应的设备。user@testvm:~$ lspci | grep 9999 0a:00.0 Display controller: Device 9999:4000 (rev 01)
6.2.2. gpu-label
gpu-label同样以容器的形式发布,并以 DaemonSet 的形式部署在Kubernetes集群上。
该组件运行时,将检查节点上配置沐曦GPU的状态,并在确认配置了沐曦GPU的节点上,创建以下标签来描述GPU信息以及驱动软件信息。
标签 |
类型 |
描述 |
|---|---|---|
gpu.installed |
bool |
若节点配置了沐曦GPU,值为 |
driver.ready |
bool |
若节点已安装内核驱动,值为 |
gpu.driver.major |
integer |
内核驱动程序的主版本号 |
gpu.driver.minor |
integer |
内核驱动程序的次版本号 |
gpu.driver.mode |
enum |
驱动管理模式, |
gpu.driver.patch |
integer |
内核驱动程序的补丁版本号 |
gpu.family |
string |
显卡系列 |
gpu.memory |
string |
显卡内存大小 |
gpu.product |
string |
显卡型号 |
gpu.sriov |
string |
SR-IOV状态,可能为 |
gpu.vfnum |
integer |
显卡虚拟化配置 |
6.2.3. topo-master
topo-master以容器的形式发布,并以 Deployment 的形式部署在Kubernetes集群上。
topo-master组件运行时,接收topo-worker组件上报的拓扑信息后,生成集群级别的拓扑信息,并在节点上以带 metax-tech.com/topology.nodegroup- 前缀的标签来呈现。
6.2.4. topo-worker
topo-worker同样以容器的形式发布,并以 DaemonSet 的形式部署在Kubernetes集群上。
topo-worker组件运行时,会探测节点上的拓扑信息并上报给topo-master组件。另外,在dragonfly模式下,topo-worker还提供了自动training的功能。
6.2.5. gpu-aware
gpu-aware 基于 SchedulerExtender 实现,以容器形式发布并以 DaemonSet 形式部署在Kubernetes集群的管理节点上。
gpu-aware 组件的主要功能是辅助任务调度。基于集群视角,根据 gpu-device 提供的节点scores分数和losses分数,在多个工作节点中,选择最适合本次任务的节点。 节点scores分数(GPU拓扑通信分数)表示GPU间通信效率。节点losses分数(GPU拓扑损失分数)表示对原有拓扑结构造成的损失。
gpu-device 根据GPU当前物理拓扑关系,在遍历所有分配可能后,会依次计算出申请不同GPU数量任务的最佳分配方案。
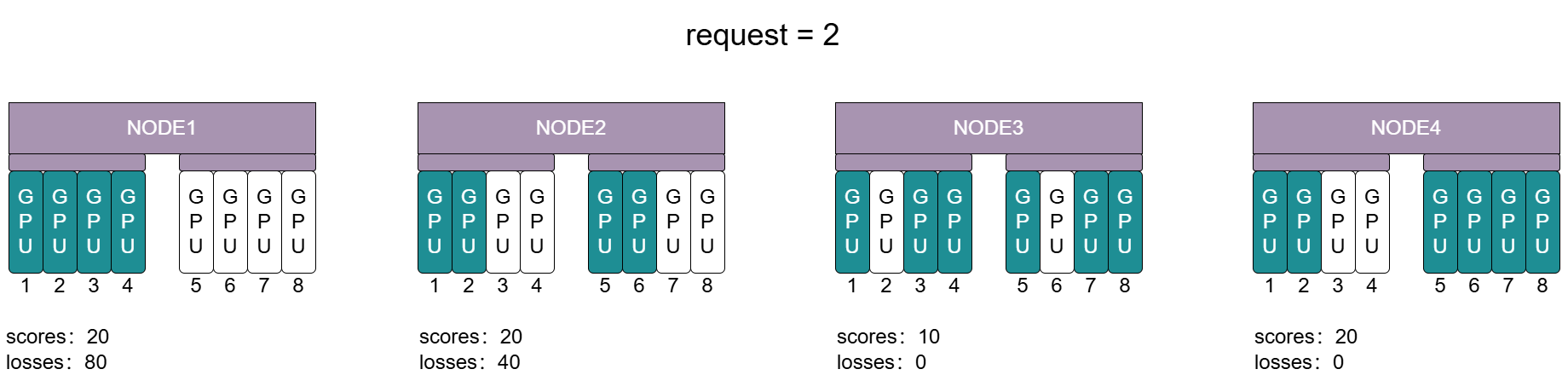
图 6.4 集群任务调度示例
上图展示了集群中节点的GPU拓扑关系,以及在集群中用户作业请求2个 metax-tech.com/gpu 资源时,最佳分配方案的分数情况。
以上述集群为例,gpu-aware会按照以下逻辑选择最适合本次任务的节点:
在对原有拓扑结构造成损失相同的情况下,选择通信效率高的节点。
当申请资源数量为2时:
NODE3和NODE4节点losses分数结果都为0,不会对原有拓扑结构造成损失。
NODE4的可用GPU处于同一 MetaXLink 或 PCIe Switch 下,通信效率更高。所以NODE4的scores分数比NODE3高(NODE4:20,NODE3:10)。
因此NODE4和NODE3作比较时,对原有拓扑结构造成损失相同的情况下,选择通信效率高的NODE4。
在通信效率相同的情况下,选择对原有拓扑结构造成损失小的节点。
当申请资源数量为2时:
NODE1,NODE2,NODE4节点的scores分数都为20,它们的通信效率是相同的。
NODE4剩余可用资源只有2,占用两个GPU后不会产生碎片,不会对原有拓扑结构造成损失。NODE4的losses分数为0最低(NODE4:0,NODE1:80,NODE2:40)。
因此NODE1,NODE2和NODE4作比较时,在通信效率相同的情况下,选择对原有拓扑结构造成损失小的NODE4。
在对原有拓扑结构造成损失不同,且通信效率不同的情况下,选择节点评分最高的节点。
当申请资源数量为2,且集群中有NODE1,NODE2,NODE3,NODE4四个可用节点时,它们对原有拓扑结构造成损失不同,且通信效率不同。 需要计算并选择节点评分最高的节点。
节点评分 = 通信分数权重 * GPU拓扑通信分数 - 损失分数权重 * GPU拓扑损失分数。(默认通信分数权重为1,损失分数权重为0.5)
当申请资源数量为2时,各节点评分如下:
NODE1: 1*20 - 0.5*80 = -20
NODE2: 1*20 - 0.5*40 = 0
NODE3: 1*10 - 0.5*0 = 10
NODE4: 1*20 - 0.5*0 = 20
NODE4 > NODE3 > NODE2 > NODE1,因此NODE1,NODE2,NODE3,NODE4做比较时,选择节点评分最高的NODE4。
6.2.5.1. gpu-aware节点评分方案
节点评分 = 通信分数权重 * GPU拓扑通信分数 - 损失分数权重 * GPU拓扑损失分数
gpu-aware节点评分 = gpu-aware组件权重 * 节点评分
最终节点评分 = 调度器节点评分 + gpu-aware节点评分
6.2.5.2. gpu-aware权重
gpu-aware 相关权重分为两个类型。
组件权重
组件权重的作用是:在多个extender服务启动的场景下,某个extender计算的节点评分,在所有extender的节点评分中,对最终分数的影响程度。
在各个extender内部计算完分数后,将该分数扩大组件权重的倍数,然后将扩大后的分数传递给调度器。
通信分数权重和损失分数权重
详情参见 表 6.4 gpu-aware Options。
6.3. 提交作业
6.3.1. 制作容器镜像
加载基础镜像
准备Dockerfile
为了得到尺寸精简的应用容器镜像,推荐在 Dockerfile 使用 multi-stage build 功能。以下为 Dockerfile 示例:
1FROM cr.metax-tech.com/library/maca-native:3.2.2.1-ubuntu18.04-amd64 as builder 2 3RUN apt-get update && apt-get install -y \ 4 autoconf \ 5 build-essential \ 6 libtool \ 7 patchelf \ 8 pkg-config \ 9 ... 10 11ENV VAR1=VALUE1 12ENV VAR2=VALUE2 13... 14 15WORKDIR /workspace 16COPY . /workspace 17RUN make OUTPUT=/app 18 19FROM cr.metax-tech.com/library/maca-native:3.2.1.4-ubuntu18.04-amd64 20 21RUN apt-get update && apt-get install -y \ 22 ... \ 23&& rm -rf /var/lib/apt/lists/* 24 25COPY --from=builder /app /app
用户基于此示例编写适用于实际工程的 Dockerfile 时,需注意以下细节:
[line 1] 使用 MXMACA® 基础镜像作为
builder镜像,提供必要的 MXMACA® 软件栈工具及库文件。[line 9] 此处增加构建用户应用所必须的工具和开发依赖库。
[line 13] 此处设置构建过程所需的环境变量。
[line 22] 此处安装用户应用运行时依赖库
[line 25] 从
builder容器中拷贝构建好的应用至基础容器
使用此过程构建应用容器可避免因开发工具、开发依赖库以及构建过程临时文件造成的存储浪费。
构建镜像
假设用户工作目录有如下结构, Project 为应用项目根目录, Dockerfile 放置于同级目录。
workspace ├── Dockerfile └── Project ├── Makefile └── src用户可在 workspace 目录运行以下命令完成镜像的构建:
docker build -f Dockerfile -t DOMAIN/PROJECT/application:1.0 ./Project
6.3.2. 准备作业yaml文件
用户可参考如下示例编写作业yaml文件:
1apiVersion: v1 2kind: Pod 3metadata: 4 name: application 5 labels: 6 app: application 7spec: 8 nodeSelector: 9 metax-tech.com/gpu.vfnum: "0" 10 metax-tech.com/gpu.product: "C500" 11 containers: 12 - image: DOMAIN/PROJECT/application:1.0 13 name: application-container 14 command: ["/bin/bash", "-c", "--"] 15 args: ["/app/bin/xxx --option=val; sleep infinity"] 16 resources: 17 limits: 18 metax-tech.com/gpu: 2
6.3.3. 提交作业
执行 kubectl create -f sample.yaml 命令提交作业。
6.4. 节点维护
在集群的正常运维过程中,管理员可能需要对工作节点内核驱动进行重装、升级等操作,须遵循以下操作步骤:
使用
kubectl cordon命令停止向节点调度新的任务,移除所有metax-tech.com域下标签。kubectl cordon <nodename>
等待gpu-device Pod从节点上退出。
终止所有正在运行的使用沐曦GPU的用户任务Pod。
进行内核驱动卸载、重装、升级等相关操作。
使用
kubectl uncordon命令恢复节点功能。kubectl uncordon <nodename>
确认节点标签恢复,节点上可分配资源恢复。
kubectl describe node <nodename>