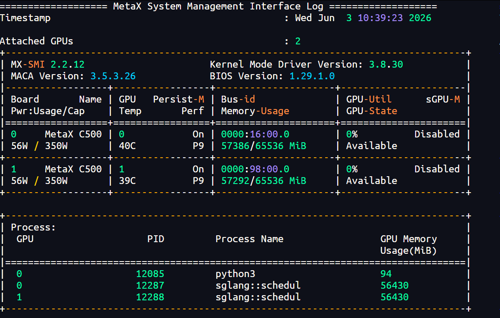
使用沐曦官方镜像:sglang:0.5.9-maca.ai3.5.3.208-torch2.8-py312-ubuntu22.04-amd64 部署模型 Qwen3.5-9B 时,能够成功部署,但是报了下面的错误,/bin/sh: 1: /opt/maca/tools/cu-bridge/bin/nvcc: not found, 为什么沐曦的sglang会找nvidia的nvcc
[2026-06-03 10:24:38] INFO: Started server process [12085]
[2026-06-03 10:24:38] INFO: Waiting for application startup.
[2026-06-03 10:24:38] INFO: Application startup complete.
[2026-06-03 10:24:38] INFO: Uvicorn running on http://0.0.0.0:9100 (Press CTRL+C to quit)
[2026-06-03 10:24:39] INFO: 127.0.0.1:58588 - "GET /model_info HTTP/1.1" 200 OK
[2026-06-03 10:24:47 TP1] Failed to load JIT KV-Cache kernel with row_bytes=1024: ninja exited with status 1
stdout:
[1/2] /opt/maca/tools/cu-bridge/bin/nvcc --generate-dependencies-with-compile --dependency-output cuda_0.o.d -Xcompiler -fPIC -std=c++17 -O2 -gencode=arch=compute_80,code=sm_80 -std=c++20 -O3 --expt-relaxed-constexpr -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/sglang/jit_kernel/include -c /root/.cache/tvm-ffi/sgl_kernel_jit_kvcache_1024_false_cb53493e06f7ab59/cuda.cu -o cuda_0.o
FAILED: cuda_0.o
/opt/maca/tools/cu-bridge/bin/nvcc --generate-dependencies-with-compile --dependency-output cuda_0.o.d -Xcompiler -fPIC -std=c++17 -O2 -gencode=arch=compute_80,code=sm_80 -std=c++20 -O3 --expt-relaxed-constexpr -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/sglang/jit_kernel/include -c /root/.cache/tvm-ffi/sgl_kernel_jit_kvcache_1024_false_cb53493e06f7ab59/cuda.cu -o cuda_0.o
/bin/sh: 1: /opt/maca/tools/cu-bridge/bin/nvcc: not found
ninja: build stopped: subcommand failed.
[2026-06-03 10:24:47 TP0] Failed to load JIT KV-Cache kernel with row_bytes=1024: ninja exited with status 1
stdout:
[1/2] /opt/maca/tools/cu-bridge/bin/nvcc --generate-dependencies-with-compile --dependency-output cuda_0.o.d -Xcompiler -fPIC -std=c++17 -O2 -gencode=arch=compute_80,code=sm_80 -std=c++20 -O3 --expt-relaxed-constexpr -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/sglang/jit_kernel/include -c /root/.cache/tvm-ffi/sgl_kernel_jit_kvcache_1024_false_cb53493e06f7ab59/cuda.cu -o cuda_0.o
FAILED: cuda_0.o
/opt/maca/tools/cu-bridge/bin/nvcc --generate-dependencies-with-compile --dependency-output cuda_0.o.d -Xcompiler -fPIC -std=c++17 -O2 -gencode=arch=compute_80,code=sm_80 -std=c++20 -O3 --expt-relaxed-constexpr -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/tvm_ffi/include -I/opt/conda/lib/python3.12/site-packages/sglang/jit_kernel/include -c /root/.cache/tvm-ffi/sgl_kernel_jit_kvcache_1024_false_cb53493e06f7ab59/cuda.cu -o cuda_0.o
/bin/sh: 1: /opt/maca/tools/cu-bridge/bin/nvcc: not found
ninja: build stopped: subcommand failed.
[2026-06-03 10:24:47 TP0] Prefill batch, #new-seq: 1, #new-token: 80, #cached-token: 0, full token usage: 0.00, mamba usage: 0.00, #running-req: 0, #queue-req: 0, input throughput (token/s): 0.00, cuda graph: False
[2026-06-03 10:24:48] INFO: 127.0.0.1:58590 - "POST /v1/chat/completions HTTP/1.1" 200 OK
[2026-06-03 10:24:48] The server is fired up and ready to roll!