5. OpenMP与OpenACC
5.1. OpenMP
OpenMP是一种基于指令的并行编程标准,支持C、C++和Fortran。现在,OpenMP已支持在GPU上加速,使用非常方便,可以轻松构建多线程程序。
本节介绍在GPU上使用OpenMP的基本指令。更多指令的详细信息,可以参见 OpenMP官网。
5.1.1. 计算构件
OpenMP的大部分功能都是以导语实现,导语基本格式如下:
C/C++
#pragma omp 导语名字 [子语列表]Fortran
!$omp 导语名字 [子语列表]
在C/C++中,可以使用大括号{ }来表示代码块。在Fortran中,代码块可以使用OpenMP导语开始(例如 !$omp target )以及使用与之匹配的导语来结束(例如 !$omp end target )。
由于OpenMP原本是设计用来在CPU上做多线程并行化,在GPU上则增加了target指令用来将指令从CPU卸载(offload)到target(即GPU),并重新分配所需的数据。
target区域中标量都是默认私有的,它们的初始值为进入target区域前的值。而对于数组来说,会涉及到在host和device之间拷贝交换。
5.1.1.1. 代码示例1
向量加法代码示例如下:
C/C++
#define N 128
int main(){
float a = 3.0;
float x[N], y[N];
for (int i = 0; i < N;i++){
x[i] = 2.0;
y[i] = 1.0;
}
#pragma omp target
#pragma omp parallel for
for (int i = 0; i < N;i++){
y[i] = a * x[i] + y[i];
}
return 0;
}
Fortran
program main
implicit none
integer, parameter :: N = 128
real(kind=4) :: x(N), y(N)
integer :: i
real(kind=4) :: a = 3.0
do i = 1, N
x(i) = 2.0
y(i) = 1.0
end do
!$omp target
!$omp parallel do
do i = 1, N
y(i) = a * x(i) + y(i)
end do
!$omp end target
end program
下面列举常用的OpenMP子语句(clause):
shared(var1, var2, …)shared子语指明在循环迭代中变量共享内存。private(var1, var2, …)private子语指明循环迭代中在每个线程上为变量创建一个副本。collapse(n)collapse子语用来指定在多少层上与Loop构件管理的循环进行并行化。n默认为1。reduction(operator:variable)reduction和private一样,循环迭代中在每个线程上为变量创建一个副本,但在并行区域结束后对这些私有的副本进行一个归约运算。归约运算支持+、*、min、max等运算符。
5.1.1.2. 代码示例2
求和归约运算代码示例如下:
C/C++
#define N 100
int main(){
int x[N], s;
for (int i = 0; i < N;i++){
x[i] = i + 1;
}
s = 0;
#pragma omp target map(tofrom:s)
#pragma omp parallel for reduction(+:s)
for (int i = 0; i < N;i++){
s = s + x[i];
}
return 0;
}
Fortran
program main
implicit none
integer, parameter :: N = 100
integer :: x(N)
integer :: i, s
do i = 1, N
x(i) = i
end do
s = 0
!$omp target map(tofrom:s)
!$omp parallel do reduction(+:s)
do i = 1, N
s = s + x(i)
end do
!$omp end parallel do
!$omp end target
end program
5.1.2. 数据管理
5.1.1 计算构件 中示例没有标明host和device之间的数据传输,OpenMP会自动在并行区域前后隐式地添加host和device之间的数据传输。 我们也可以使用map语句来显式地控制数据传输以进行更好的优化。
常用的数据传输子语句如下:
tofrom在device上创建内存空间,在并行区域前拷贝数据到device上初始化,在并行区域结束后将结果拷贝回来,并释放device上的空间。
to在device上创建内存空间,在并行区域前拷贝数据到device上初始化,在并行区域结束并释放device上的空间,但不拷贝结果。
from在device上创建内存空间,不进行初始化,在并行区域结束后将结果拷贝回来,并释放device上的空间。
alloc在device上创建内存空间参与计算,并在结束时释放。不进行数据传输。
5.1.2.1. 代码示例
利用中间变量计算y数组,并且拷贝回host上:
C/C++
#pragma omp target data \
map(alloc:x[0 : N]) \
map(to:y[0 : N])
{
#pragma omp parallel for
for (i=0; i<N; i++)
{
y[i] = 0.0f;
x[i] = (float)(i+1);
}
#pragma omp parallel for
for (i=0; i<N; i++)
{
y[i] = 2.0f * x[i] + y[i];
}
}
Fortran
!$omp target data &
!$omp map(alloc:x(1:N)) &
!$omp map(to:y(1:N))
!$omp parallel do
do i=1,N
y(i) = 0
x(i) = i
end do
!$omp end parallel do
!$omp parallel do
do i=1,N
y(i) = 2.0 * x(i) + y(i)
end do
!$omp end parallel do
!$omp end target data
5.2. OpenACC
OpenACC是一种简化异构CPU/GPU系统的并行编程标准。程序员可以在C、C++、Fortran源代码中添加注释来确定加速的区域。 使用OpenACC可以有效的帮助工程师把代码移植到各种异构HPC硬件平台上。与更加底层的编程模型相比,使用OpenACC的编程工作量大大减少。
OpenACC核心支持将计算和数据从主机设备加载到加速器设备。 这些设备可能相同,例如纯CPU并行加速;也可能不同,例如CPU、GPU异构体系。在这两个设备具有独立的内存空间时,OpenACC编译器将分析代码,并处理主机和设备间的数据传输。 OpenACC抽象加速模型如下图所示。
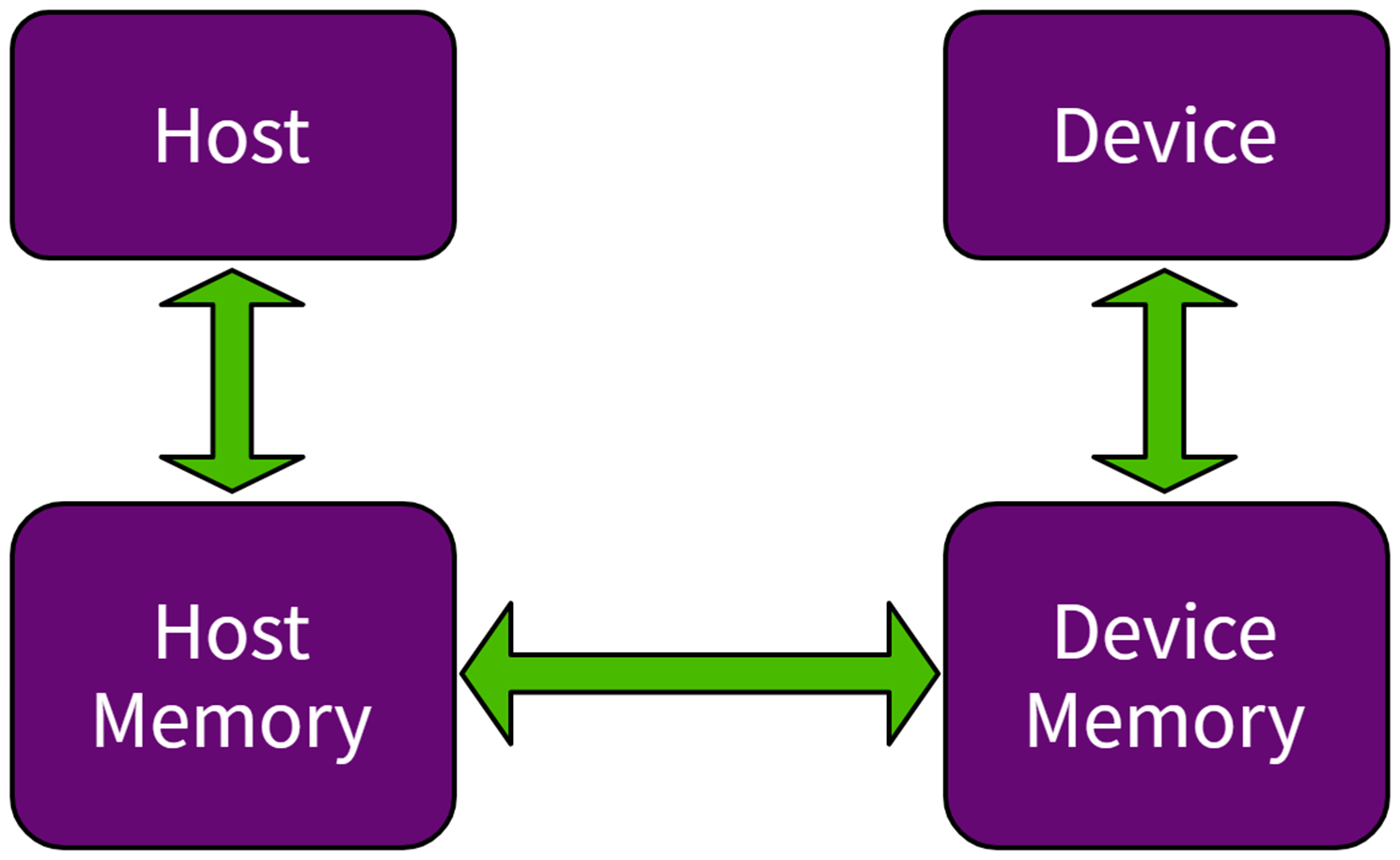
图 5.1 OpenACC 抽象加速模型
本节介绍在GPU上使用OpenACC编程模型的基本方法。更多详细信息,可参见 OpenACC官网。
5.2.1. 计算构件
OpenACC的大部分功能都是以导语实现,导语基本格式如下:
C/C++
#pragma acc 导语名字 [子语列表]Fortran
!$acc 导语名字 [子语列表]
一些OpenACC导语适用于结构化的代码块,而另一些是可执行的语句。在C/C++ 中,可以使用大括号 { } 来表示代码块。
在Fortran中,代码块可以使用OpenACC导语开始(例如 !$acc kernels )以及使用与之匹配的导语来结束(例如 !$acc end kernels )。
OpenACC有两个计算构件Kernels和Parallel,用来将循环并行化。 两个构件的目标是一样的。Kernels构件给了编译器最大的自由在目标加速器上并行和优化代码,但也依赖于编译器的优化能力。 Parallel构件则由程序员来确保并行策略的正确性,同时也能更加精细的控制并行优化方案。
5.2.1.1. Kernels构件
以下代码示例展示了向量相加的并行化。在代码块前增加acc导语,告诉编译器将该循环并行化,并映射成一个GPU上的核函数。 线程网格维数grid size、线程块维数block size等参数由编译器自行选择。并且自动增加host和device端数据的互相拷贝。 如果没有使用async子语句,Kernels区域结束时会有隐式的设备同步语句:在所有核函数执行完毕前,host线程不再继续执行。
C/C++
#define N 128
int main(){
float a = 3.0;
float x[N], y[N];
for (int i = 0; i < N; i++){
x[i] = 2.0;
y[i] = 1.0;
}
#pragma acc kernels
for (int i = 0; i < N; i++){
y[i] = a * x[i] + y[i];
}
return 0;
}
Fortran
program main
implicit none
integer, parameter :: N = 128
real(kind=4) :: x(N), y(N)
integer :: i
real(kind=4) :: a = 3.0
do i = 1, N
x(i) = 2.0
y(i) = 1.0
end do
!$acc kernels
do i = 1, N
y(i) = a * x(i) + y(i)
end do
!$acc end kernels
end program
5.2.1.2. Parallel构件
和Kernels构件相同,如果没有使用async子语句,Parallel区域结束时会有一个隐式的设备同步语句:在所有核函数执行完毕前,host线程不再继续执行。
C/C++
#define N 128
int main(){
float a = 3.0;
float x[N], y[N];
for (int i = 0; i < N;i++){
x[i] = 2.0;
y[i] = 1.0;
}
#pragma acc parallel loop
for (int i = 0; i < N;i++){
y[i] = a * x[i] + y[i];
}
return 0;
}
Fortran
program main
implicit none
integer, parameter :: N = 128
real(kind=4) :: x(N), y(N)
integer :: i
real(kind=4) :: a = 3.0
do i = 1, N
x(i) = 2.0
y(i) = 1.0
end do
!$acc parallel loop
do i = 1, N
y(i) = a * x(i) + y(i)
end do
!$acc end parallel
end program
5.2.1.3. Loop构件
Loop导语可以告诉编译器哪些循环需要并行化,以及以什么方式并行化,从而达到更高效的优化。 Loop导语可以用于Kernels、Parallel构件中。下面列举Loop常见的几种子语句:
private(var1, var2, …)private子语指明在循环迭代中为变量列表创建一个副本。循环迭代变量默认是private。 循环中使用的标量默认都是first private,每一个循环迭代都是进行私有的拷贝,并且使用进入并行区域前的数值进行初始化。C/C++中循环内定义的所有变量都默认是private。collapse(n)collapse子语用来指定在多少层上与Loop构件管理的循环进行并行化。n默认为1。reduction(operator:variable)reduction和private一样,在循环迭代中为变量创建一个副本,但在并行区域结束后对这些私有的副本进行一个归约运算。 归约运算支持+、*、min、max、&、|、%、&&、||等运算符。
求和归约Loop代码示例如下:
C/C++
#define N 100
int main(){
int x[N], s;
for (int i = 0; i < N;i++){
x[i] = i + 1;
}
s = 0;
#pragma acc parallel loop reduction(+:s)
for (int i = 0; i < N;i++){
s = s + x[i];
}
return 0;
}
Fortran
program main
implicit none
integer, parameter :: N = 100
integer :: x(N)
integer :: i, s
do i = 1, N
x(i) = i
end do
s = 0
!$acc parallel loop reduction(+:s)
do i = 1, N
s = s + x(i)
end do
!$acc end parallel
end program
OpenACC定义了3个层次的并行,gang、worker和vector。如下图所示:
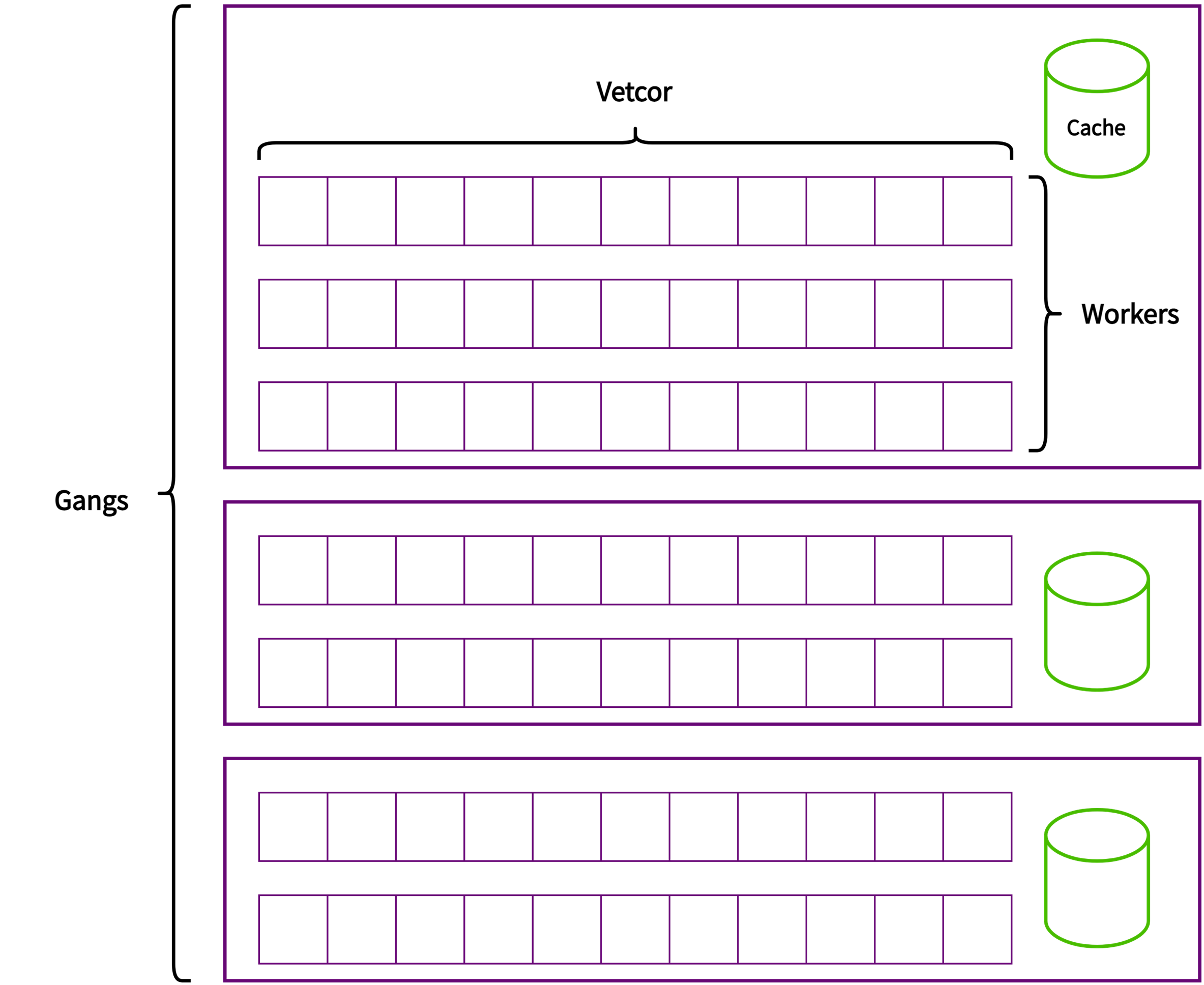
图 5.2 OpenACC 3层并行
用户可以使用 num_gangs、 num_workers、 vector_length 子语句来控制gang数量、worker数量、vector长度。
以下代码示例指定了vector的长度为128。如果不显式指定,则编译器会自动分配。 OpenACC术语中的gang、worker、vector都是一维的,类比来看,gang对应block,worker数量对应一个block中y方向上维度大小,vector长度对应一个block中x方向维度大小。
C/C++
#pragma acc parallel loop gang \
vector_length(128)
for (i = 0; i < N;i++)
#pragma acc loop vector
for (j = 0; j < M;j++)
...
Fortran
!$acc parallel loop gang &
!$acc vector_length(128)
do i=1,N
!$acc parallel loop vector
do j = 1,M
...
5.2.2. 数据管理
5.2.1 计算构件 中示例没有显式的数据传输,OpenACC会自动在并行区域前后隐式地添加host和device之间的数据传输。我们也可以使用data语句来显式地控制数据传输以进行更好的优化。
常用的数据传输子语句如下:
copy在device上创建内存空间,在并行区域前拷贝数据到device上初始化,在并行区域结束后将结果拷贝回来,并释放device上的空间。
copyin在device上创建内存空间,在并行区域前拷贝数据到device上初始化,在并行区域结束并释放device上的空间,但不拷贝结果。
copyout在device上创建内存空间,不进行初始化,在并行区域结束后将结果拷贝回来,并释放device上的空间。
create在device上创建内存空间参与计算,并在结束时释放。不进行数据传输。
present表示数据已经在device上,如果不在会报错。常用于更高层函数中已经进行数据管理的情况下。
5.2.2.1. 代码示例
利用中间变量计算y数组,并且拷贝回host上:
C/C++
#pragma acc data create(x[0:N]) \
copyout(y[0:N])
{
#pragma acc parallel loop
for (i=0; i<N; i++)
{
y[i] = 0.0f;
x[i] = (float)(i+1);
}
#pragma acc parallel loop
for (i=0; i<N; i++)
{
y[i] = 2.0f * x[i] + y[i];
}
}
Fortran
!$acc data create(x(1:N)) &
!$acc copyout(y(1:N))
!$acc parallel loop
do i=1,N
y(i) = 0
x(i) = i
end do
!$acc end parallel
!$acc parallel loop
do i=1,N
y(i) = 2.0 * x(i) + y(i)
end do
!$acc end parallel
!$acc end data