8. 并行编程库适配
8.1. Kokkos与RAJA
在现代计算机系统中,不同的硬件平台和体系结构需要使用不同的编程模型和工具来进行开发和优化。 为此,Kokkos与RAJA等并行框架提供了一些通用的编程接口和工具,使程序员可以更加轻松地编写跨平台的应用程序。
Kokkos提供了许多抽象数据类型和算法库,如数组、矩阵、图形等。 这些抽象类型和库可以在不同的硬件平台上进行优化,并且可以充分利用硬件的并行化特性,从而实现高效的计算。 RAJA则提供了多种执行策略和算法库,让开发者可以选择最适合自己应用程序的并行模型和算法。
8.2. Kokkos与RAJA的基本用法
Kokkos与RAJA都是使用C++编写的高性能并行计算库,提供了数据并行和执行模式,它们的基本用法大致类似。
8.2.1. 安装与编译
Kokkos安装
$ git clone https://github.com/kokkos/kokkos.git
$ cd kokkos
$ mkdir build
$ cd build
$ cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local #其他编译选项可视情况增加
$ make
$ sudo make install
RAJA安装
$ git clone https://github.com/LLNL/RAJA.git
$ cd RAJA
$ mkdir build
$ cd build
$ cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local #其他编译选项可视情况增加
$ make
$ sudo make install
8.2.2. 应用程序的编译与执行
Kokkos应用程序
$ cmake /path/to/your/source/files -DCMAKE_CXX_COMPILER=g++ -DKokkos_PREFIX=/usr/local
$ make
$ ./your_executable
RAJA应用程序
$ cmake -DCMAKE_CXX_COMPILER=g++ -DRAJA_DIR=/usr/local
$ make
$ ./your_executable
8.2.3. 代码示例
8.2.3.1. Kokkos代码示例
在Kokkos中,使用视图(View)表示多维数组的抽象。以下是使用视图的代码示例:
#include <Kokkos_Core.hpp>
int main()
{
int N = 10;
// 创建视图
Kokkos::View<double *> a("a", N);
Kokkos::View<double *> b("b", N);
Kokkos::View<double *> c("c", N);
// 初始化数据
Kokkos::parallel_for(
N, KOKKOS_LAMBDA(const int i) {
a(i) = i;
b(i) = 2 * i;
});
// 向量加法
Kokkos::parallel_for(
N, KOKKOS_LAMBDA(const int i) {
c(i) = a(i) + b(i);
});
// 输出结果
Kokkos::parallel_for(
N, KOKKOS_LAMBDA(const int i) {
printf("c(%d) = %f\n", i, c(i));
});
return 0;
}
更详细的使用方式可参见https://kokkos.github.io/kokkos-core-wiki/programmingguide.html。
8.2.3.2. RAJA代码示例
在RAJA中,使用 RAJA::kernel 关键字来定义执行模式和操作。以下是使用 RAJA::kernel 进行向量加法计算的代码示例:
#include <iostream>
#include "RAJA/RAJA.hpp"
int main()
{
int N = 10;
double *a = new double[N];
double *b = new double[N];
double *c = new double[N];
// 初始化数据
for (int i = 0; i < N; i++)
{
a[i] = i;
b[i] = 2 * i;
}
// 向量加法
RAJA::forall<RAJA::loop_exec>(0, N, [=](int i)
{ c[i] = a[i] + b[i]; });
// 输出结果
for (int i = 0; i < N; i++)
{
std::cout << "c(" << i << ") = " << c[i] << std::endl;
}
delete[] a;
delete[] b;
delete[] c;
return 0;
}
更详细的使用方式可参见https://readthedocs.org/projects/raja/。
8.3. Kokkos/RAJA与MXMACA平台的适配
沐曦通用GPU提供基于MXMACA HPC SDK的Kokkos与RAJA Docker镜像,包含完整的使用环境。用户下载后可直接在沐曦通用GPU平台上使用。详情参见 10 METAX DockerHub HPC APP。
8.3.1. shuffle相关接口的使用
shfl 相关接口是沐曦通用GPU中的 shuffle 指令,用于在一个Warp内的线程之间交换数据。
shfl 操作具有非常低的延迟和高带宽,并且可以以非常高效的方式实现各种算法。
shfl 操作包括 __shfl_sync()、 __shfl_up_sync()、 __shfl_down_sync()、 __shfl_xor_sync() 等。下图展示了 __shfl_up_sync 的功能。
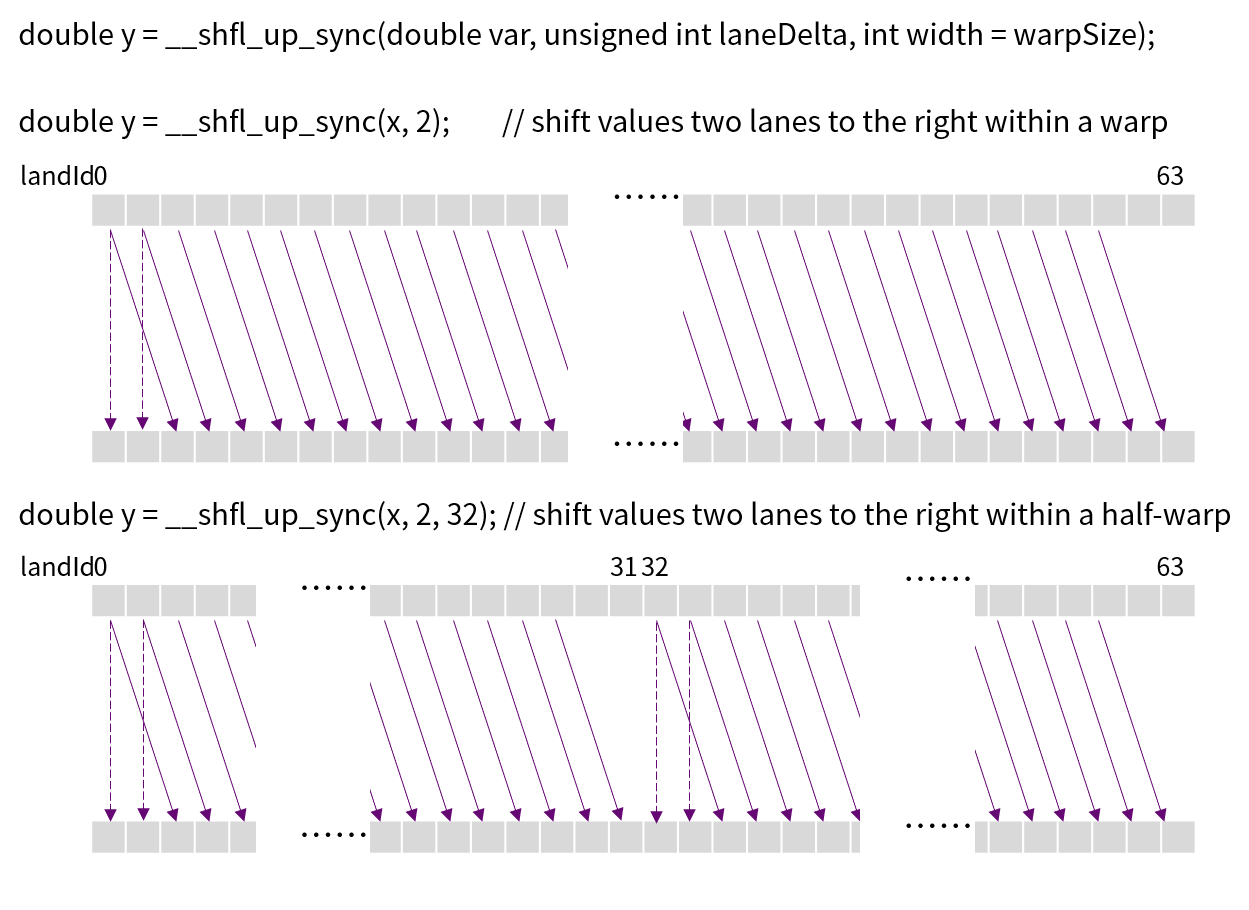
图 8.1 Warp Shuffle Up示意图
以下代码示例演示了如何使用 shfl 操作计算一个Warp内的最大值:
__device__ int warp_max(int val)
{
for (int i = warpSize / 2; i > 0; i /= 2)
{
val = max(val, __shfl_down_sync(0xFFFFFFFF, val, i));
}
return val;
}
__global__ void kernel()
{
int tid = threadIdx.x;
int val = ...; // 计算当前线程的值
int max_val = warp_max(val);
if (tid % warpSize == 0)
{
// 将Warp内的最大值输出到全局内存
atomicMax(&d_max_val, max_val);
}
}
在MXMACA中,同样提供了 shfl 相关的接口,但由于硬件差异,Kokkos中 shfl 相关操作与MXMACA中的 shfl 接口并不匹配,差异点主要为:
warpSize不同。Kokkos中假设GPU warpSize为32位,而沐曦通用GPU的为64位,意味着
shfl操作作用范围不一致,有些算法默认将32位warpSize杂糅到算法逻辑中,此时若直接使用MXMACA的shfl相关接口,在不改变接口的情况下,可能会导致错误结果。此时需要按照实际情况对应调整算法逻辑。mask位宽不同。由于warpSize的不同,MXMACA中的mask位宽为64位,mask的计算需要做对应的修改,同时使用这些mask的地方也需要修改。
为了减少代码的修改和算法的逻辑调整,对于warpSize不同,MXMACA同样也提供了32位mask的 shfl 相关接口,但在实际使用时会将对应的mask复制扩展为64位,同时利用 shfl 操作中的width参数,同样可以达到类似的功能,但在不同Warp中mask存在差异时这种方式会存在问题;而对应于mask位宽不同的情况,可以使用如下的方式进行替换,从而能在不改变算法逻辑的情况下也能得到正确结果。
例如:
__any_sync( 0xffffffffu, predicate)
改为
__any_sync((warpidx & 1) ? 0xffffffff00000000ull : 0x00000000ffffffffull, predicate)
在Kokkos中沐曦通用GPU采用了修改shfl相关算法逻辑,主要的修改片段为:
mask修改
#ifdef __MACACC__ uint64_t mask = __activemask(); uint64_t active = __ballot_sync(mask, 1); uint64_t done_active = 0; #else unsigned int mask = __activemask(); unsigned int active = __ballot_sync(mask, 1); unsigned int done_active = 0; #endif #ifdef __MACACC__ uint64_t mask = blockDim.x == 64 ? 0xffffffffffffffffull : ((1ull << blockDim.x) - 1) << ((threadIdx.y % (64 / blockDim.x)) * blockDim.x); #else unsigned mask = blockDim.x == 32 ? 0xffffffff : ((1 << blockDim.x) - 1) << ((threadIdx.y % (32 / blockDim.x)) * blockDim.x); #endifwarpSize修改
warpsize定义部分为:
#ifdef __MACACC__ static constexpr CudaSpace::size_type WarpSize = 64; static constexpr CudaSpace::size_type WarpIndexMask = 0x003f; static constexpr CudaSpace::size_type WarpIndexShift = 6; #else static constexpr CudaSpace::size_type WarpSize = 32; static constexpr CudaSpace::size_type WarpIndexMask = 0x001f; static constexpr CudaSpace::size_type WarpIndexShift = 5; #endif
对应算法实现部分为:
#ifdef __MACACC__ while (blockDim.x * shift < 32) { const ValueType tmp = shfl_down(result, blockDim.x * shift, 32u); if (threadIdx.y + shift < max_active_thread) reducer.join(&result, &tmp); shift *= 2; } result = shfl(result, 0, 32); #else while (blockDim.x * shift < CudaTraits::WarpSize) { const ValueType tmp = shfl_down(result, blockDim.x * shift, CudaTraits::WarpSize); if (threadIdx.y + shift < max_active_thread) reducer.join(&result, &tmp); shift *= 2; } result = shfl(result, 0, CudaTraits::WarpSize); #endif
在RAJA中采用了适配现有代码逻辑,不更改warpSize的修改方式,而没有使用__activemask()等接口的调用,无需修改代码即可适配现有逻辑。
8.3.2. 汇编指令
Kokkos中有部分计算使用特定厂商的汇编指令编写。对于此类问题,可采用使用已有接口或C++实现替代汇编指令集的方式替代。
在Kokkos和RAJA中需要替换的指令主要为desul开源库中的原子操作部分,部分的修改如下:
Atomic add
asm volatile("red.add" MEMORY_ORDER MEMORY_SCOPE asm_type " [%0],%1;" :: "l" (dest),reg_type(value) : "memory");
替换为
__maca_atomic_fetch_add(dest, value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic min
asm volatile("red.min" MEMORY_ORDER MEMORY_SCOPE asm_type " [%0],%1;" :: "l"(dest),reg_type(value) : "memory");
替换为
__maca_atomic_fetch_min(dest, value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic max
asm volatile("red.max" MEMORY_ORDER MEMORY_SCOPE asm_type " [%0],%1;" :: "l"(dest),reg_type(value) : "memory");
替换为
__maca_atomic_fetch_max(dest, value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic inc
asm volatile("red.inc" MEMORY_ORDER MEMORY_SCOPE asm_type " [%0],%1;" :: "l"(dest),reg_type(value) : "memory");
替换为
unsigned long *uaddr{reinterpret_cast<unsigned long *>(dest)}; unsigned long r{__atomic_load_n(uaddr, MEMORY_ORDER}; unsigned long old; do { old = __atomic_load_n(uaddr, MEMORY_ORDER); if (r != old) { r = old; continue; } r = atomicCAS(uaddr, r, ((r >= 0xffffffffu) ? 0 : (r + 1))); if (r == old) break; } while (true);示例中使用的数据类型为
long,具体数据类型需要按照实际情况替换。Atomic dec
asm volatile("red.dec" MEMORY_ORDER MEMORY_SCOPE asm_type " [%0],%1;" :: "l"(dest),reg_type(value) : "memory");
替换为
unsigned long *uaddr{reinterpret_cast<unsigned long *>(dest)}; unsigned long r{__atomic_load_n(uaddr, MEMORY_ORDER)}; unsigned long old; do { old = __atomic_load_n(uaddr, MEMORY_ORDER); if (r != old) { r = old; continue; } r = atomicCAS(uaddr, r, (((r == 0) || (r > 0xffffffffu)) ? 0xffffffffu : (r - 1))); if (r == old) break; } while (true);示例中使用的数据类型为
long,具体数据类型需要按照实际情况替换。Atomic and
asm volatile("atom.and" MEMORY_ORDER MEMORY_SCOPE ".b32" " %0,[%1],%2;" : "=r"(asm_result) : "l"(dest),"r"(asm_value) : "memory");
替换为
__maca_atomic_fetch_and(dest, asm_value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic or
asm volatile("atom.or" MEMORY_ORDER MEMORY_SCOPE ".b32" " %0,[%1],%2;" : "=r"(asm_result) : "l"(dest),"r"(asm_value) : "memory");
替换为
__maca_atomic_fetch_or(dest, asm_value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic xor
asm volatile("atom.xor" MEMORY_ORDER MEMORY_SCOPE ".b32" " %0,[%1],%2;" : "=r"(asm_result) : "l"(dest),"r"(asm_value) : "memory");
替换为
__maca_atomic_fetch_xor(dest, asm_value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic exchange
asm volatile("atom.exch" MEMORY_ORDER MEMORY_SCOPE ".b64" " %0,[%1],%2;" : "=l"(asm_result) : "l"(dest),"l"(asm_value) : "memory");
替换为
__maca_atomic_exchange(dest, value, MEMORY_ORDER, MEMORY_SCOPE);
Atomic compare exchange
asm volatile("atom.cas" MEMORY_ORDER MEMORY_SCOPE ".b64" " %0,[%1],%2;" : "=l"(asm_result) : "l"(dest),"l"(asm_value) : "memory");
替换为
__maca_atomic_compare_exchange_strong(dest, &compare, value,__ATOMIC_RELAXED, __ATOMIC_RELAXED, MEMORY_SCOPE);