7. MPI通讯协议
MPI(Message Passive Interface,消息传递接口)是一个为并行计算设计的通讯协议标准。 该标准定义了一组具有可移植性的接口。MPI的目标是高性能、大规模、可移植。MPI是非常流行的、高性能计算的主要模型之一,具有很好的可移植性、扩展性,并拥有完备的异步通讯功能。
7.1. 常用API
函数 |
功能 |
|---|---|
MPI_Comm_rank |
获取当前进程的秩 |
MPI_Finalize |
终止MPI,释放MPI的资源 |
MPI_Init |
环境初始化 |
MPI_Comm_size |
获取MPI进程数量 |
MPI_Send/MPI_Recv |
阻塞发送/接收 |
MPI_Isend/MPI_Irecv |
非阻塞发送/接收,是MPI异步消息 |
MPI_Bcast/MPI_Ibcast |
阻塞广播/非阻塞广播 |
MPI_Gather/MPI_Allgather |
收集/全收集 |
MPI_Scatter |
发散 |
MPI_Reduce/MPI_Allreduce |
归约/全归约 |
MPI_Alltoall |
所有进程互换数据 |
MPI_Barrier |
栅栏函数 |
7.2. 使用示例
用户通常需要根据使用环境,选择合适的并行计算模型。在单机多设备环境中,可以使用MPI、OpenMP、MCCL编程模型,进行并行程序设计。 在多台主机,每台主机只有1个设备的环境中,适合使用MPI、MCCL编程模型,进行并行程序设计。 在多机多设备环境中,可以使用MPI(每个MPI进程控制1个设备)、MPI+OpenMP(每个MPI进程控制1台主机,通过OpenMP调用这台主机上的多个设备)、MCCL编程模型,进行并行程序设计。 如图 7.1 所示,MPI通用传输模型描述了数据是如何在不同进程中进行运算和传输的。
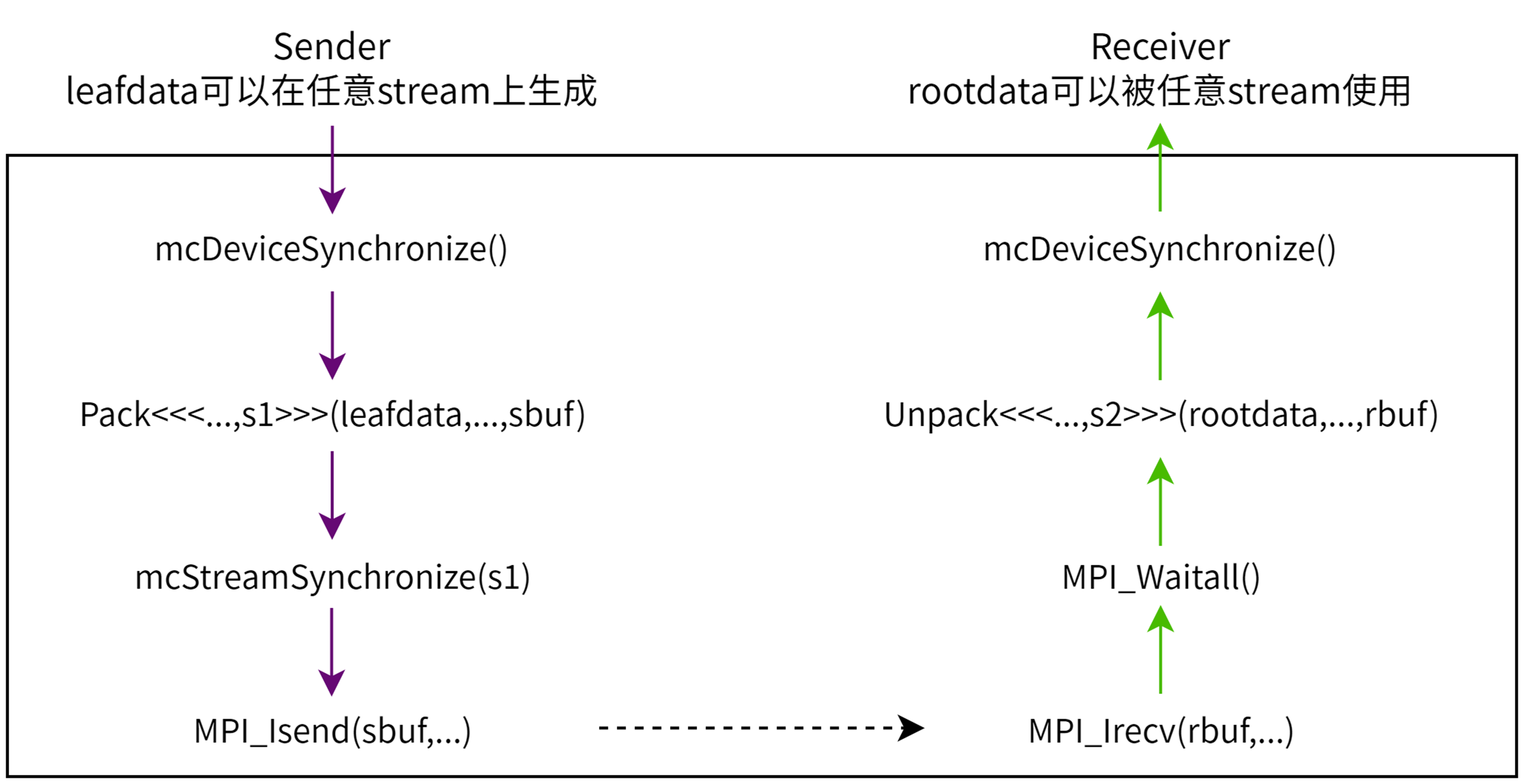
图 7.1 MPI通用传输模型
MPI异步传输代码示例如下,该示例演示了在满足硬件条件时,MPI支持直接传输设备显存。
int myRank, nRanks;
int dev = 0, nDevs;
mcGetDeviceCount(&ndevs);
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myRank);
MPI_Comm_size(MPI_COMM_WORLD, &nRanks);
dev = myRank % nDevs; // Each process's device id.
// picking a GPU based on localRank, allocate device buffers
mcSetDevice(dev);
mcMalloc((void **)&d_sendbuff, size * sizeof(int));
mcMalloc((void **)&d_recvbuff, size * sizeof(int));
mcStreamCreate(&s);
int *sendbuff = d_sendbuff;
int *recvbuff = d_recvbuff;
#ifndef GPU_AWARE_MPI
// malloc host data
int *h_sendbuff = (int *)malloc(size * sizeof(int));
int *h_recvbuff = (int *)malloc(size * sizeof(int));
sendbuff = h_sendbuff;
recvbuff = h_recvbuff;
#endif
// prepare send buff
Kernel_gather<<<grid, block, 0, s>>>(d_sendbuff[, other_args]);
#ifndef GPU_AWARE_MPI
mcMemcpyAsync(sendbuff, d_sendbuff, size * sizeof(int), mcMemcpyDeviceToHost, s);
#endif
// exchange data
MPI_Irecv(recvbuff, nrecv, MPI_INT, neighbor, tag, MPI_COMM_WORLD, recv_request);
// stream synchronize before MPI_Isend
mcStreamSynchronize(s);
MPI_Isend(sendbuff, nsend, MPI_INT, neighbor, tag, MPI_COMM_WORLD, send_request);
// obtain recvbuff
MPI_Waitall(neighbors, recv_request, MPI_STATUS_IGNORE);
MPI_Waitall(neighbors, send_request, MPI_STATUS_IGNORE);
#ifndef GPU_AWARE_MPI
mcMemcpyAsync(d_recvbuff, recvbuff, size * sizeof(int), mcMemcpyHostToDevice, s);
#endif
myKenel<<<grid, block, 0, s>>>(d_recvbuff[, result]);
// cleanup
#ifndef GPU_AWARE_MPI
Free(h_sendbuff);
Free(h_recvbuff);
#endif
mcFree(d_sendbuff);
mcFree(d_recvbuff);
// mpi finalize
MPI_Finalize();
编译MPI程序
MPI程序的编译,通常只需要编译器在链接阶段加上 -lompi 等编译选项即可。
$ mxcc a.maca -lompi
运行MPI程序
$ mpirun -np 2 ./a.out
或在Slurm集群环境下,可使用srun运行程序,参见 2.3 基于Slurm集群的容器化应用。
MPI程序性能分析
使用GPU加速计算的MPI程序,可以通过观察MPI数据传输与GPU内核计算是否重合,来推断程序性能是否有优化空间。 如下图所示,(a)中在进行核函数计算时,也同时进行MPI数据的收发;(b)中的MPI通讯与核函数计算在时间上并没有重叠。通讯与计算重叠后,程序运行效率大大提高。
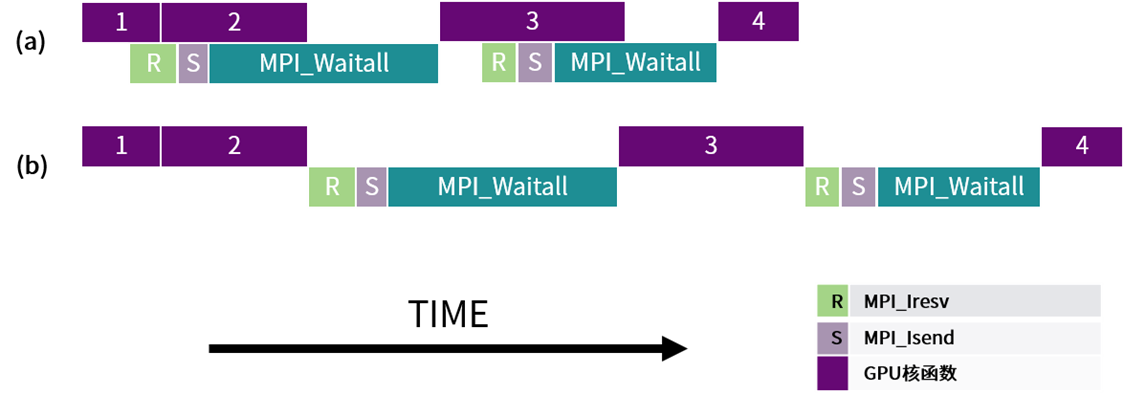
图 7.2 MPI传输与GPU计算