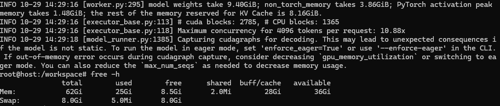
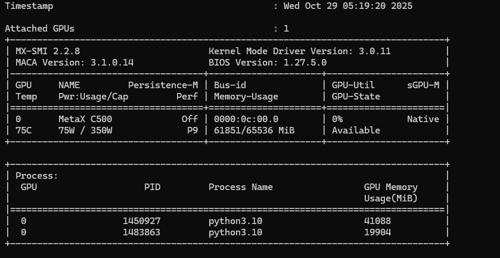
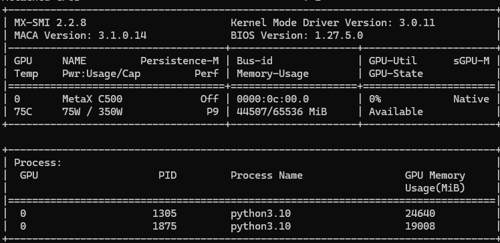
把14B模型换成0.5B模型还是不行,卡在刚才那个位置,但是启动的时候切换成--enforce-eager就可以了
Raining
- Members
- Joined 2025年10月21日
-
-
-
还是卡住,但是现在第二个模型启动的时候卡在这里, 是需要我启动的时候加上--enforce-eager吗?:
INFO 10-29 14:29:16 [executor_base.py:113] # cuda blocks: 2785, # CPU blocks: 1365
INFO 10-29 14:29:16 [executor_base.py:118] Maximum concurrency for 4096 tokens per request: 10.88x
INFO 10-29 14:29:18 [model_runner.py:1385] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasinggpu_memory_utilizationor switching to eager mode. You can also reduce themax_num_seqsas needed to decrease memory usage.内存情况如下:
-
-
-
你好,我一个设置的0.34,一个0.3还是不行,一直卡在下面这里就不走了,显存明显还有20G的剩余:
[rank0]:W1029 09:35:11.250000 1875 site-packages/torch/_inductor/utils.py:1197] [0/0] Forcing disable 'CUTLASS' backend as it is not supported in maca platform.
[rank0]:W1029 09:35:11.259000 1875 site-packages/torch/_inductor/utils.py:1197] [0/0] Forcing disable 'CUTLASS' backend as it is not supported in maca platform.
INFO 10-29 09:35:12 [backends.py:215] Compiling a graph for dynamic shape takes 71.86 s
INFO 10-29 09:35:47 [monitor.py:34] torch.compile takes 84.68 s in total
INFO 10-29 09:35:48 [gpu_worker.py:255] Available KV cache memory: 1.55 GiB
INFO 10-29 09:35:48 [kv_cache_utils.py:833] GPU KV cache size: 12,688 tokens
INFO 10-29 09:35:48 [kv_cache_utils.py:837] Maximum concurrency for 4,096 tokens per request: 3.10x -
-
-
之前部署一个模型,推理也没问题,但是升级显卡驱动到3.1.0.14,突然就不行了,推理启动有时候有问题,有时候能启动,但是不能推理,没有返回数据,有时候启动还报错,镜像版本是:cr.metax-tech.com/public-ai-release/maca/modelzoo.llm.vllm:maca.ai3.1.0.7-torch2.6-py310-ubuntu22.04-amd64, 会不会是因为镜像版本低于驱动版本造成的?如果是的话,去哪里下载最新的docker镜像:
[19:40:55.226][MXKW][E]queues.c :812 : [mxkwCreateQueueBlock]ioctl create queue block failed -1
[19:40:55.228][MXC][E]exception: DMAQueue create failed at mxkwCreateQueueBlock.
[19:40:55.229][MCR][E]mx_device.cpp :3544: Mxc copy from host to device failed with code 4104
[19:40:55.243][MXKW][E]queues.c :812 : [mxkwCreateQueueBlock]ioctl create queue block failed -1
[19:40:55.244][MXC][E]exception: DMAQueue create failed at mxkwCreateQueueBlock.
[19:40:55.244][MCR][E]mx_device.cpp :3637: Mxc copy from device to device failed with code 4104
[19:40:55.260][MXKW][E]queues.c :812 : [mxkwCreateQueueBlock]ioctl create queue block failed -1
[19:40:55.263][MXC][E]exception: DMAQueue create failed at mxkwCreateQueueBlock.
[19:40:55.263][MCR][E]mx_device.cpp :3544: Mxc copy from host to device failed with code 4104
[19:40:55.288][MXKW][E]queues.c :812 : [mxkwCreateQueueBlock]ioctl create queue block failed -1
[19:40:55.288][MXC][E]exception: DMAQueue create failed at mxkwCreateQueueBlock.
[19:40:55.289][MCR][E]mx_device.cpp :3544: Mxc copy from host to device failed with code 4104
[19:40:55.306][MXKW][E]queues.c :812 : [mxkwCreateQueueBlock]ioctl create queue block failed -1
[19:40:55.306][MCR][E]mx_device.cpp :1219: Device::acquireQueue: mxc_queue_acquire failed!
Traceback (most recent call last):
File "/opt/conda/bin/vllm", line 8, in <module>
sys.exit(main())
File "/opt/conda/lib/python3.10/site-packages/vllm/entrypoints/cli/main.py", line 54, in main
args.dispatch_function(args)
File "/opt/conda/lib/python3.10/site-packages/vllm/entrypoints/cli/serve.py", line 52, in cmd
uvloop.run(run_server(args))
File "/opt/conda/lib/python3.10/site-packages/uvloop/init.py", line 82, in run
return loop.run_until_complete(wrapper())
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/opt/conda/lib/python3.10/site-packages/uvloop/init.py", line 61, in wrapper
return await main
File "/opt/conda/lib/python3.10/site-packages/vllm/entrypoints/openai/api_server.py", line 1791, in run_server
await run_server_worker(listen_address, sock, args, *uvicorn_kwargs)
File "/opt/conda/lib/python3.10/site-packages/vllm/entrypoints/openai/api_server.py", line 1811, in run_server_worker
async with build_async_engine_client(args, client_config) as engine_client:
File "/opt/conda/lib/python3.10/contextlib.py", line 199, in aenter
return await anext(self.gen)
File "/opt/conda/lib/python3.10/site-packages/vllm/entrypoints/openai/api_server.py", line 158, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
File "/opt/conda/lib/python3.10/contextlib.py", line 199, in aenter
return await anext(self.gen)
File "/opt/conda/lib/python3.10/site-packages/vllm/entrypoints/openai/api_server.py", line 194, in build_async_engine_client_from_engine_args
async_llm = AsyncLLM.from_vllm_config(
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/async_llm.py", line 163, in from_vllm_config
return cls(
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/async_llm.py", line 117, in init
self.engine_core = EngineCoreClient.make_async_mp_client(
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/core_client.py", line 98, in make_async_mp_client
return AsyncMPClient(client_args)
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/core_client.py", line 677, in init
super().init(
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/core_client.py", line 408, in init
with launch_core_engines(vllm_config, executor_class,
File "/opt/conda/lib/python3.10/contextlib.py", line 142, in exit
next(self.gen)
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/utils.py", line 697, in launch_core_engines
wait_for_engine_startup(
File "/opt/conda/lib/python3.10/site-packages/vllm/v1/engine/utils.py", line 750, in wait_for_engine_startup
raise RuntimeError("Engine core initialization failed. "
RuntimeError: Engine core initialization failed. See root cause above. Failed core proc(s): {'EngineCore_0': -11}
root@host:/workspace# mx-smi
mx-smi version: 2.2.8=================== MetaX System Management Interface Log ===================
Timestamp : Thu Oct 23 19:43:59 2025Attached GPUs : 1
+---------------------------------------------------------------------------------+
| MX-SMI 2.2.8 Kernel Mode Driver Version: 3.0.11 |
| MACA Version: 3.1.0.14 BIOS Version: unknown |
|------------------------------------+---------------------+----------------------+
| GPU NAME Persistence-M | Bus-id | GPU-Util sGPU-M |
| Temp Pwr:Usage/Cap Perf | Memory-Usage | GPU-State |
|====================================+=====================+======================|
| 0 MetaX C500 N/A | 0000:0c:00.0 | N/A Native |
| N/A NA / NA N/A | 858/65536 MiB | Not Available |
+------------------------------------+---------------------+----------------------++---------------------------------------------------------------------------------+
| Process: |
| GPU PID Process Name GPU Memory |
| Usage(MiB) |
|=================================================================================|
| no process found |
+---------------------------------------------------------------------------------+ -
镜像这么启动有问题吗?
docker run -itd --privileged --group-add video --network=host --name vllm --shm-size 100gb --ulimit memlock=-1 -v /data:/data cr.metax-tech.com/public-ai-release/maca/modelzoo.llm.vllm:maca.ai3.1.0.7-torch2.6-py310-ubuntu22.04-amd64 -
-
从下方mx-smi可以看到显存占用已经执行了,目前有2个vllm服务占用了显存
一、软硬件信息
1.服务器厂家:
System Information
Manufacturer: RongXinZhiYuan
Product Name: DAU-H100
Version: 0.1
Serial Number: 001BBW18010027
UUID: 00112233-4455-6677-8899-aabbccddeeff
Wake-up Type: Power Switch
SKU Number: Kunlun_Hygon65N32_SKU
Family: Type1FamilyHandle 0x0013, DMI type 12, 5 bytes
System Configuration Options
Option 1: ConfigOptions String 1
Option 2: ConfigOptions String 2Handle 0x0015, DMI type 32, 11 bytes
System Boot Information
Status: No errors detected2.沐曦GPU型号:
MetaX C5003.操作系统内核版本:
Static hostname: host
Icon name: computer-server
Chassis: server
Machine ID: d03463cf8d154a38873c9161c0aa65da
Boot ID: f0934e776e614dd3aa36820d16e7ee84
Operating System: Ubuntu 22.04.5 LTS
Kernel: Linux 5.15.0-119-generic
Architecture: x86-644.是否开启CPU虚拟化:
Virtualization: AMD-V5.mx-smi回显: 这里是因为2个服务都开启了,但是有一个开启了一半,一直卡住,但是显存已经占用完毕了。
mx-smi version: 2.2.3=================== MetaX System Management Interface Log ===================
Timestamp : Tue Oct 21 04:52:31 2025Attached GPUs : 1
+---------------------------------------------------------------------------------+
| MX-SMI 2.2.3 Kernel Mode Driver Version: 2.14.6 |
| MACA Version: 2.32.0.6 BIOS Version: 1.24.3.0 |
|------------------------------------+---------------------+----------------------+
| GPU NAME | Bus-id | GPU-Util |
| Temp Pwr:Usage/Cap | Memory-Usage | |
|====================================+=====================+======================|
| 0 MetaX C500 | 0000:0f:00.0 | 0% |
| 74C 75W / 350W | 41244/65536 MiB | |
+------------------------------------+---------------------+----------------------++---------------------------------------------------------------------------------+
| Process: |
| GPU PID Process Name GPU Memory |
| Usage(MiB) |
|=================================================================================|
| 0 2317608 python3.10 20480 |
| 0 2327607 python3.10 19904 |
+---------------------------------------------------------------------------------+6.docker info回显:
Client: Docker Engine - Community
Version: 28.5.1
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc.)
Version: v0.29.1
Path: /usr/libexec/docker/cli-plugins/docker-buildx
compose: Docker Compose (Docker Inc.)
Version: v2.40.0
Path: /usr/libexec/docker/cli-plugins/docker-composeServer:
Containers: 2
Running: 2
Paused: 0
Stopped: 0
Images: 3
Server Version: 28.5.1
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: systemd
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local splunk syslog
CDI spec directories:
/etc/cdi
/var/run/cdi
Swarm: inactive
Runtimes: io.containerd.runc.v2 runc
Default Runtime: runc
Init Binary: docker-init
containerd version: b98a3aace656320842a23f4a392a33f46af97866
runc version: v1.3.0-0-g4ca628d1
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: builtin
cgroupns
Kernel Version: 5.15.0-119-generic
Operating System: Ubuntu 22.04.5 LTS
OSType: linux
Architecture: x86_64
CPUs: 16
Total Memory: 62.47GiB
Name: host
ID: 8eec869e-d6f4-4a72-a7c6-bc08d84e93e1
Docker Root Dir: /var/lib/docker
Debug Mode: false
Experimental: false
Insecure Registries:
::1/128
127.0.0.0/8
Live Restore Enabled: false7.镜像版本:
cr.metax-tech.com/public-ai-release/maca/modelzoo.llm.vllm:maca.ai3.1.0.7-torch2.6-py310-ubuntu22.04-amd64