2. 编程模型
2.1. 程序结构
如图 2.1 所示,MXMACA程序是一个定义了上下文的宿主机程序。一个MXMACA上下文对象内具有两个计算设备:一个CPU设备和一个GPU设备。 每个计算设备具有自己的命令队列,所以有两种命令队列:一种是面向CPU的乱序命令队列,另一种是面向GPU的有序命令队列。 然后MXMACA宿主机程序定义一个程序对象,这个程序对象编译后将为两个MXMACA设备(CPU和GPU)生成内核。接下来MXMACA宿主机程序定义程序所需的内存对象,并把它们映射到内核的参数。 最后,MXMACA宿主机程序将命令放入命令队列来执行这些内核。
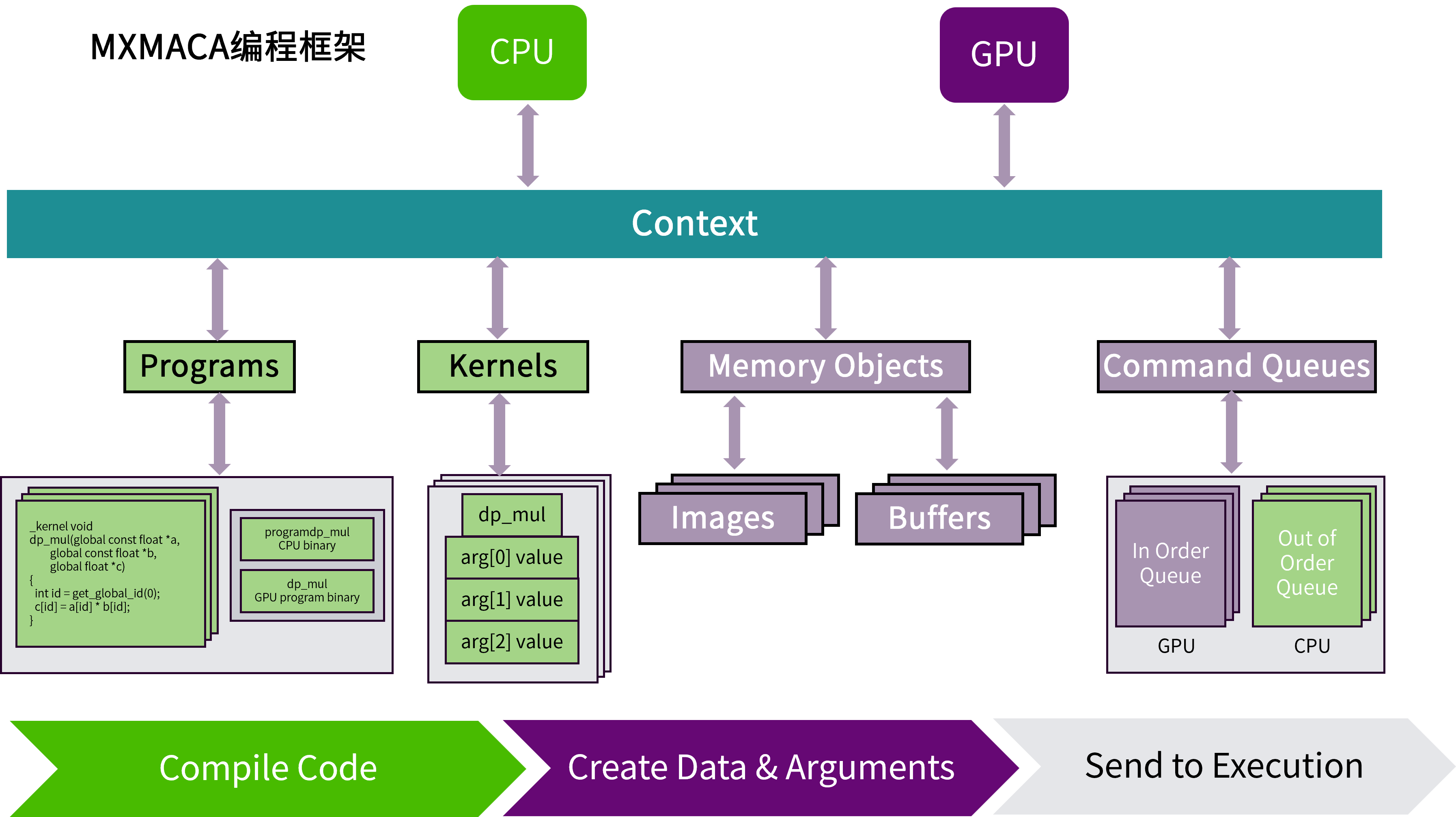
图 2.1 MXMACA程序结构全景图
MXMACA编程使用由C/C++语言扩展生成的注释代码在异构计算系统中执行应用程序。一个异构环境包含多个CPU和GPU,每个CPU和GPU都由一条PCIe总线隔开,因此需要注意区分这两个内容:
主机:CPU及其内存(主机内存)
设备:GPU及其内存(设备内存)
核函数(kernel)是MXMACA编程模型的重要组成部分,其代码在GPU上运行。 多数情况下主机可以独立地对设备进行操作,而内核一旦启动,管理权限立刻返回给主机,释放CPU执行其他的任务。因此MXMACA编程模型主要是异步的。
一个典型的MXMACA程序包括并行代码和串行代码,如图 2.2 所示。串行代码在主机CPU上执行,而并行代码在GPU上执行。 主机代码按照标准C/C++编写,而设备代码使用MXMACA C/C++编写,mxcc编译器为主机和设备生成可执行代码。
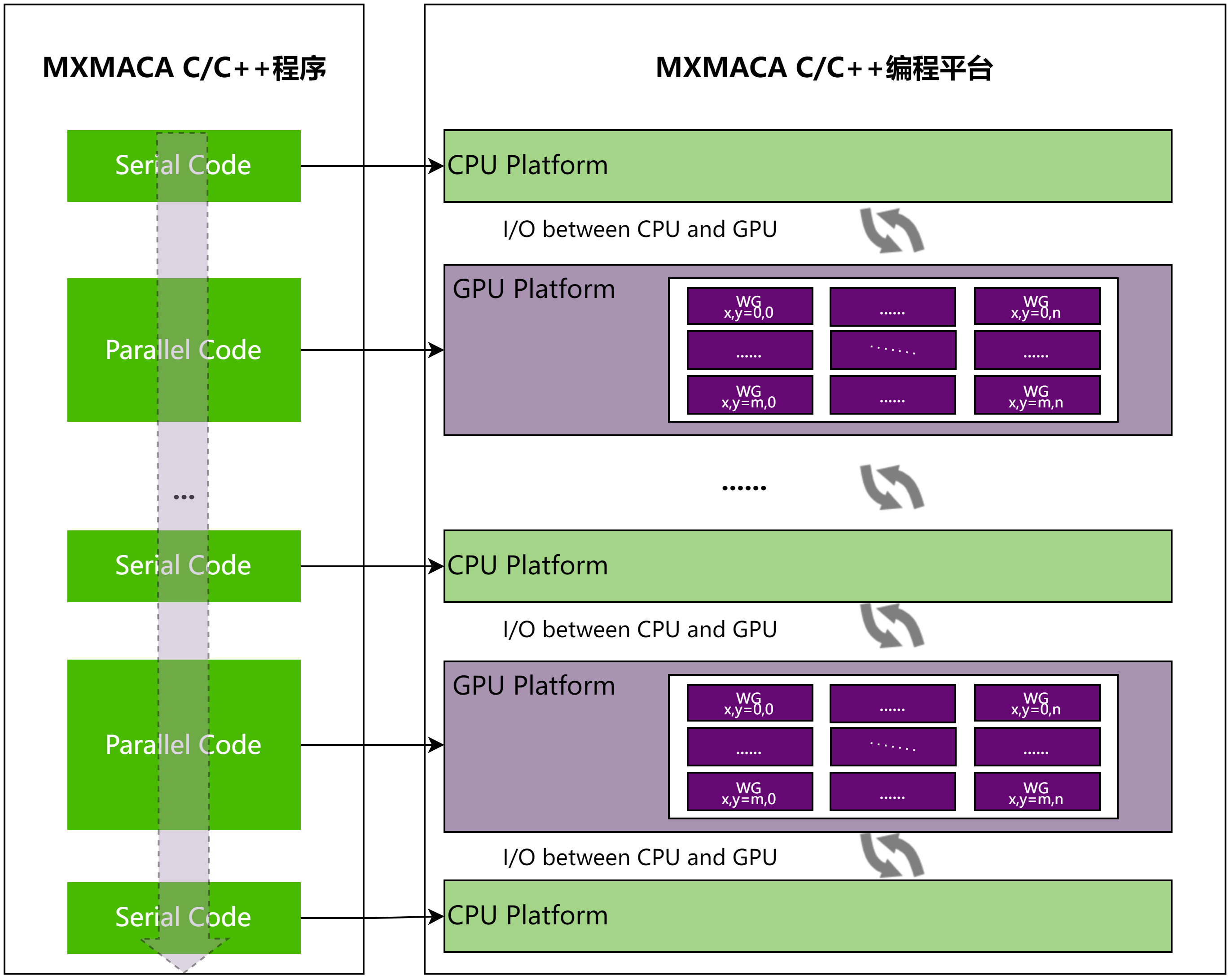
图 2.2 MXMACA C/C++程序常见范式
一个典型的MXMACA程序实现流程应遵循下面的模式:
把数据从CPU内存拷贝到GPU内存
调用核函数对GPU内存的数据进行处理
将数据从GPU内存传送回CPU内存
2.2. 执行模型
曦云系列GPU编程的执行模型如图 2.3 所示:
GPU硬件将执行内核的各个实例定义为一个工作项(work-item),等同于MXMACA程序里的一个GPU线程(thread),工作项由它在索引空间中的坐标来标识。这些坐标就是工作项的全局ID。
GPU硬件会相应地提交相同内核执行的命令创建一个工作项集合,称之为工作组(work-group),等同于MXMACA程序里的一个线程块(thread block)。 工作组中的各个工作项使用内核定义的相同指令序列。尽管指令序列是相同的,但是由于代码中的分支语句或者通过全局ID选择的数据可能不同,因此各个工作项的行为可能不同。
工作组提供了对索引空间更粗粒度的分解,跨越整个全局索引空间。工作组在相应维度的大小相同,这个大小可以整除各维度中的全局大小。为工作组指定一个唯一的ID,这个ID与工作项使用的索引空间有相同的维度。为工作项指定一个局部ID,这个局部ID在工作组中是唯一的,这样就能由其全局ID或者由其局部ID和工作组ID唯一地标识一个工作项。
一个软件Grid是一个N维的值网格,称为线程网格。这个N维索引空间中的N可以是1、2或3。一个软件Grid(OpenCL的ND-Range)包括多个工作组(Work-Group),每个工作组负责执行Grid指定的一个工作项集合。
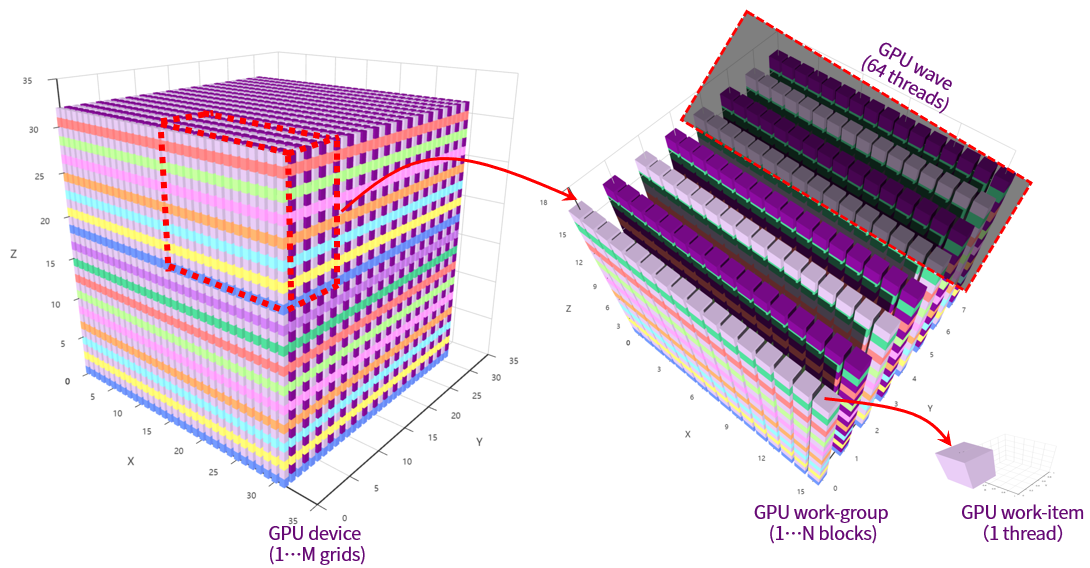
图 2.3 GPU编程的执行模型
MXMACA编程采用单指令多线程(SIMT)架构来管理和执行线程。每64个线程为一组,被称为线程束(wave)。 线程束中所有线程同时执行相同的指令,每个线程都有自己的指令地址计数器和寄存器状态,利用自身数据执行当前指令。 曦云系列GPU硬件里的加速处理器(Accelerated Processor,AP)都将分配给它的线程划分到线程束中,然后在可用的硬件资源上调度执行。 64个线程组成一个线程束来自于沐曦GPU硬件系统设计,和OpenCL的线程束大小是一致的(waveSize=64),它是加速处理器上用SIMD方式所同时处理的工作粒度。 MXMACA软件的程序设计需要参照waveSize来定义线程块大小,优化工作负载以适应线程束的边界,可以更有效地利用GPU资源。
SIMT架构与SIMD架构相似,两者都将相同的指令广播给多个执行单元来实现并行。 一个关键区别是,SIMD要求同一向量的所有元素在一个同步组中一起执行,而SIMT则允许同一线程束的多个线程独立执行。 尽管一个线程束中所有线程在相同的程序地址同时开始执行,但是单独的线程仍有可能有不同的行为。 SIMT确保可以编写独立的线程级并行代码、标量线程、以及用于协调线程的数据并行代码。SIMT模型包含3个SIMD所不具备的关键特征:
每个线程都有自己的指令地址计数器
每个线程都有自己的寄存器状态
每个线程都可以有一个独立的执行路径
2.3. 内存层次模型
如图 2.4 所示,内存是分层次的,每种不同类型的内存空间都有不同的作用域、生命周期和缓存行为。 在一个核函数中,每个线程都有自己的私有内存(Private Memory),每个线程块有自己的工作组共享内存(Workgroup Shared Memory,WSM)并对块内的所有线程可见,一个线程网格中的所有线程都可以访问全局内存和常量内存,其中常量内存为只读内存空间。 理解了基于沐曦GPU硬件架构的MXMACA内存层次模型,有助于帮助MXMACA程序设计如何通过改善访存策略来提升MXMACA核函数的性能。
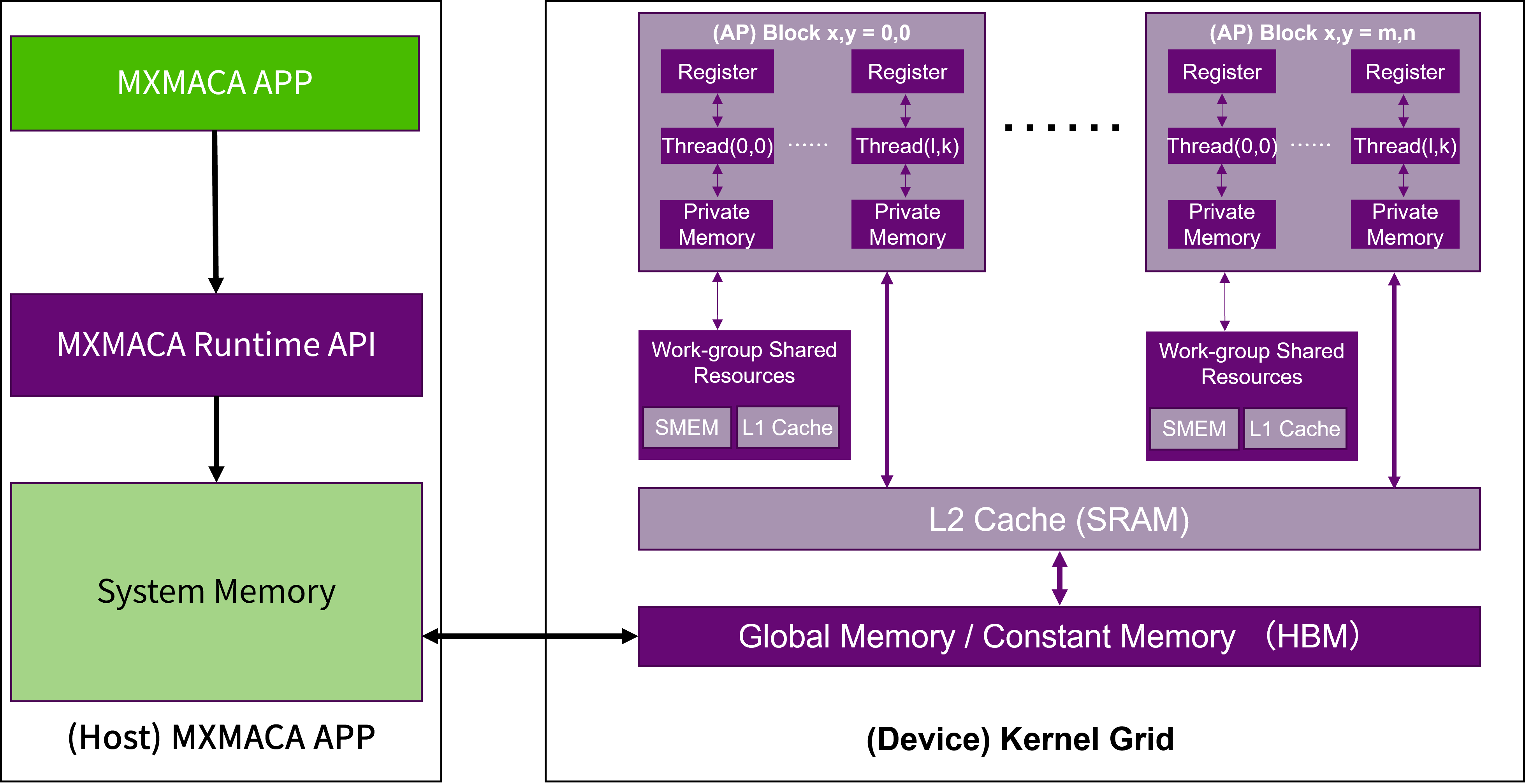
图 2.4 MXMACA编程的内存层次模型
MXMACA编程和其他GPU编程语言一样,根据存储器是否可以被程序员控制,可将其分为两种类型:
可编程存储器:需要显式控制哪些数据放在可编程内存中
不可编程存储器:不能决定哪些数据放在这些存储器中,也不能决定数据在存储器中的位置
GPU的可编程存储单元包括全局存储,常量存储,共享存储,本地存储和寄存器等。 而不可编程存储单元则包括一级缓存、二级缓存等。另外,CPU端(主机端)存储类型,以及CPU和GPU的通信接口和通信方式也会影响GPU程序执行的性能。
2.4. 核函数
MXMACA核函数调用是对C语言函数调用语句的延伸,核函数启动代码如下:
kernel_name <<<grid, block>>>(argument_list);
其中 <<<>>> 运算符内是核函数的执行配置:
第一个值是线程网格维度,即启动线程块的数目
第二个值是线程块的维度,即每个线程块的线程数目
通过指定线程网格和线程块的大小,可以配置核函数中线程的使用数目和线程的使用布局, 如图 2.5 所示:
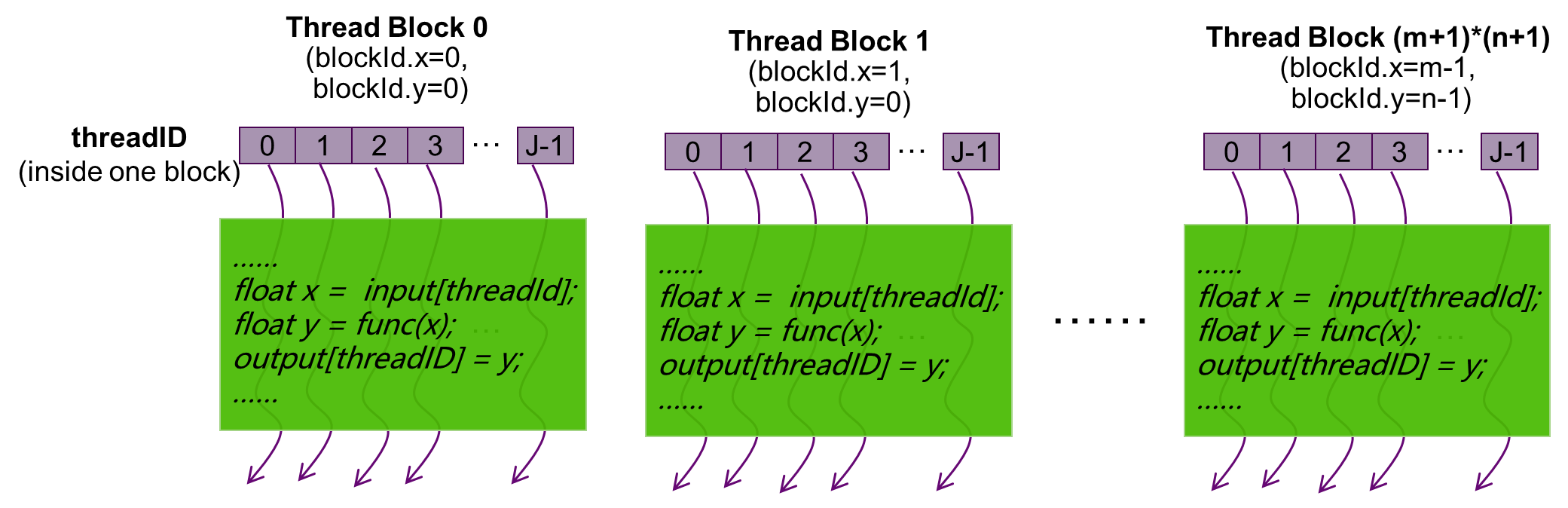
图 2.5 二维线程网格的线程布局
由于数据在全局内存中是线性存储的,二维线程网格可以使用变量(blockIdx.x, blockIdx.y),二维线程块可以使用(threadIdx.x, threadIdx.y):
在线程网格中标识唯一的线程
建立线程块和数据元素之间映射关系
2.5. 动态并行
MXMACA的动态并行是一个扩展功能,能够在GPU上直接创建任务和同步操作,减少了主机和设备之间传输控制和数据的需求。 此外,依赖于数据的并行工作可以在核函数里面直接进行决策和调整,以前需要修改代码以消除递归、不规则循环结构或者其他不适合扁平、单级并行的算法和编程模式可以更透彻的表达。
MXMACA执行模型基于线程、线程块和网格的基元,核函数定义了线程块和线程网格中各个线程执行的程序。当调用核函数时,网格的属性由执行配置描述,该配置在MXMACA中具有特殊语法。 MXMACA的动态并行扩展了配置、启动和隐式同步新网格到设备上运行的线程能力,如图 2.6 所示。
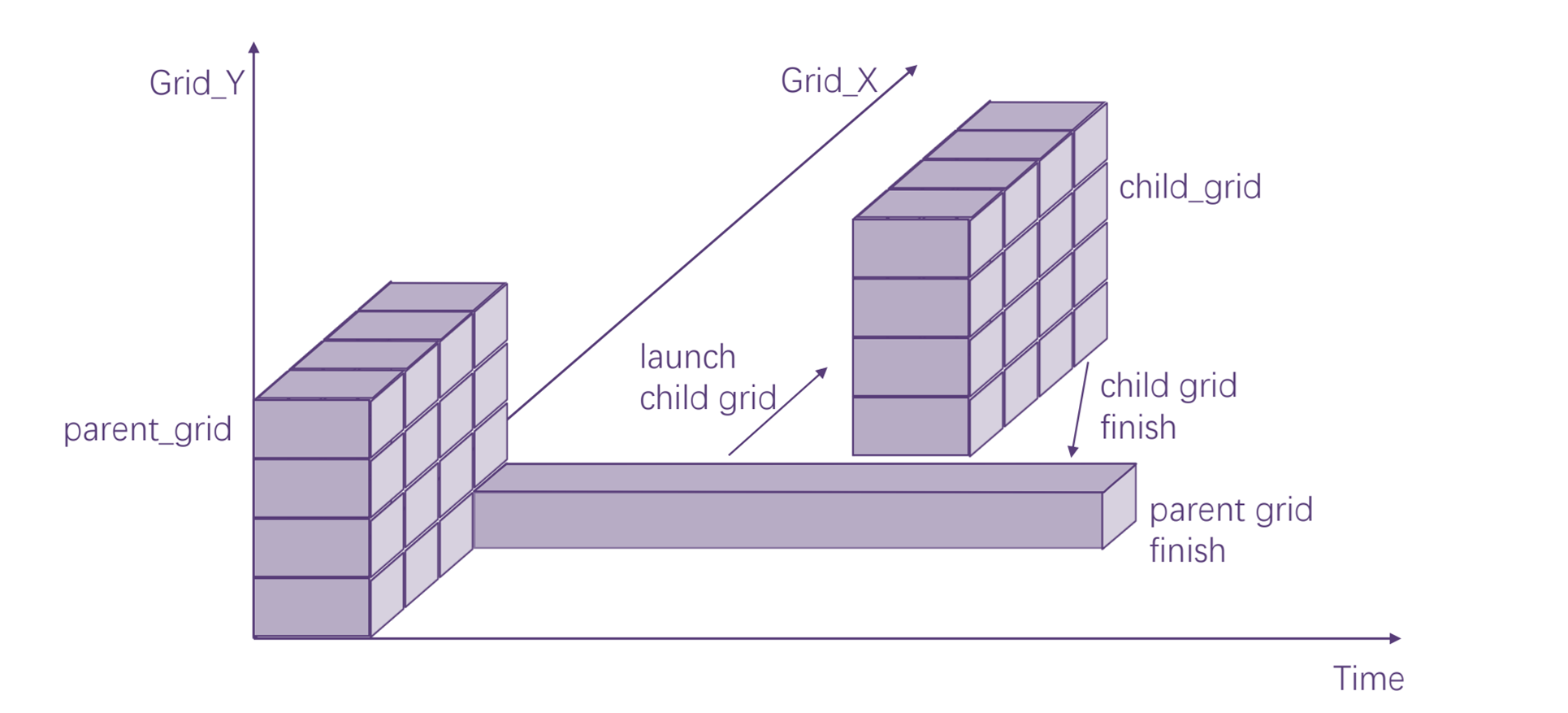
图 2.6 动态并行示意图
配置和启动新网格的设备线程属于父网格,调用创建的网格是子网格。 子网格的调用和完成是正确嵌套的,这意味着父网格在其线程创建的所有子网格完成之前不会被认为是完整的,并且设备运行时由驱动软件保证父网格和子网格之间的隐式同步。
2.6. 图编程
MXMACA编程中经典的启动内核就是采用 <<<>>> 语法的接口,这个三尖号语法在编译时会被替换为MXMACA运行时库提供的 mcLaunchKernel 函数。
当这些内核很多且持续时间很短时,启动开销有时会成为一个问题。 MXMACA图编程提供了一种减少开销的方法,通过将用户的一系列操作定义为任务图,可以将任意数量的异步MXMACA API调用(包括核函数启动)组合到一个只需要一次启动的操作中,可以显著减少启动大量用户操作的开销。 图 2.7 给出了MXMACA图编程与经典MXMACA流和并发编程的主要区别。此外,通过提前了解任务图的整个工作流,MXMACA驱动程序也能够应用各种优化。 当然,这种性能提升是以牺牲灵活性为代价的:如果事先不知道整个工作流,则GPU执行必须中断,才能返回CPU做出决定。
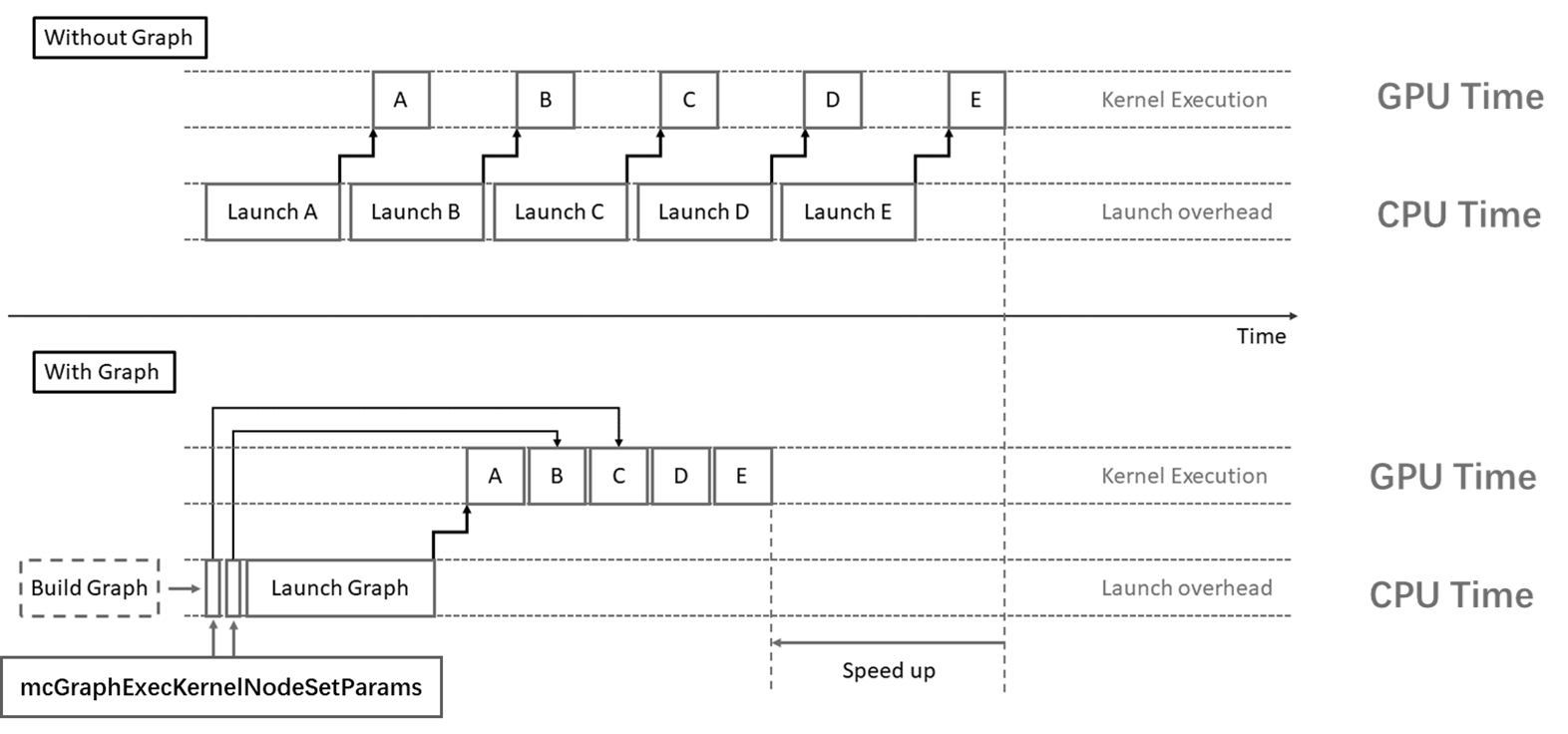
图 2.7 MXMACA图编程场景示例
2.7. MPS多进程服务
随着GPU性能的显著提升,单一应用程序可能难以完全发挥GPU的全部潜力。 MXMACA多进程服务(MPS)是一种先进的机制,它使得多个CPU进程能够通过设定的计算任务队列使用策略,在同一GPU上实现多个进程任务的并发提交和执行。